

Clustering and classification for dry bean feature imbalanced data
- PMID: 39730714
- PMCID: PMC11681048
- DOI: 10.1038/s41598-024-82253-6
Clustering and classification for dry bean feature imbalanced data
Abstract
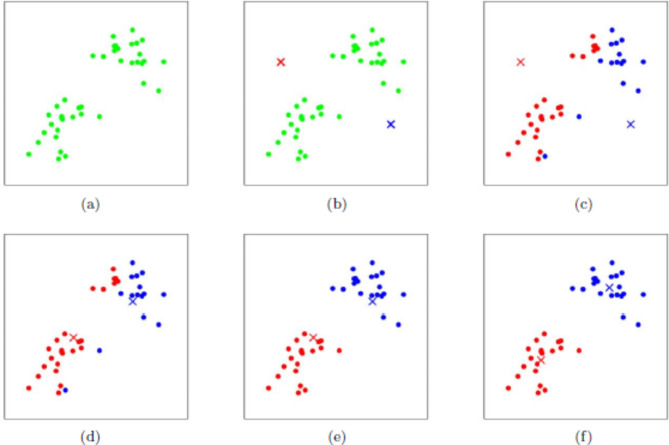
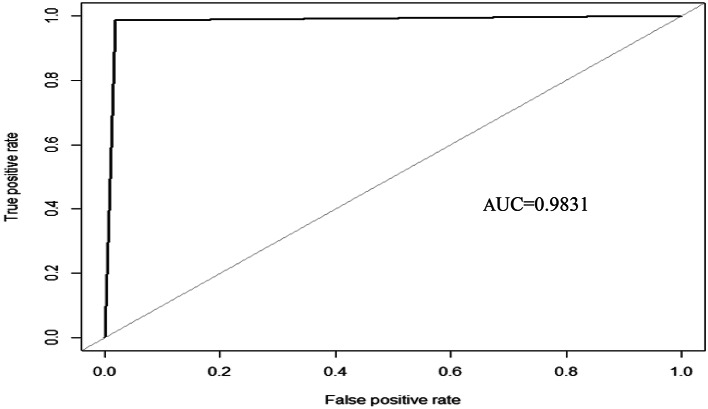
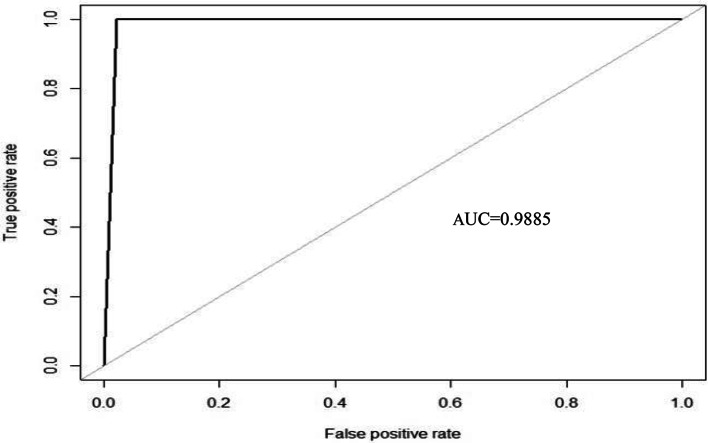
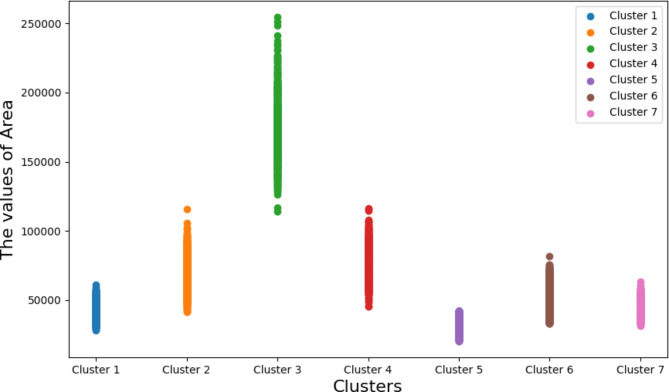
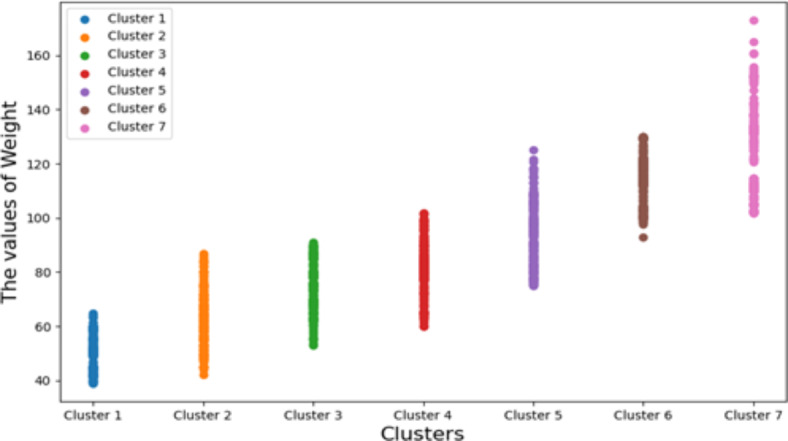
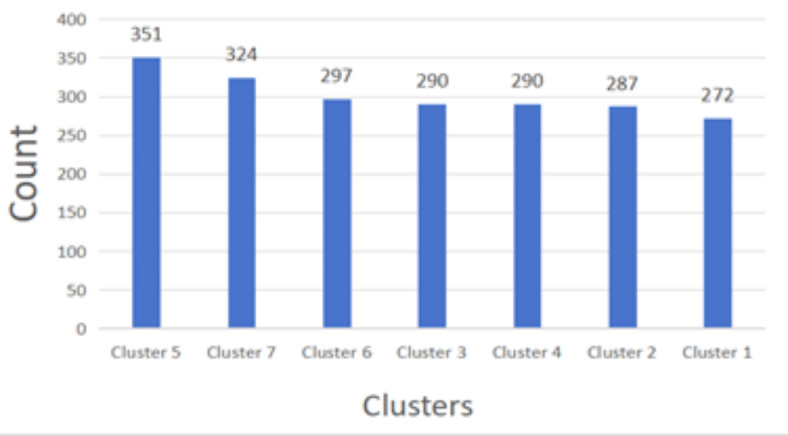
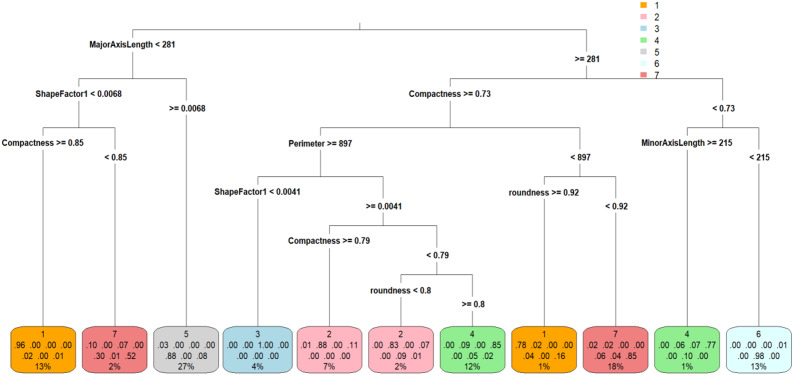
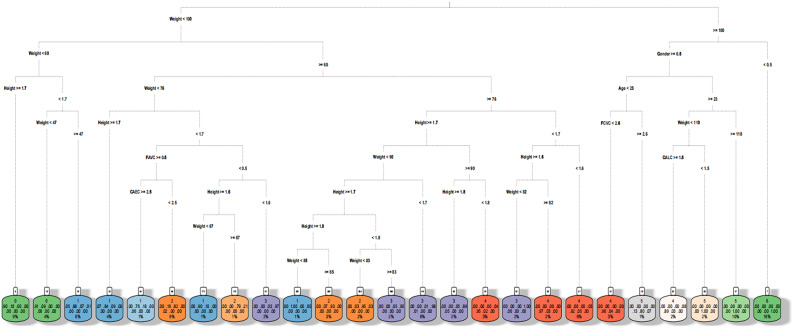
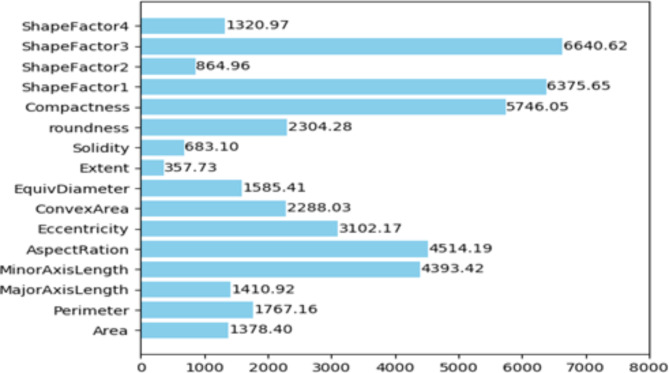
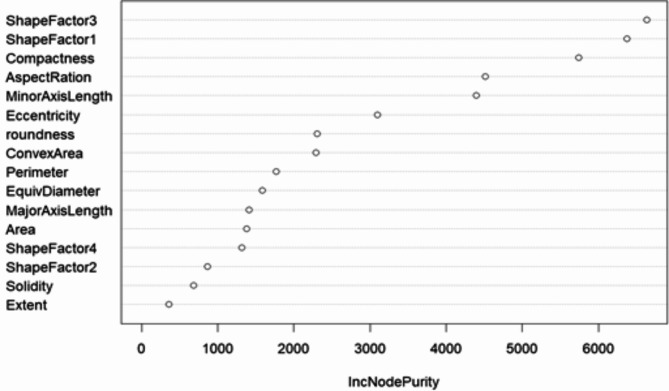
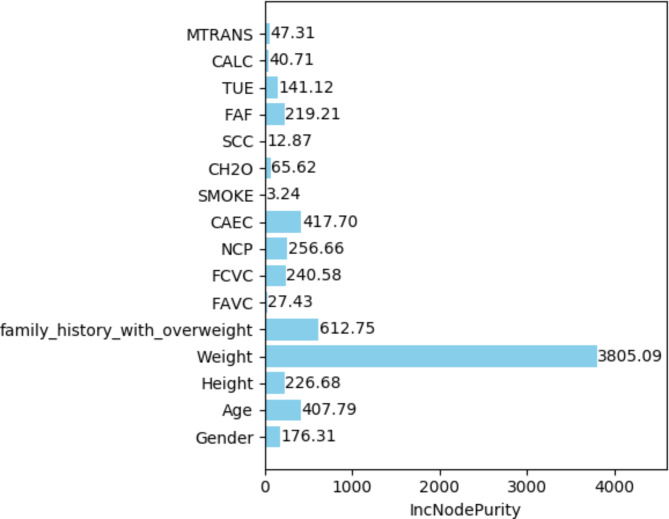
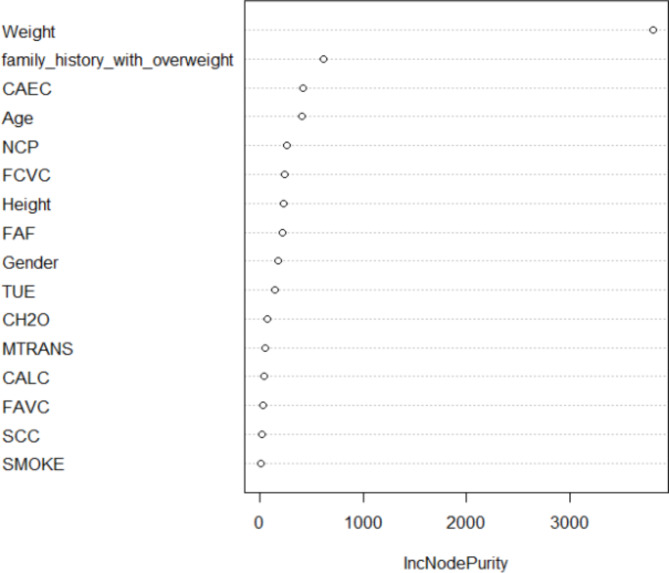
The traditional machine learning methods such as decision tree (DT), random forest (RF), and support vector machine (SVM) have low classification performance. This paper proposes an algorithm for the dry bean dataset and obesity levels dataset that can balance the minority