

Evaluation of the integration of retrieval-augmented generation in large language model for breast cancer nursing care responses
- PMID: 39730573
- PMCID: PMC11680762
- DOI: 10.1038/s41598-024-81052-3
Evaluation of the integration of retrieval-augmented generation in large language model for breast cancer nursing care responses
Abstract
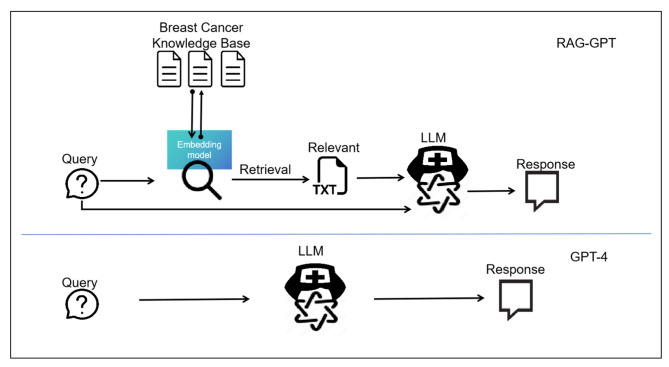
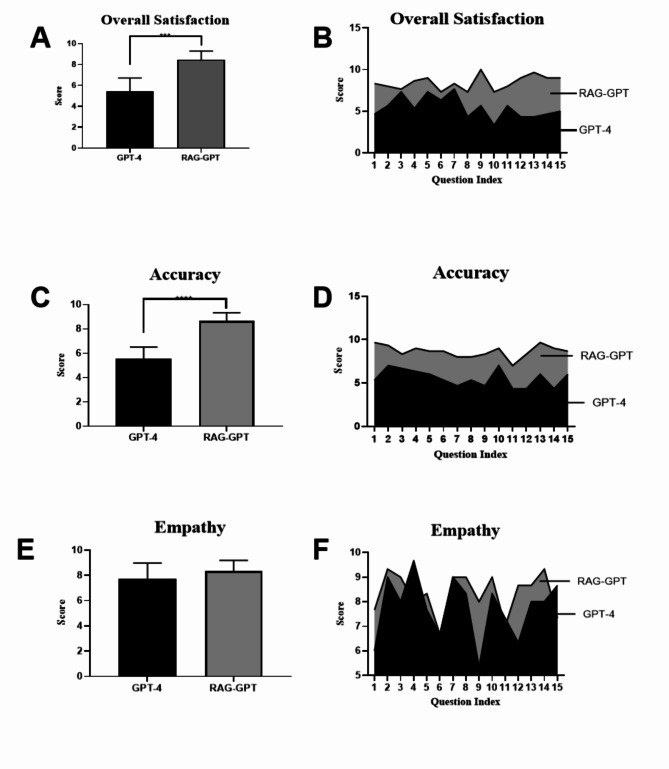
Breast cancer is one of the most common malignant tumors in women worldwide. Although large language models (LLMs) can provide breast cancer nursing care consultation, inherent hallucinations can lead to inaccurate responses. Retrieval-augmented generation (RAG) technology can improve LLM performance, offering a new approach for clinical applications. In the present study, we evaluated the performance of a LLM in breast cancer nursing care using RAG technology. In the control group (GPT-4), questions were answered directly using the GPT-4 model, whereas the experimental group (RAG-GPT) used the GPT-4 model combined with RAG. A knowledge base for breast cancer nursing was created for the RAG-GPT group, and 15 of 200 real-world clinical care questions were answered randomly. The primary endpoint was overall satisfaction, and the secondary endpoints were accuracy and empathy. RAG-GPT included a curated knowledge base related to breast cancer nursing care, including textbooks, guidelines, and traditional Chinese therapy. The RAG-GPT group showed significantly higher overall satisfaction than that of the GPT-4 group (8.4 ± 0.84 vs. 5.4 ± 1.27, p < 0.01) as well as an improved accuracy of responses (8.6 ± 0.69 vs. 5.6 ± 0.96, p < 0.01). However, there was no inter-group difference in empathy (8.4 ± 0.85 vs. 7.8 ± 1.22, p > 0.05). Overall, this study revealed that RAG technology could improve LLM performance significantly, likely because of the increased accuracy of the answers without diminishing empathy. These findings provide a theoretical basis for applying RAG technology to LLMs in clinical nursing practice and education.
Keywords: Breast cancer nursing care; ChatGPT; GPT-4; Large language models; Nurse; Retrieval-augmented generation.
© 2024. The Author(s).
Conflict of interest statement
Declarations. Competing interests: The authors declare no competing interests. Approval for human experiments: As this study did not involve human or animal research and the ChatGPT API is freely accessible online, no ethical committee approval was required.
Figures
References
-
- Loibl, S. et al. Breast cancer. Lancet397(10286): 1750–1769. (2021). - PubMed
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
