

Bidimensionally partitioned online sequential broad learning system for large-scale data stream modeling
- PMID: 39738996
- PMCID: PMC11685709
- DOI: 10.1038/s41598-024-83563-5
Bidimensionally partitioned online sequential broad learning system for large-scale data stream modeling
Abstract
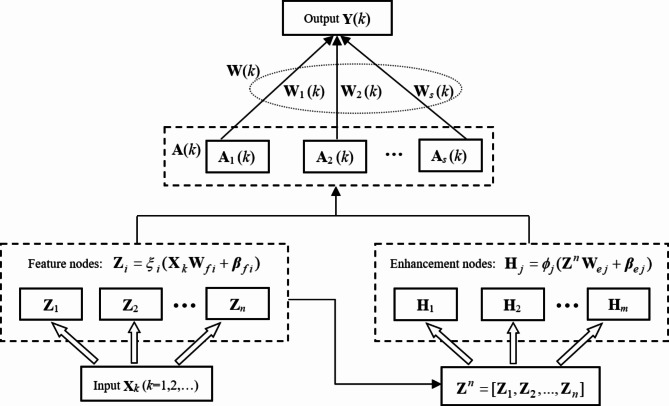
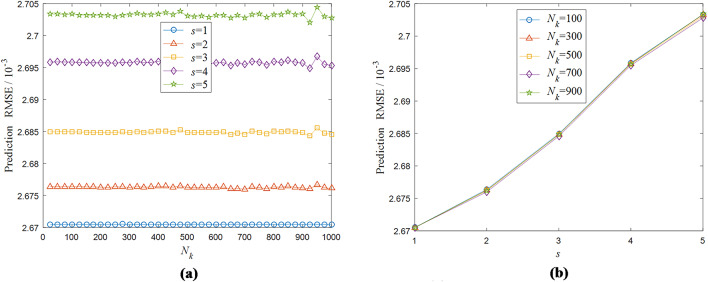
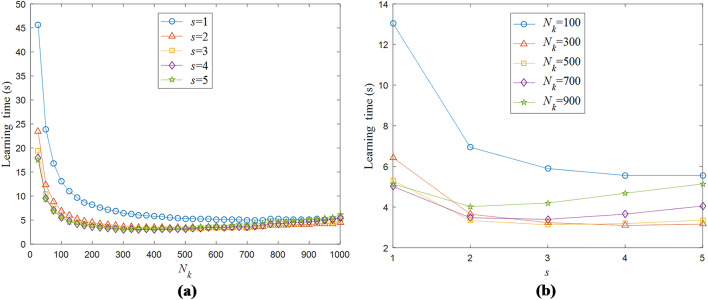
Incremental broad learning system (IBLS) is an effective and efficient incremental learning method based on broad learning paradigm. Owing to its streamlined network architecture and flexible dynamic update scheme, IBLS can achieve rapid incremental reconstruction on the basis of the previous model without the entire retraining from scratch, which enables it adept at handling streaming data. However, two prominent deficiencies still persist in IBLS and constrain its further promotion in large-scale data stream scenarios. Firstly, IBLS needs to retain all historical data and perform associated calculations in the incremental learning process, which causes its computational overhead and storage burden to increase over time and as such puts the efficacy of the algorithm at risk for massive or unlimited data streams. Additionally, due to the random generation rule of hidden nodes, IBLS generally necessitates a large network size to guarantee approximation accuracy, and the resulting high-dimensional matrix calculation poses a greater challenge to the updating efficiency of the model. To address these issues, we propose a novel bidimensionally partitioned online sequential broad learning system (BPOSBLS) in this paper. The core idea of BPOSBLS is to partition the high-dimensional broad feature matrix bidimensionally from the aspects of instance dimension and feature dimension, and consequently decompose a large least squares problem into multiple smaller ones, which can then be solved individually. By doing so, the scale and computational complexity of the original high-order model are substantially diminished, thus significantly improving its learning efficiency and usability for large-scale complex learning tasks. Meanwhile, an ingenious recursive computation method called partitioned recursive least squares is devised to solve the BPOSBLS. This method exclusively utilizes the current online samples for iterative updating, while disregarding the previous historical samples, thereby rendering BPOSBLS a lightweight online sequential learning algorithm with consistently low computational costs and storage requirements. Theoretical analyses and simulation experiments demonstrate the effectiveness and superiority of the proposed algorithm.
Keywords: Big data modeling; Broad learning system; Matrix partitioning; Online sequential learning; Partitioned recursive least squares.
© 2024. The Author(s).
Conflict of interest statement
Declarations. Competing interests: The authors declare no competing interests.
Figures




References
-
- Sun, J., Li, C., Wang, Z. & Wang, Y. A Memristive Fully Connect Neural Network and Application of Medical Image Encryption Based on Central Diffusion Algorithm. IEEE Trans. Ind. Inf.20, 3778–3788. 10.1109/TII.2023.3312405 (2024).
-
- Sun, J., Zhai, Y., Liu, P. & Wang, Y. Memristor-Based Neural Network Circuit of Associative Memory With Overshadowing and Emotion Congruent Effect. IEEE Trans. Neural Netw. Learn. Syst. 1–13. 10.1109/TNNLS.2023.3348553 (2024). Early Access. - PubMed
-
- Bessadok, A., Mahjoub, M. A. & Rekik, I. Graph Neural Networks in Network Neuroscience. IEEE Trans. Pattern Anal. Mach. Intell.45, 5833–5848. 10.1109/TPAMI.2022.3209686 (2023). - PubMed
-
- Chen, C. L. P. & Liu, Z. Broad learning system: an effective and efficient incremental learning system without the need for deep architecture. IEEE Trans. Neural Netw. Learn. Syst.29, 10–24 (2018). - PubMed
-
- Guo, W., Chen, S. & Yuan, X. H-BLS: a hierarchical broad learning system with deep and sparse feature learning. Appl. Intell.53, 153–168. 10.1007/s10489-022-03498-0 (2023).
Grants and funding
LinkOut - more resources
Full Text Sources
