

Pattern memory cannot be completely and truly realized in deep neural networks
- PMID: 39738102
- PMCID: PMC11685877
- DOI: 10.1038/s41598-024-80647-0
Pattern memory cannot be completely and truly realized in deep neural networks
Abstract
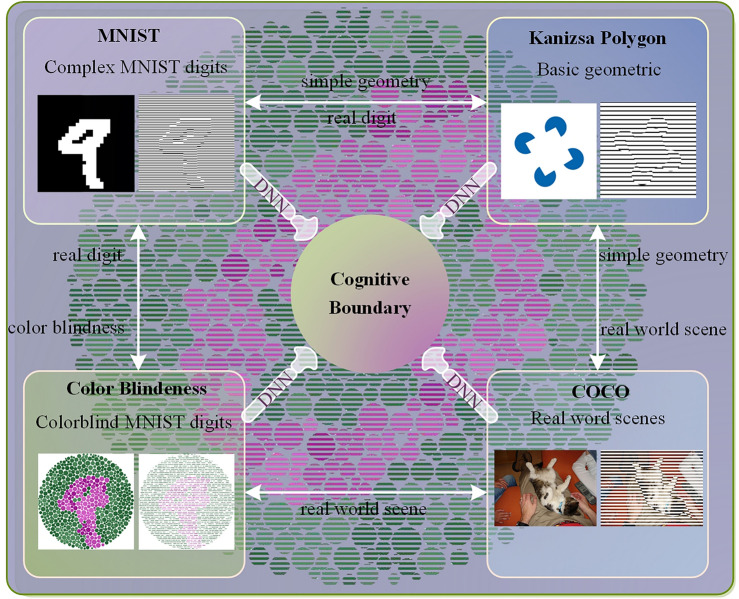
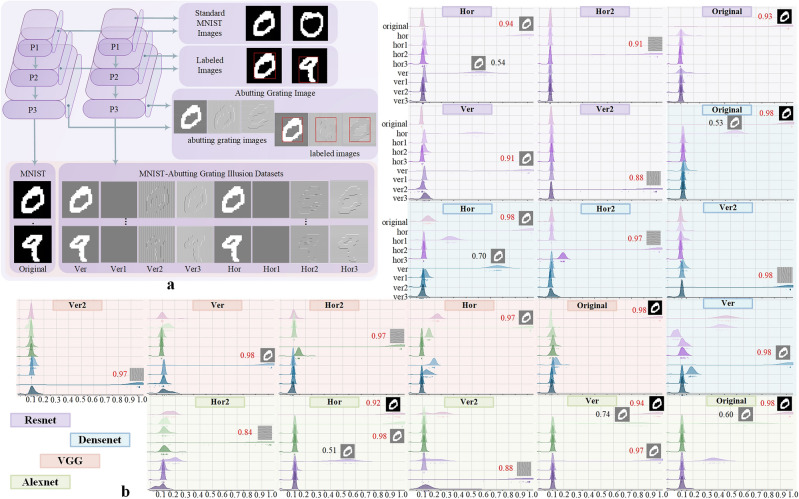
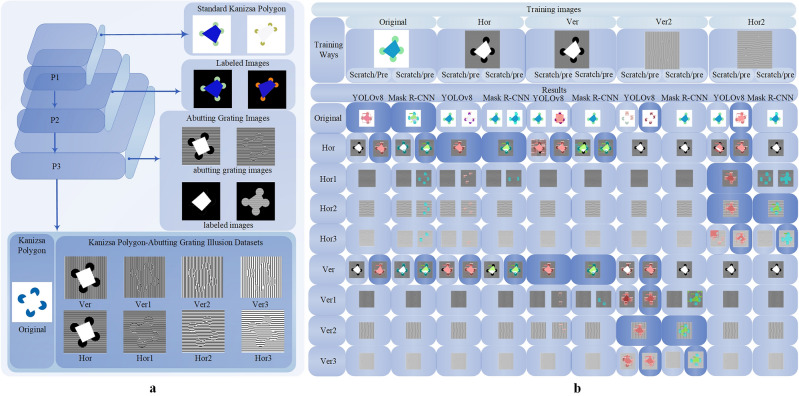
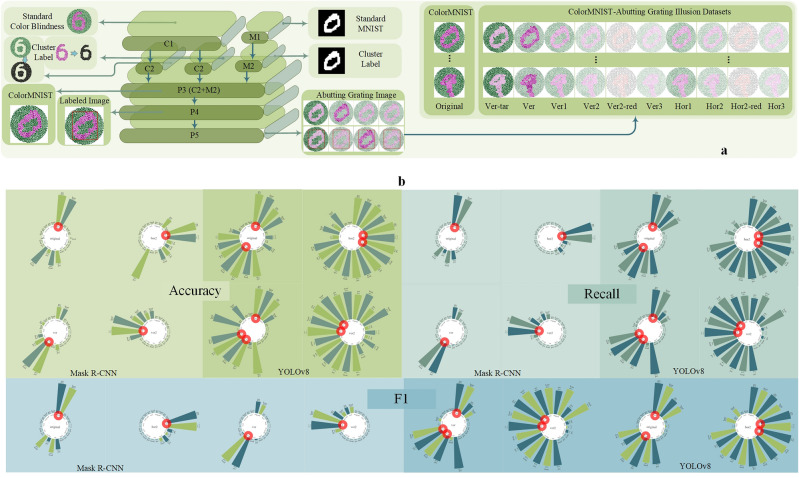
The unknown boundary issue, between superior computational capability of deep neural networks (DNNs) and human cognitive ability, has becoming crucial and foundational theoretical problem in AI evolution. Undoubtedly, DNN-empowered AI capability is increasingly surpassing human intelligence in handling general intelligent tasks. However, the absence of DNN's interpretability and recurrent erratic behavior remain incontrovertible facts. Inspired by perceptual characteristics of human vision on optical illusions, we propose a novel working capability analysis framework for DNNs through innovative cognitive response characteristics on visual illusion images, accompanied with fine adjustable sample image construction strategy. Our findings indicate that, although DNNs can infinitely approximate human-provided empirical standards in pattern classification, object detection and semantic segmentation, they are still unable to truly realize independent pattern memorization. All super cognitive abilities of DNNs purely come from their powerful sample classification performance on similar known scenes. Above discovery establishes a new foundation for advancing artificial general intelligence.
© 2024. The Author(s).
Conflict of interest statement
Declarations. Competing interests: The authors declare no competing interests.
Figures

References
-
- Silver, D. et al. Mastering the game of go without human knowledge. Nature550, 354–359 (2017). - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
