

How human-AI feedback loops alter human perceptual, emotional and social judgements
- PMID: 39695250
- PMCID: PMC11860214
- DOI: 10.1038/s41562-024-02077-2
How human-AI feedback loops alter human perceptual, emotional and social judgements
Abstract
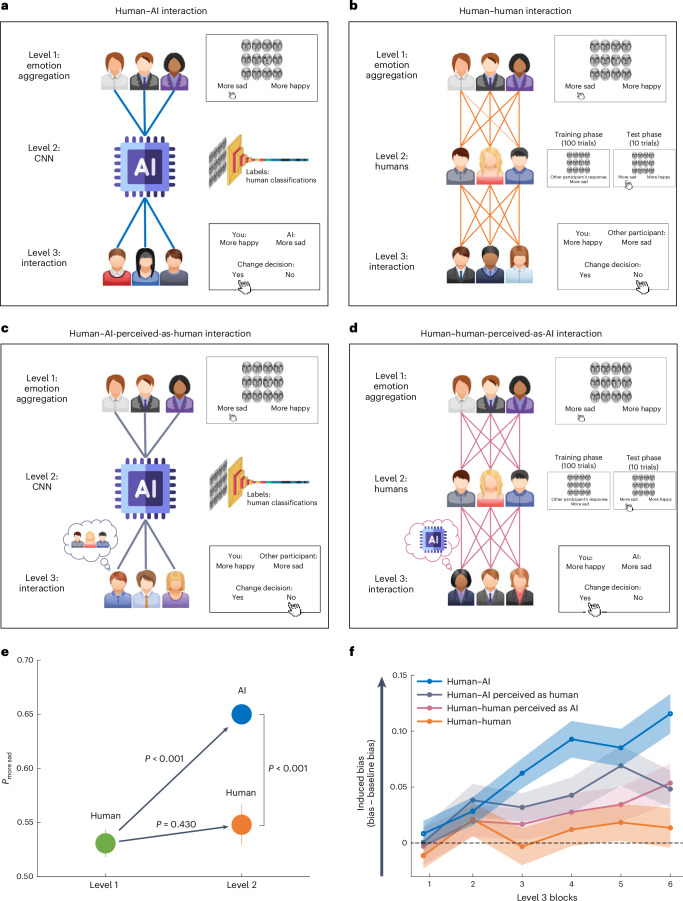
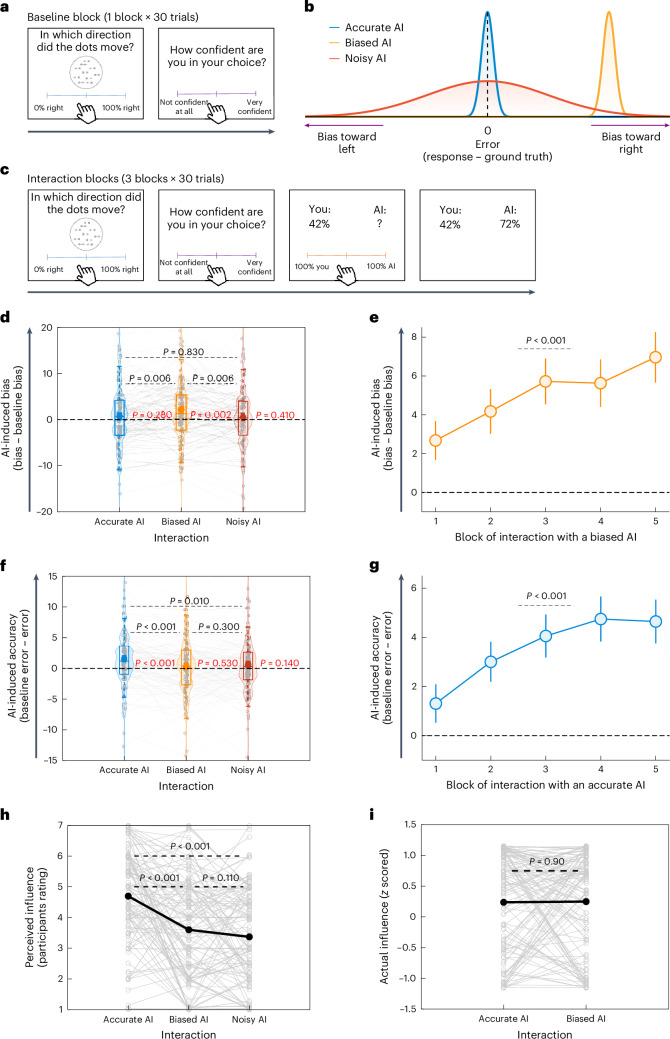
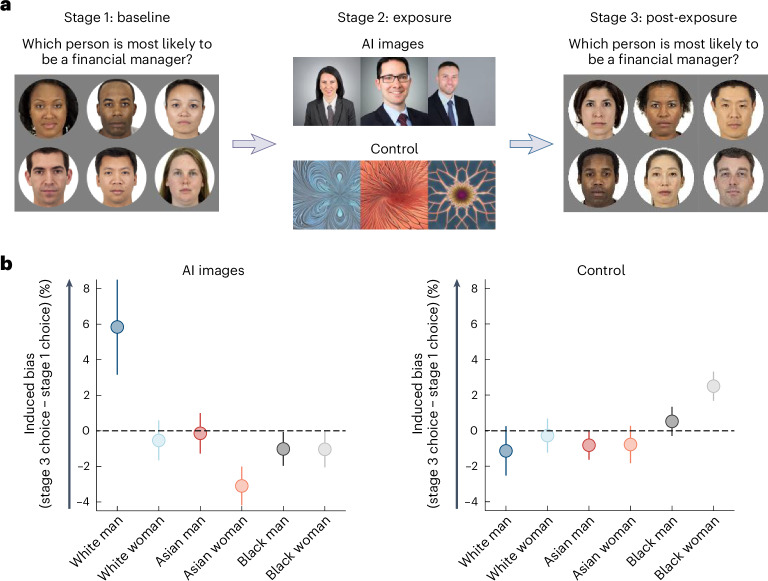
Artificial intelligence (AI) technologies are rapidly advancing, enhancing human capabilities across various fields spanning from finance to medicine. Despite their numerous advantages, AI systems can exhibit biased judgements in domains ranging from perception to emotion. Here, in a series of experiments (n = 1,401 participants), we reveal a feedback loop where human-AI interactions alter processes underlying human perceptual, emotional and social judgements, subsequently amplifying biases in humans. This amplification is significantly greater than that observed in interactions between humans, due to both the tendency of AI systems to amplify biases and the way humans perceive AI systems. Participants are often unaware of the extent of the AI's influence, rendering them more susceptible to it. These findings uncover a mechanism wherein AI systems amplify biases, which are further internalized by humans, triggering a snowball effect where small errors in judgement escalate into much larger ones.
© 2024. The Author(s).
Conflict of interest statement
Competing interests: The authors declare no competing interests.
Figures
Similar articles
-
Unconscious Other's Impression Changer: A Method to Manipulate Cognitive Biases That Subtly Change Others' Impressions Positively/Negatively by Making AI Bias in Emotion Estimation AI.Sensors (Basel). 2022 Dec 17;22(24):9961. doi: 10.3390/s22249961. Sensors (Basel). 2022. PMID: 36560330 Free PMC article.
-
How people reason with counterfactual and causal explanations for Artificial Intelligence decisions in familiar and unfamiliar domains.Mem Cognit. 2023 Oct;51(7):1481-1496. doi: 10.3758/s13421-023-01407-5. Epub 2023 Mar 24. Mem Cognit. 2023. PMID: 36964302 Free PMC article.
-
