

Road surface semantic segmentation for autonomous driving
- PMID: 39650429
- PMCID: PMC11623202
- DOI: 10.7717/peerj-cs.2250
Road surface semantic segmentation for autonomous driving
Abstract
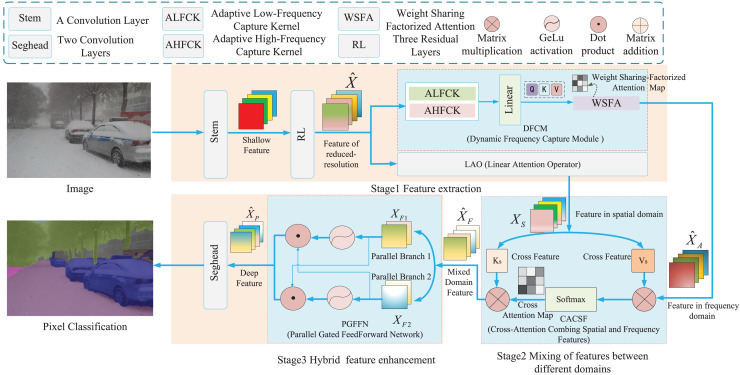
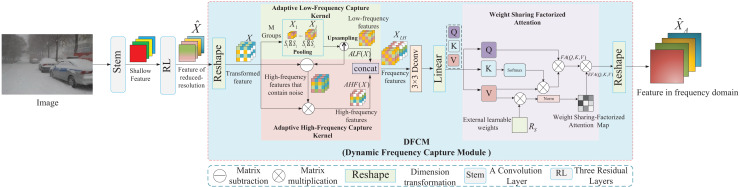
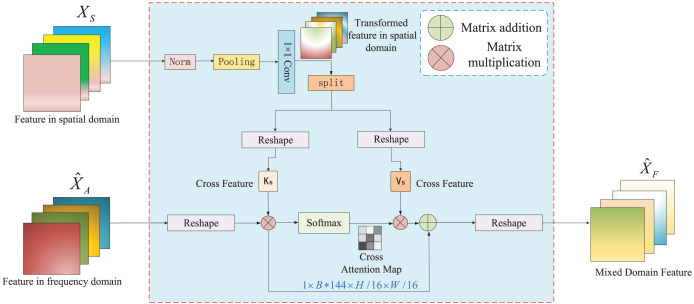
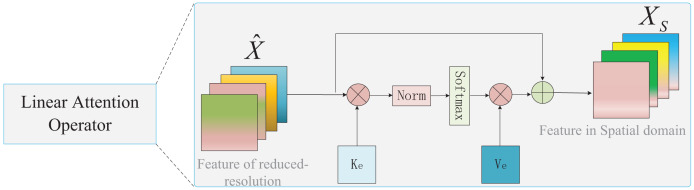
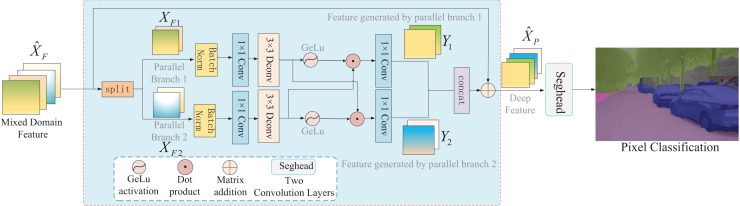
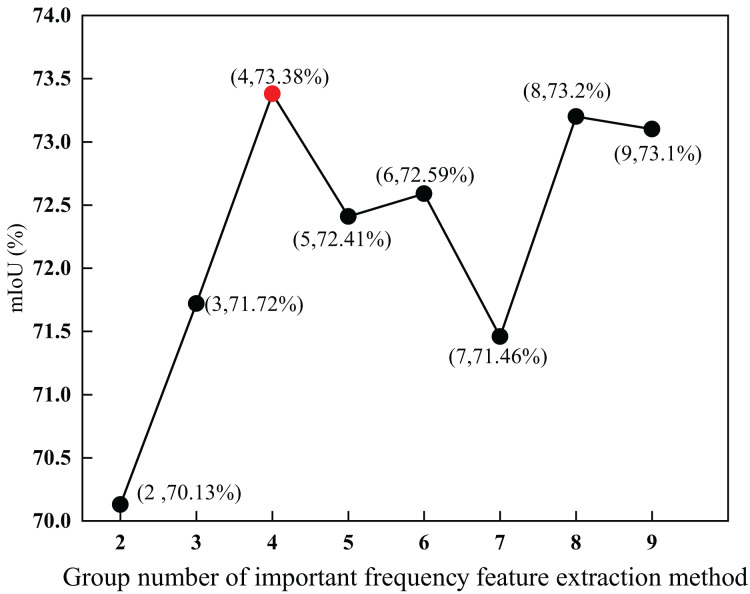
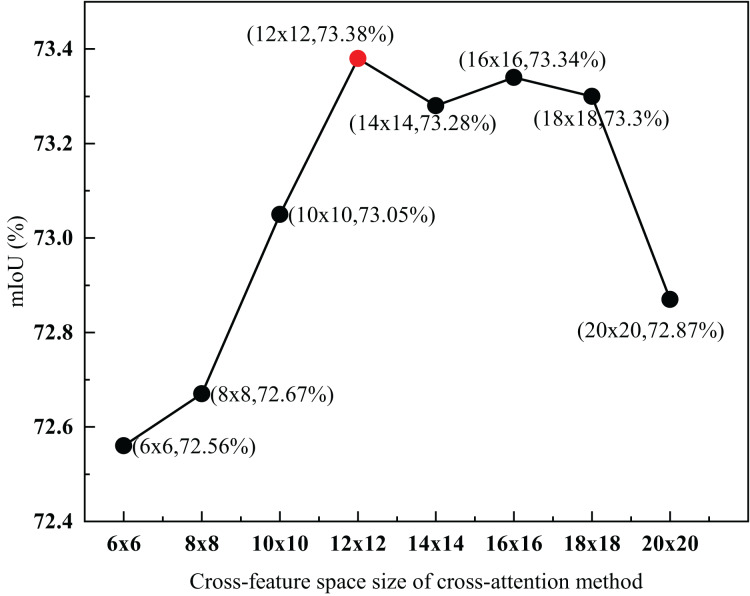
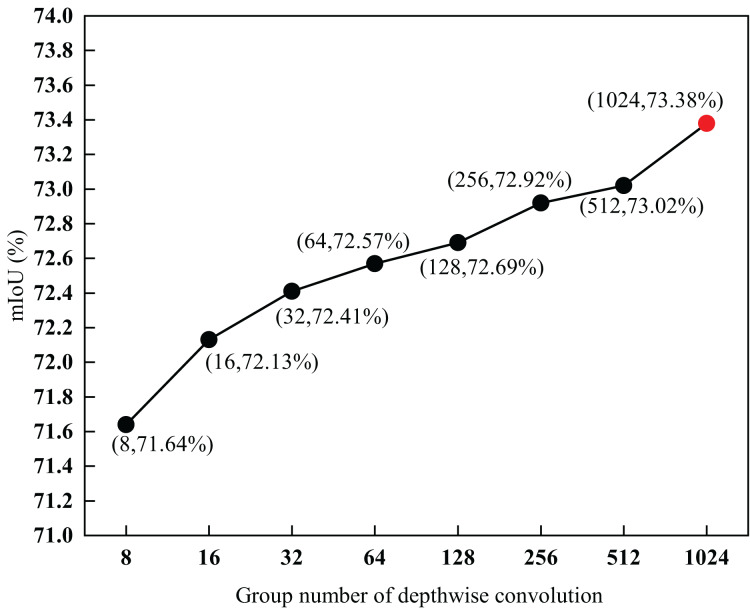
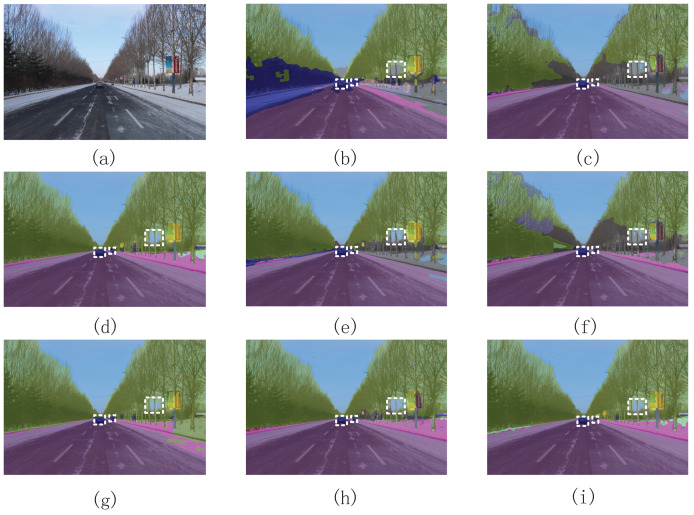
Although semantic segmentation is widely employed in autonomous driving, its performance in segmenting road surfaces falls short in complex traffic environments. This study proposes a frequency-based semantic segmentation with a transformer (FSSFormer) based on the sensitivity of semantic segmentation to frequency information. Specifically, we propose a weight-sharing factorized attention to select important frequency features that can improve the segmentation performance of overlapping targets. Moreover, to address boundary information loss, we used a cross-attention method combining spatial and frequency features to obtain further detailed pixel information. To improve the segmentation accuracy in complex road scenarios, we adopted a parallel-gated feedforward