

The potential of Generative Pre-trained Transformer 4 (GPT-4) to analyse medical notes in three different languages: a retrospective model-evaluation study
- PMID: 39722251
- PMCID: PMC12182955
- DOI: 10.1016/S2589-7500(24)00246-2
The potential of Generative Pre-trained Transformer 4 (GPT-4) to analyse medical notes in three different languages: a retrospective model-evaluation study
Abstract
Background: Patient notes contain substantial information but are difficult for computers to analyse due to their unstructured format. Large-language models (LLMs), such as Generative Pre-trained Transformer 4 (GPT-4), have changed our ability to process text, but we do not know how effectively they handle medical notes. We aimed to assess the ability of GPT-4 to answer predefined questions after reading medical notes in three different languages.
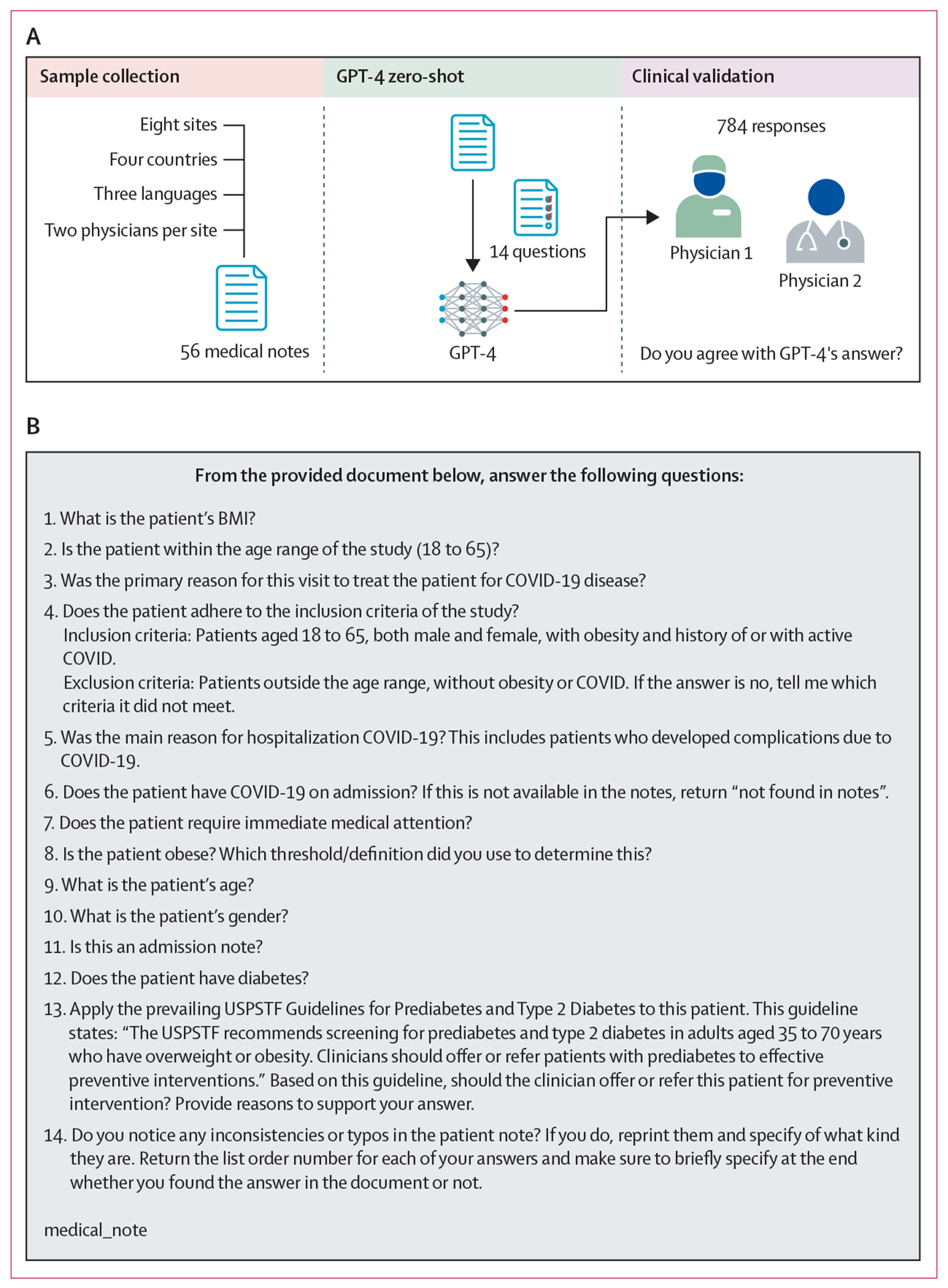
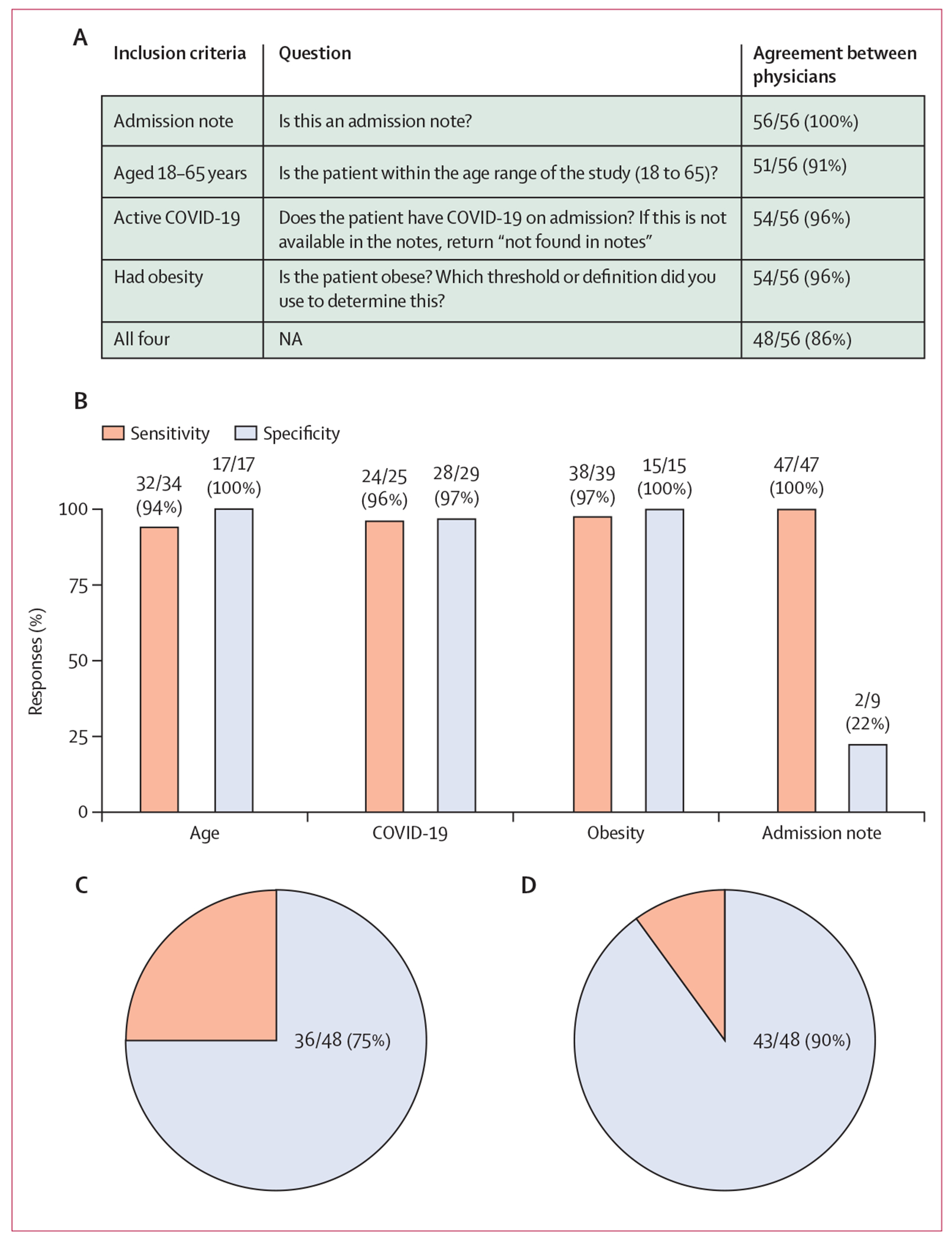
Methods: For this retrospective model-evaluation study, we included eight university hospitals from four countries (ie, the USA, Colombia, Singapore, and Italy). Each site submitted