

Generative dynamical models for classification of rsfMRI data
- PMID: 39735493
- PMCID: PMC11675094
- DOI: 10.1162/netn_a_00412
Generative dynamical models for classification of rsfMRI data
Abstract
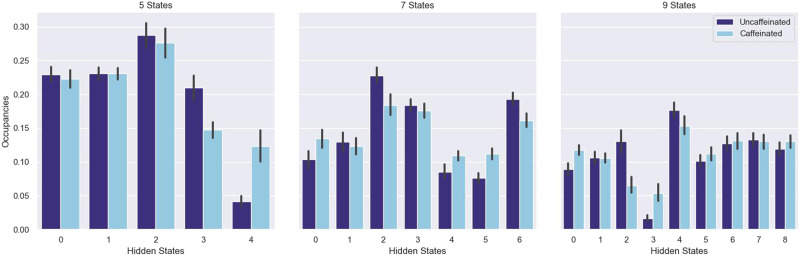
The growing availability of large-scale neuroimaging datasets and user-friendly machine learning tools has led to a recent surge in studies that use fMRI data to predict psychological or behavioral variables. Many such studies classify fMRI data on the basis of static features, but fewer try to leverage brain dynamics for classification. Here, we pilot a generative, dynamical approach for classifying resting-state fMRI (rsfMRI) data. By fitting separate hidden Markov models to the classes in our training data and assigning class labels to test data based on their likelihood under those models, we are able to take advantage of dynamical patterns in the data without confronting the statistical limitations of some other dynamical approaches. Moreover, we demonstrate that hidden Markov models are able to successfully perform within-subject classification on the MyConnectome dataset solely on the basis of transition probabilities among their hidden states. On the other hand, individual Human Connectome Project subjects cannot be identified on the basis of hidden state transition probabilities alone-although a vector autoregressive model does achieve high performance. These results demonstrate a dynamical classification approach for rsfMRI data that shows promising performance, particularly for within-subject classification, and has the potential to afford greater interpretability than other approaches.
Keywords: Classification; Generative models; Hidden Markov models; Network dynamics; Resting-state fMRI.
Plain language summary
Neuroimaging researchers have made substantial progress in using brain data to predict psychological and behavioral variables, like personality, cognitive abilities, and neurological and psychiatric diagnoses. In general, however, these prediction approaches do not take account of how brain activity changes over time. In this study, we use hidden Markov models, a simple and generic model for dynamic processes, to perform brain-based prediction. We show that hidden Markov models can successfully distinguish whether a single individual had eaten and consumed caffeine before his brain scan. These models also show some promise for “fingerprinting,” or identifying individuals solely on the basis of their brain scans. This study demonstrates that hidden Markov models are a promising tool for neuroimaging-based prediction.
© 2024 Massachusetts Institute of Technology.
Conflict of interest statement
Competing Interests: The authors have declared that no competing interests exist.
Figures













References
-
- Bondi, E., Maggioni, E., Brambilla, P., & Delvecchio, G. (2023). A systematic review on the potential use of machine learning to classify major depressive disorder from healthy controls using resting state fMRI measures. Neuroscience & Biobehavioral Reviews, 144, 104972. 10.1016/j.neubiorev.2022.104972, - DOI - PubMed
-
- Bustamante, C., Castrillón, G., & Arias-Londoño, J. (2023). Classification of focused perturbations using time-variant functional connectivity with rs-fMRI. In Communications in computer and information science (Vol. 1746, pp. 18–30). Springer. 10.1007/978-3-031-29783-0_2 - DOI
LinkOut - more resources
Full Text Sources