

An automated approach to identify sarcasm in low-resource language
- PMID: 39637015
- PMCID: PMC11620596
- DOI: 10.1371/journal.pone.0307186
An automated approach to identify sarcasm in low-resource language
Abstract
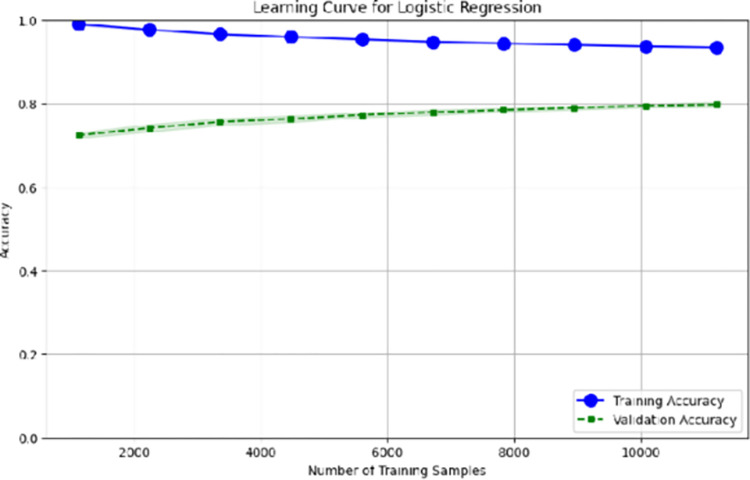
Sarcasm detection has emerged due to its applicability in natural language processing (NLP) but lacks substantial exploration in low-resource languages like Urdu, Arabic, Pashto, and Roman-Urdu. While fewer studies identifying sarcasm have focused on low-resource languages, most of the work is in English. This research addresses the gap by exploring the efficacy of diverse machine learning (ML) algorithms in identifying sarcasm in Urdu. The scarcity of annotated datasets for low-resource language becomes a challenge. To overcome the challenge, we curated and released a comparatively large dataset named Urdu Sarcastic Tweets (UST) Dataset, comprising user-generated comments from [Formula: see text] (former Twitter). Automatic sarcasm detection in text involves using computational methods to determine if a given statement is intended to be sarcastic. However, this task is challenging due to the influence of the user's behavior and attitude and their expression of emotions. To address this challenge, we employ various baseline ML classifiers to evaluate their effectiveness in detecting sarcasm in low-resource languages. The primary models evaluated in this study are support vector machine (SVM), decision tree (DT), K-Nearest Neighbor Classifier (K-NN), linear regression (LR), random forest (RF), Naïve Bayes (NB), and XGBoost. Our study's assessment involved validating the performance of these ML classifiers on two distinct datasets-the Tanz-Indicator and the UST dataset. The SVM classifier consistently outperformed other ML models with an accuracy of 0.85 across various experimental setups. This research underscores the importance of tailored sarcasm detection approaches to accommodate specific linguistic characteristics in low-resource languages, paving the way for future investigations. By providing open access to the UST dataset, we encourage its use as a benchmark for sarcasm detection research in similar linguistic contexts.
Copyright: © 2024 Khan et al. This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures





References
-
- Gibbs RW. Irony in talk among friends. Metaphor and symbol. 2000;15(1–2):5–27.
-
- Huang C, Han Z, Li M, Wang X, Zhao WJAJoET. Sentiment evolution with interaction levels in blended learning environments: Using learning analytics and epistemic network analysis. 2021;37(2):81–95.
-
- Davidov D, Tsur O, Rappoport A, editors. Semi-supervised recognition of sarcasm in Twitter and Amazon. Proceedings of the fourteenth conference on computational natural language learning; 2010.
-
- Joshi A, Sharma V, Bhattacharyya P, editors. Harnessing context incongruity for sarcasm detection. Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers); 2015.
MeSH terms
LinkOut - more resources
Full Text Sources
Miscellaneous