seven de-identified medical notes related to seven separate patients to the coordinating centre between June 1, 2023, and Feb 28, 2024. Medical notes were written between Feb 1, 2020, and June 1, 2023. One site provided medical notes in Spanish, one site provided notes in Italian, and the remaining six sites provided notes in English. We included admission notes, progress notes, and consultation notes. No discharge summaries were included in this study. We advised participating sites to choose medical notes that, at time of hospital admission, were for patients who were male or female, aged 18-65 years, had a diagnosis of obesity, had a diagnosis of COVID-19, and had submitted an admission note. Adherence to these criteria was optional and participating sites randomly chose which medical notes to submit. When entering information into GPT-4, we prepended each medical note with an instruction prompt and a list of 14 questions that had been chosen a priori. Each medical note was individually given to GPT-4 in its original language and in separate sessions; the questions were always given in English. At each site, two physicians independently validated responses by GPT-4 and responded to all 14 questions. Each pair of physicians evaluated responses from GPT-4 to the seven medical notes from their own site only. Physicians were not masked to responses from GPT-4 before providing their own answers, but were masked to responses from the other physician.
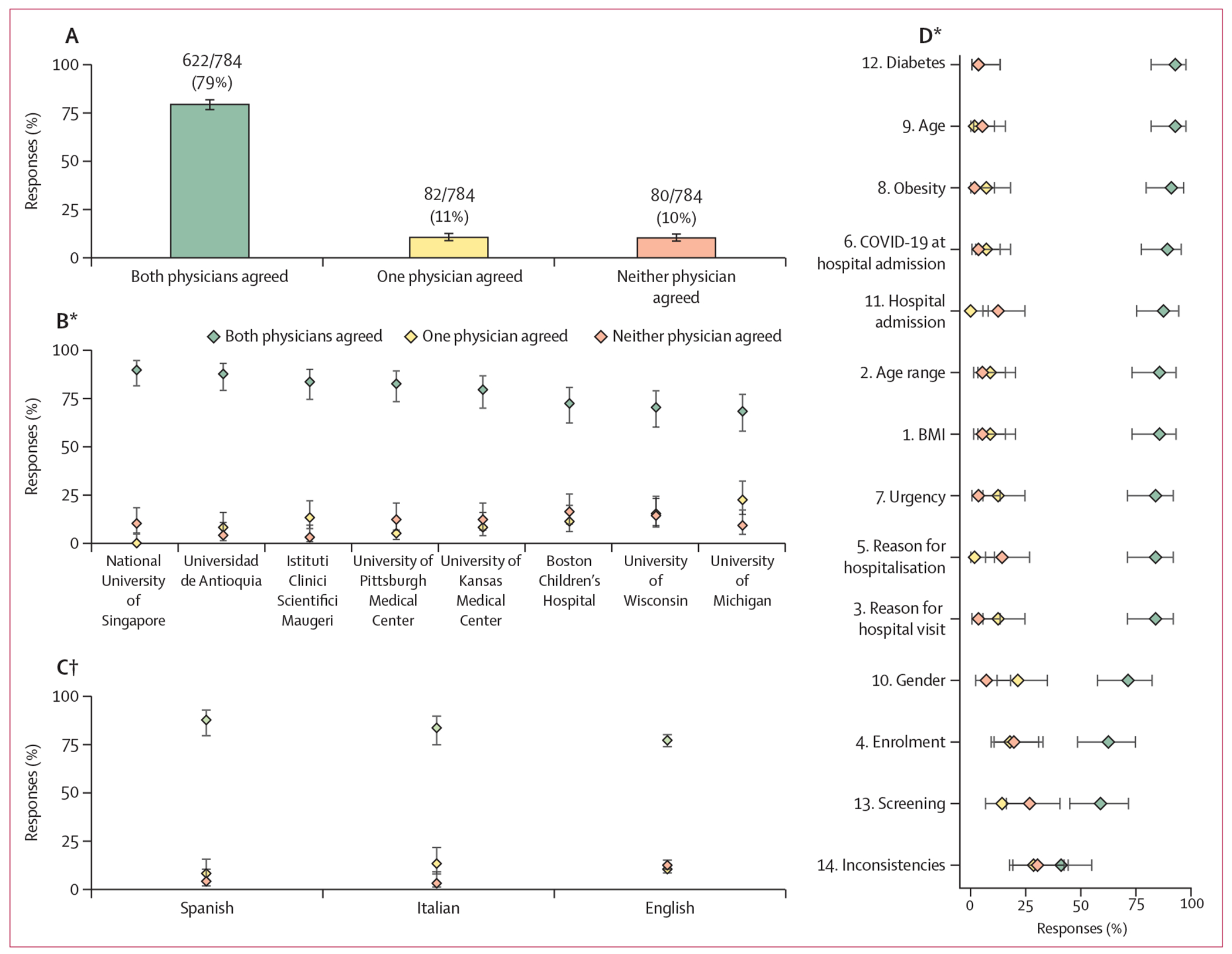
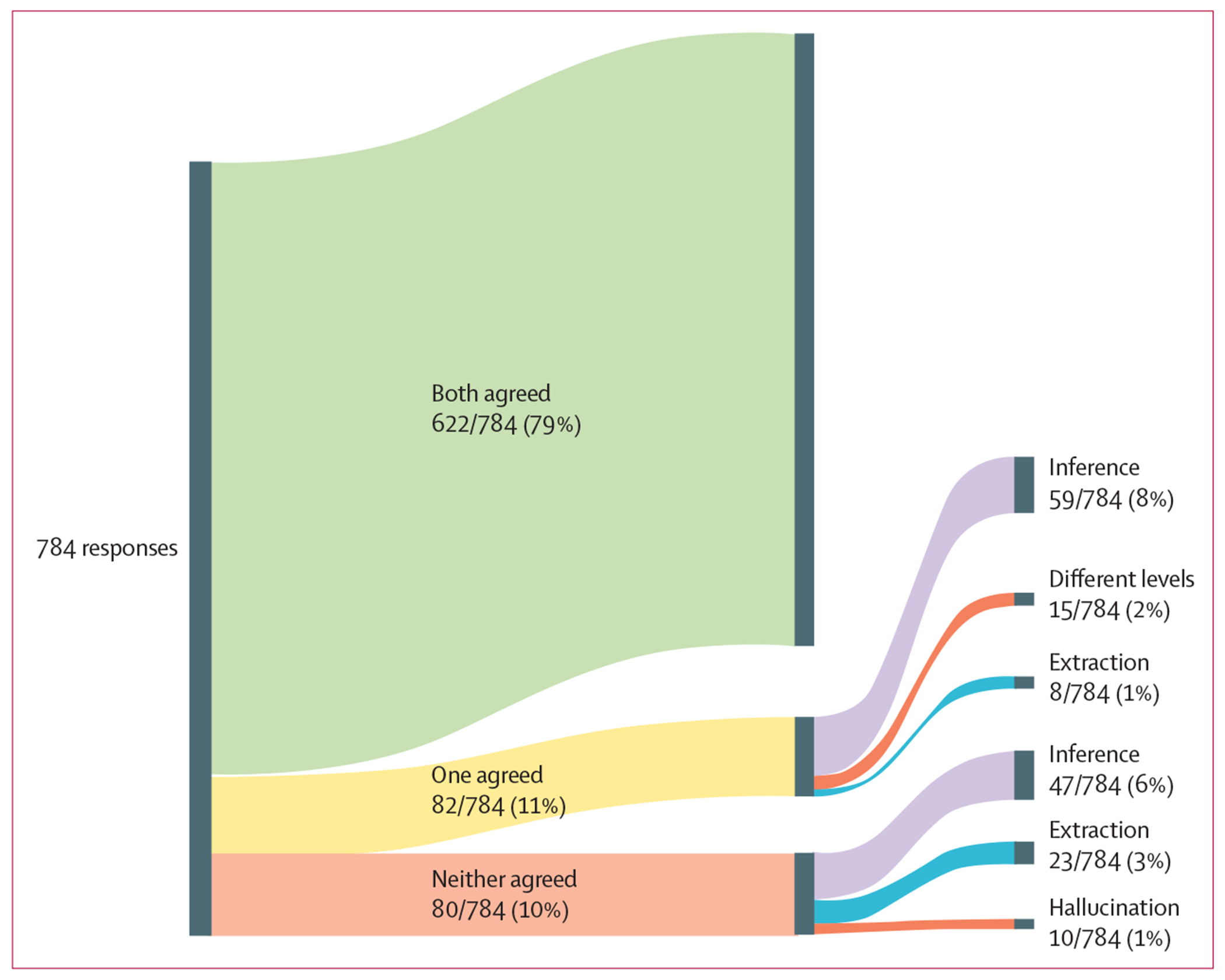
Findings: We collected 56 medical notes, of which 42 (75%) were in English, seven (13%) were in Italian, and seven (13%) were in Spanish. For each medical note, GPT-4 responded to 14 questions, resulting in 784 responses. In 622 (79%, 95% CI 76-82) of 784 responses, both physicians agreed with GPT-4. In 82 (11%, 8-13) responses, only one physician agreed with GPT-4. In the remaining 80 (10%, 8-13) responses, neither physician agreed with GPT-4. Both physicians agreed with GPT-4 more often for medical notes written in Spanish (86 [88%, 95% CI 79-93] of 98 responses) and Italian (82 [84%, 75-90] of 98 responses) than in English (454 [77%, 74-80] of 588 responses).