network segmentation method to encode the position information. Extensive experiments demonstrate that the mIoU of FSSFormer increased by 2% compared with existing segmentation methods on the Cityscapes dataset.
Keywords: Cross-attention combining spatial and frequency features; Parallel-gated feedforward network; Semantic segmentation; Transformer; Weight-sharing factorized attention.
© 2024 Zhao et al.
Conflict of interest statement
Rui Wang is employed by Dongfeng District People’s Court.
Figures

References
-
- Boykov YY, Jolly M-P. Interactive graph cuts for optimal boundary and region segmentation of objects in nd images. Proceedings Eighth IEEE International Conference on Computer Vision. ICCV 2001; Piscataway: IEEE; 2001. pp. 105–112.
-
- Caesar H, Uijlings J, Ferrari V. COCO-Stuff: thing and stuff classes in context. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; Piscataway: IEEE; 2018. pp. 1209–1218.
-
- Chen C-FR, Fan Q, Panda R. CrossViT: cross-attention multi-scale vision transformer for image classification. Proceedings of the IEEE/CVF International Conference on Computer Vision; Piscataway: IEEE; 2021. pp. 357–366.
-
- Chen L-C, Papandreou G, Schroff F, Adam H. Rethinking atrous convolution for semantic image segmentation. 2017. ArXiv preprint. - DOI
LinkOut - more resources
Full Text Sources