Distraction from emotional information reduces biased judgements.Cogn Emot. 2016;30(4):638-53. doi: 10.1080/02699931.2015.1020767. Epub 2015 Mar 19. Cogn Emot. 2016. PMID: 25787937
-
AI contextual information shapes moral and aesthetic judgments of AI-generated visual art.Cognition. 2025 Apr;257:106063. doi: 10.1016/j.cognition.2025.106063. Epub 2025 Jan 16. Cognition. 2025. PMID: 39823962 Review.
-
AI-induced hyper-learning in humans.Curr Opin Psychol. 2024 Dec;60:101900. doi: 10.1016/j.copsyc.2024.101900. Epub 2024 Sep 11. Curr Opin Psychol. 2024. PMID: 39348730 Review.
Cited by
-
Opportunities and considerations for using artificial intelligence in bioinformatics education.Bioinform Adv. 2025 Sep 1;5(1):vbaf169. doi: 10.1093/bioadv/vbaf169. eCollection 2025. Bioinform Adv. 2025. PMID: 40900913 Free PMC article.
-
Utilization of Explainable Artificial Intelligence (XAI)-Powered Computer-Aided Detection (CAD) System on Chest X-Ray Abnormalities in Health Check-Ups.Yonago Acta Med. 2025 Jul 23;68(3):180-186. doi: 10.33160/yam.2025.08.002. eCollection 2025 Aug. Yonago Acta Med. 2025. PMID: 40810036 Free PMC article.
-
Generative artificial intelligence-mediated confirmation bias in health information seeking.Ann N Y Acad Sci. 2025 Aug;1550(1):23-36. doi: 10.1111/nyas.15413. Epub 2025 Jul 27. Ann N Y Acad Sci. 2025. PMID: 40716036 Free PMC article. Review.
-
Intuitive judgements towards artificial intelligence verdicts of moral transgressions.Br J Soc Psychol. 2025 Jul;64(3):e12908. doi: 10.1111/bjso.12908. Br J Soc Psychol. 2025. PMID: 40448478 Free PMC article.
References
-
- Centola, D. The spread of behavior in an online social network experiment. Science329, 1194–1197 (2010). - PubMed
-
- Zhou, B. et al. Realistic modelling of information spread using peer-to-peer diffusion patterns. Nat. Hum. Behav.4, 1198–1207 (2020). - PubMed
-
- Kahneman, D., Sibony, O. & Sunstein, C. R. Noise: A Flaw in Human Judgment (Hachette UK, 2021).
-
- Araujo, T., Helberger, N., Kruikemeier, S. & de Vreese, C. H.In AI we trust? Perceptions about automated decision-making by artificial intelligence. AI Soc.35, 611–623 (2020).
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