class and the majority class and has a clustering function to improve the traditional machine learning classification accuracy and various performance indicators such as precision, recall, f1-score, and area under curve (AUC) for imbalanced data. The key idea is to use the advantages of borderline-synthetic minority oversampling technique (BLSMOTE) to generate new samples using samples on the boundary of minority class samples to reduce the impact of noise on model building, and the advantages of K-means clustering to divide data into different groups according to similarities or common features. The results show that the proposed algorithm BLSMOTE + K-means + SVM is superior to other traditional machine learning methods in classification and various performance indicators. The BLSMOTE + K-means + DT generates decision rules for the dry bean dataset and the the obesity levels dataset, and the BLSMOTE + K-means + RF ranks the importance of explanatory variables. These experimental results can provide scientific evidence for decision-makers.
Keywords: BLSMOTE; Decision tree; Imbalanced data; K-means; Random forest; Support vector machine.
© 2024. The Author(s).
Conflict of interest statement
Declarations. Competing interests: The authors declare no competing interests.
Figures



Similar articles
-
Prediction and feature selection of low birth weight using machine learning algorithms.J Health Popul Nutr. 2024 Oct 12;43(1):157. doi: 10.1186/s41043-024-00647-8. J Health Popul Nutr. 2024. PMID: 39396025 Free PMC article.
-
Addressing Imbalanced Classification Problems in Drug Discovery and Development Using Random Forest, Support Vector Machine, AutoGluon-Tabular, and H2O AutoML.J Chem Inf Model. 2025 Apr 28;65(8):3976-3989. doi: 10.1021/acs.jcim.5c00023. Epub 2025 Apr 15. J Chem Inf Model. 2025. PMID: 40230275
-
Hybrid statistical and machine-learning approach to hearing-loss identification based on an oversampling technique.Comput Biol Med. 2025 Feb;185:109539. doi: 10.1016/j.compbiomed.2024.109539. Epub 2024 Dec 12. Comput Biol Med. 2025. PMID: 39672012
-
Joint modeling strategy for using electronic medical records data to build machine learning models: an example of intracerebral hemorrhage.BMC Med Inform Decis Mak. 2022 Oct 25;22(1):278. doi: 10.1186/s12911-022-02018-x. BMC Med Inform Decis Mak. 2022. PMID: 36284327 Free PMC article.
-
Comparison of Supervised Machine Learning Algorithms for Classifying of Home Discharge Possibility in Convalescent Stroke Patients: A Secondary Analysis.J Stroke Cerebrovasc Dis. 2021 Oct;30(10):106011. doi: 10.1016/j.jstrokecerebrovasdis.2021.106011. Epub 2021 Jul 26. J Stroke Cerebrovasc Dis. 2021. PMID: 34325274
References
-
- Mendigoria, C. H. et al. Seed architectural phenes prediction and variety classification of dry beans using machine learning algorithms. IEEE 9th Reg. 10 Humanitarian Technol. Conf., 1–6 (2021).
MeSH terms
LinkOut - more resources
Full Text Sources
