

BAE-ViT: An Efficient Multimodal Vision Transformer for Bone Age Estimation
- PMID: 39728908
- PMCID: PMC11679900
- DOI: 10.3390/tomography10120146
BAE-ViT: An Efficient Multimodal Vision Transformer for Bone Age Estimation
Abstract
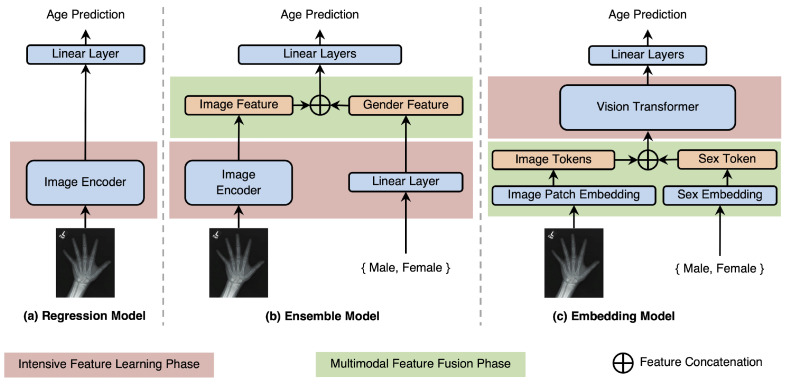
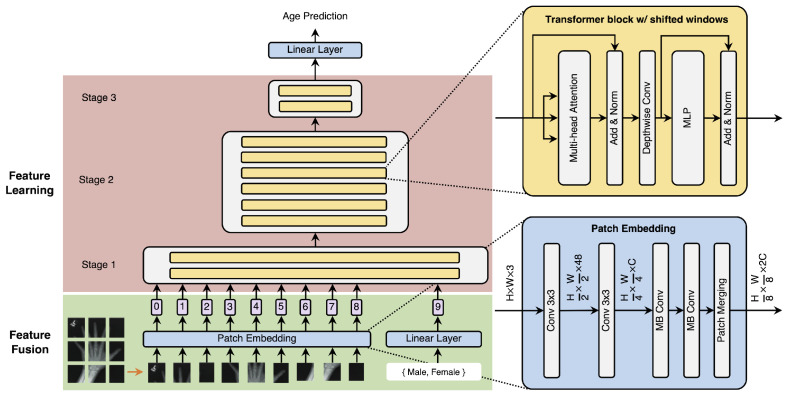
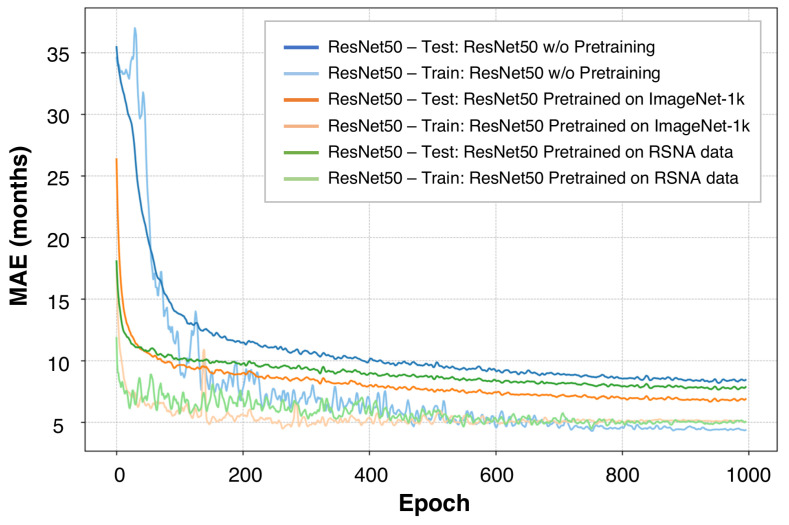
This research introduces BAE-ViT, a specialized vision transformer model developed for bone age estimation (BAE). This model is designed to efficiently merge image and sex data, a capability not present in traditional convolutional neural networks (CNNs). BAE-ViT employs a novel data fusion method to facilitate detailed interactions between visual and non-visual data by tokenizing non-visual information and concatenating all tokens (visual or non-visual) as the input to the model. The model underwent training on a large-scale dataset from the 2017 RSNA Pediatric Bone Age Machine Learning Challenge, where it exhibited commendable performance, particularly excelling in handling image distortions compared to existing models. The effectiveness of BAE-ViT was further affirmed through statistical analysis, demonstrating a strong correlation with the actual ground-truth labels. This study contributes to the field by showcasing the potential of vision transformers as a viable option for integrating multimodal data in medical imaging applications, specifically emphasizing their capacity to incorporate non-visual elements like sex information into the framework. This tokenization method not only demonstrates superior performance in this specific task but also offers a versatile framework for integrating multimodal data in medical imaging applications.
Keywords: bone age regression; gender embedding; machine learning; multimodal data; vision transformer.
Conflict of interest statement
Professor McMillan maintains a consulting position with Weinberg Medical Physics, LLC; however, no resources from this company were utilized in our study, and no financial ties exist between any author and the firm.
Figures


References
-
- Greulich W.W., Pyle S.I. Radiographic Atlas of Skeletal Development of the Hand and Wrist. Stanford University Press; Redwood City, CA, USA: 1959. [(accessed on 25 October 2022)]. Available online: http://www.sup.org/books/title/?id=2696.
-
- Poznanski A.K. Assessment of Skeletal Maturity and Prediction of Adult Height (TW2 Method) Am. J. Dis. Child. 1977;131:1041–1042. doi: 10.1001/archpedi.1977.02120220107024. - DOI
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
