

Large Language Models in Worldwide Medical Exams: Platform Development and Comprehensive Analysis
- PMID: 39729356
- PMCID: PMC11724220
- DOI: 10.2196/66114
Large Language Models in Worldwide Medical Exams: Platform Development and Comprehensive Analysis
Abstract
Background: Large language models (LLMs) are increasingly integrated into medical education, with transformative potential for learning and assessment. However, their performance across diverse medical exams globally has remained underexplored.
Objective: This study aims to introduce MedExamLLM, a comprehensive platform designed to systematically evaluate the performance of LLMs on medical exams worldwide. Specifically, the platform seeks to (1) compile and curate performance data for diverse LLMs on worldwide medical exams; (2) analyze trends and disparities in LLM capabilities across geographic regions, languages, and contexts; and (3) provide a resource for researchers, educators, and developers to explore and advance the integration of artificial intelligence in medical education.
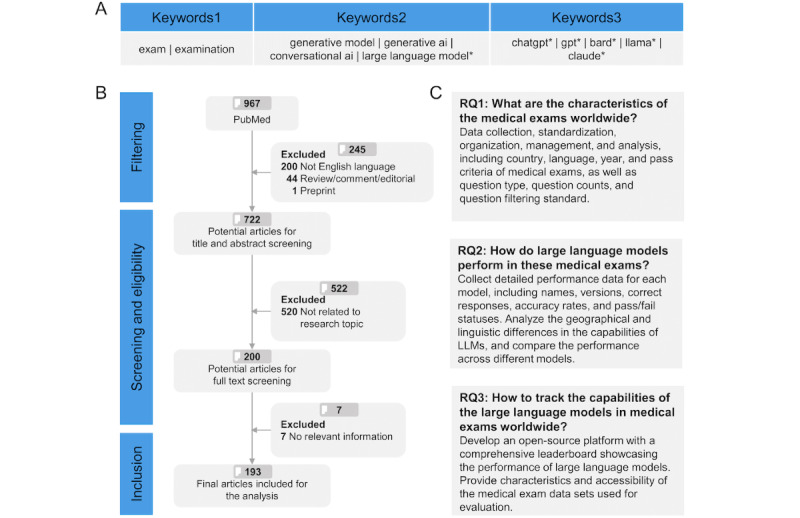
Methods: A systematic search was conducted on April 25, 2024, in the PubMed database to identify relevant publications. Inclusion criteria encompassed peer-reviewed, English-language, original research articles that evaluated at least one LLM on medical exams. Exclusion criteria included review articles, non-English publications, preprints, and studies without relevant data on LLM performance. The screening process for candidate publications was independently conducted by 2 researchers to ensure accuracy and reliability. Data, including exam information, data process information, model performance, data availability, and references, were manually curated, standardized, and organized. These curated data were integrated into the MedExamLLM platform, enabling its functionality to visualize and analyze LLM performance across geographic, linguistic, and exam characteristics. The web platform was developed with a focus on accessibility, interactivity, and scalability to support continuous data updates and user engagement.
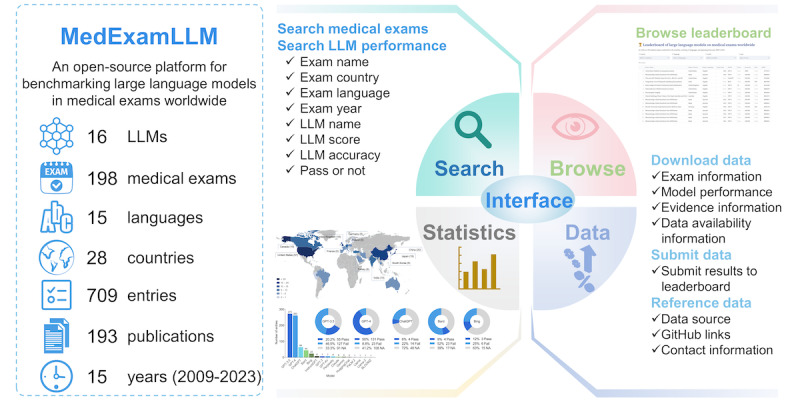
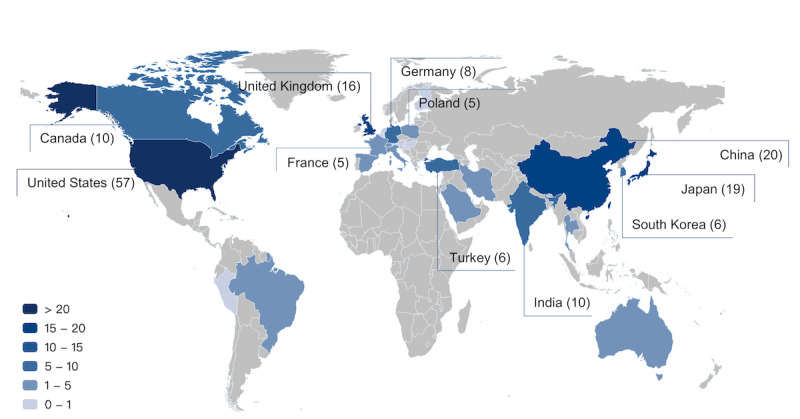
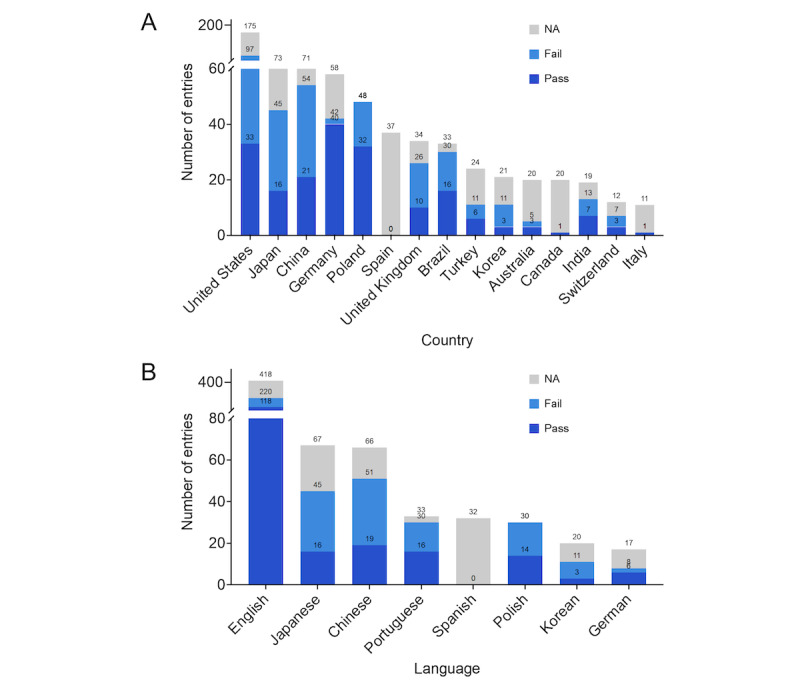