Interpretation: The results of our model-evaluation study suggest that GPT-4 is accurate when analysing medical notes in three different languages. In the future, research should explore how LLMs can be integrated into clinical workflows to maximise their use in health care.
Funding: None.
Copyright © 2025 The Author(s). Published by Elsevier Ltd. This is an Open Access article under the CC BY 4.0 license. Published by Elsevier Ltd.. All rights reserved.
Conflict of interest statement
Declaration of interests DAH receives a grant from the US National Institutes of Health (NIH) National Center for Advancing Translational Sciences (UM1TRO04404). DRM receives support from the National Center for Advancing Translational Sciences of the US NIH (UL1TR002366). EP and RB receive a grant from the EU Horizon 2020 Project PERISCOPE (101016233). GSO receives grants from the US NIH (U24CA271037 and P30ES017885). VLM receives financial support, paid to his institution, from Siemens Healthineers and the Melvyn Rubenfire Professorship in Preventive Cardiology and receives grants from the US NIH (R01AG059729, R01HL136685, and U01DK123013) and the American Heart Association Strategically Focused Research Network (20SFRN35120123). ZX receives grants from the National Institute of Neurological Disorders and Stroke of the US NIH (R01NS098023 and R01NS124882). All other authors declare no competing interests.
Figures
Comment in
-
A long STANDING commitment to improving health care.Lancet Digit Health. 2025 Jan;7(1):e1. doi: 10.1016/j.landig.2024.12.005. Epub 2024 Dec 18. Lancet Digit Health. 2025. PMID: 39701920 No abstract available.
References
-
- Agrawal M, Hegselmann S, Lang H, Kim Y, Sontag D. Large language models are few-shot clinical information extractors. arXiv 2022; published online Nov 30. https://arxiv.org/abs/2205.12689 (preprint).
-
- Russell LB. Electronic health records: the signal and the noise. Med Decis Making 2021; 41: 103–06. - PubMed
-
- Ahsan H, McInerney DJ, Kim J, et al. Retrieving evidence from EHRs with LLMs: possibilities and challenges. arXiv 2024; published online June 10. https://arxiv.org/abs/2205.12689 (preprint). - PMC - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