Results: A total of 193 articles were included for final analysis. MedExamLLM comprised information for 16 LLMs on 198 medical exams conducted in 28 countries across 15 languages from the year 2009 to the year 2023. The United States accounted for the highest number of medical exams and related publications, with English being the dominant language used in these exams. The Generative Pretrained Transformer (GPT) series models, especially GPT-4, demonstrated superior performance, achieving pass rates significantly higher than other LLMs. The analysis revealed significant variability in the capabilities of LLMs across different geographic and linguistic contexts.
Conclusions: MedExamLLM is an open-source, freely accessible, and publicly available online platform providing comprehensive performance evaluation information and evidence knowledge about LLMs on medical exams around the world. The MedExamLLM platform serves as a valuable resource for educators, researchers, and developers in the fields of clinical medicine and artificial intelligence. By synthesizing evidence on LLM capabilities, the platform provides valuable insights to support the integration of artificial intelligence into medical education. Limitations include potential biases in the data source and the exclusion of non-English literature. Future research should address these gaps and explore methods to enhance LLM performance in diverse contexts.
Keywords: AI; ChatGPT; LLMs; artifical intelligence; generative pretrained transformer; large language models; medical education; medical exam.
©Hui Zong, Rongrong Wu, Jiaxue Cha, Jiao Wang, Erman Wu, Jiakun Li, Yi Zhou, Chi Zhang, Weizhe Feng, Bairong Shen. Originally published in the Journal of Medical Internet Research (https://www.jmir.org), 27.12.2024.
Conflict of interest statement
Conflicts of Interest: None declared.
Figures
Similar articles
-
The Accuracy and Capability of Artificial Intelligence Solutions in Health Care Examinations and Certificates: Systematic Review and Meta-Analysis.J Med Internet Res. 2024 Nov 5;26:e56532. doi: 10.2196/56532. J Med Internet Res. 2024. PMID: 39499913 Free PMC article.
-
Large language models for conducting systematic reviews: on the rise, but not yet ready for use-a scoping review.J Clin Epidemiol. 2025 May;181:111746. doi: 10.1016/j.jclinepi.2025.111746. Epub 2025 Feb 26. J Clin Epidemiol. 2025. PMID: 40021099
-
A systematic review of large language model (LLM) evaluations in clinical medicine.BMC Med Inform Decis Mak. 2025 Mar 7;25(1):117. doi: 10.1186/s12911-025-02954-4. BMC Med Inform Decis Mak. 2025. PMID: 40055694 Free PMC article.
-
Learning to Make Rare and Complex Diagnoses With Generative AI Assistance: Qualitative Study of Popular Large Language Models.JMIR Med Educ. 2024 Feb 13;10:e51391. doi: 10.2196/51391. JMIR Med Educ. 2024. PMID: 38349725 Free PMC article.
-
The Role of Large Language Models in Transforming Emergency Medicine: Scoping Review.JMIR Med Inform. 2024 May 10;12:e53787. doi: 10.2196/53787. JMIR Med Inform. 2024. PMID: 38728687 Free PMC article.
Cited by
-
Enhancing ophthalmology students' awareness of retinitis pigmentosa: assessing the efficacy of ChatGPT in AI-assisted teaching of rare diseases-a quasi-experimental study.Front Med (Lausanne). 2025 Mar 18;12:1534294. doi: 10.3389/fmed.2025.1534294. eCollection 2025. Front Med (Lausanne). 2025. PMID: 40171502 Free PMC article.
-
Advancements in Herpes Zoster Diagnosis, Treatment, and Management: Systematic Review of Artificial Intelligence Applications.J Med Internet Res. 2025 Jun 30;27:e71970. doi: 10.2196/71970. J Med Internet Res. 2025. PMID: 40587773 Free PMC article. Review.
-
NDDRF 2.0: An update and expansion of risk factor knowledge base for personalized prevention of neurodegenerative diseases.Alzheimers Dement. 2025 May;21(5):e70282. doi: 10.1002/alz.70282. Alzheimers Dement. 2025. PMID: 40371632 Free PMC article.
-
Evaluating the Performance of ChatGPT on Board-Style Examination Questions in Ophthalmology: A Meta-Analysis.J Med Syst. 2025 Jul 5;49(1):94. doi: 10.1007/s10916-025-02227-7. J Med Syst. 2025. PMID: 40615678
-
AI in Home Care-Evaluation of Large Language Models for Future Training of Informal Caregivers: Observational Comparative Case Study.J Med Internet Res. 2025 Apr 28;27:e70703. doi: 10.2196/70703. J Med Internet Res. 2025. PMID: 40294407 Free PMC article.
References
-
- Wu T, He S, Liu J, Sun S, Liu K, Han Q, Tang Y. A brief overview of ChatGPT: the history, status quo and potential future development. IEEE/CAA J. Autom. Sinica. 2023 May;10(5):1122–1136. doi: 10.1109/jas.2023.123618. - DOI
-
- Touvron H, Martin L, Stone K, Albert P, Almahairi A, Babaei Y, Bashlykov N, Batra S, Bhargava P, Bhosale S, Bikel D, Blecher L, Canton Ferrer C, Chen M, Cucurull G, Esiobu D, Fernandes J, Fu J, Fu W, Fuller B, Gao C, Goswami V, Goyal N, Hartshorn A, Hosseini S, Hou R, Inan H, Kardas M, Kerkez V, Khabsa M, Kloumann I, Korenev A, Singh Koura P, Lachaux MA, Lavril T, Lee J, Liskovich D, Lu Y, Mao Y, Martinet X, Mihaylov T, Mishra P, Molybog I, Nie Y, Poulton A, Reizenstein J, Rungta R, Saladi K, Schelten A, Silva R, Smith EM, Subramanian R, Tan XE, Tang B, Taylor R, Williams A, Kuan JX, Xu P, Yan Z, Zarov I, Zhang Y, Fan A, Kambadur M, Narang S, Rodriguez A, Stojnic R, Edunov S, Scialom T. Llama 2: Open foundation and fine-tuned chat models. arXiv. doi: 10.48550/arXiv.2307.09288. Preprint posted online on July 19, 2023. - DOI
-
- Tu T, Azizi S, Driess D, Schaekermann M, Amin M, Chang P, Carroll A, Lau C, Tanno R, Ktena I, Palepu A, Mustafa B, Chowdhery A, Liu Y, Kornblith S, Fleet D, Mansfield P, Prakash S, Wong R, Virmani S, Semturs C, Mahdavi SS, Green B, Dominowska E, Arcas BAY, Barral J, Webster D, Corrado GS, Matias Y, Singhal K, Florence P, Karthikesalingam A, Natarajan V. Towards generalist biomedical AI. NEJM AI. 2024 Feb 22;1(3):1. doi: 10.1056/aioa2300138. - DOI
-
- Sahoo S, Plasek Joseph M, Xu Hua, Uzuner Özlem, Cohen Trevor, Yetisgen Meliha, Liu Hongfang, Meystre Stéphane, Wang Yanshan. Large language models for biomedicine: foundations, opportunities, challenges, and best practices. J Am Med Inform Assoc. 2024 Sep 01;31(9):2114–2124. doi: 10.1093/jamia/ocae074.7657768 - DOI - PMC - PubMed
MeSH terms
LinkOut - more resources
Full Text Sources
Miscellaneous
