

diaTracer enables spectrum-centric analysis of diaPASEF proteomics data
- PMID: 39747075
- PMCID: PMC11696033
- DOI: 10.1038/s41467-024-55448-8
diaTracer enables spectrum-centric analysis of diaPASEF proteomics data
Abstract
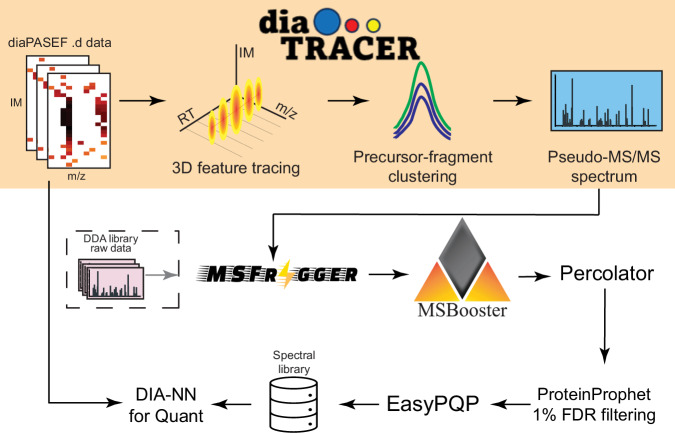
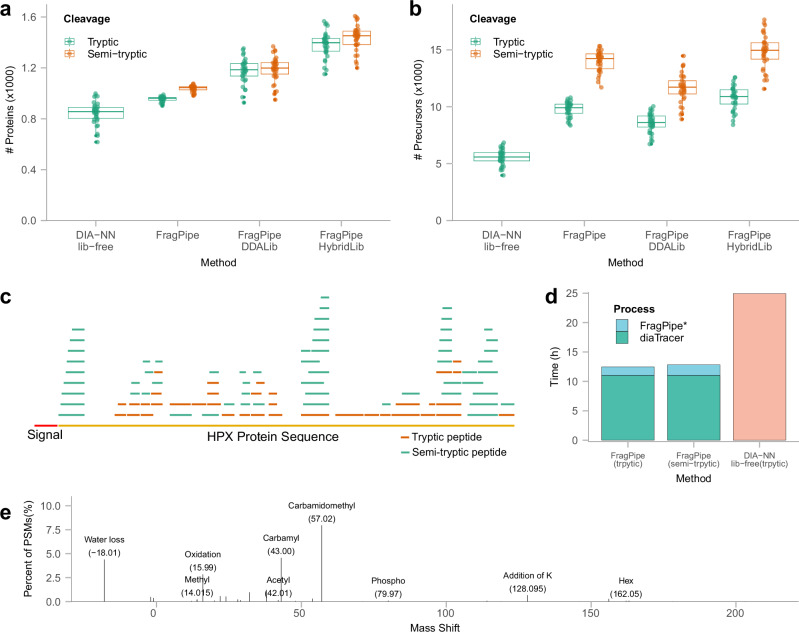
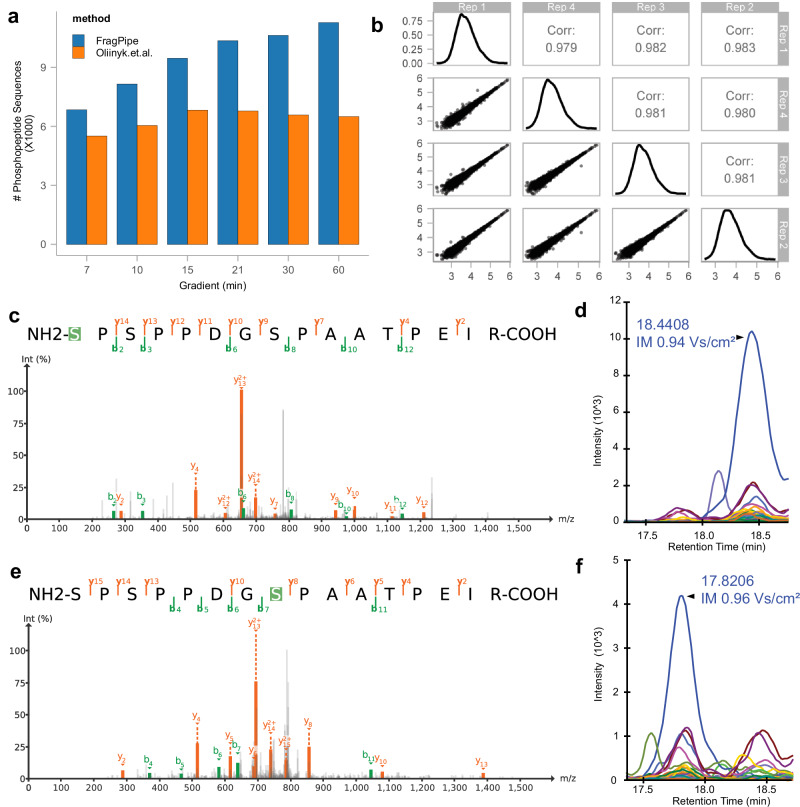
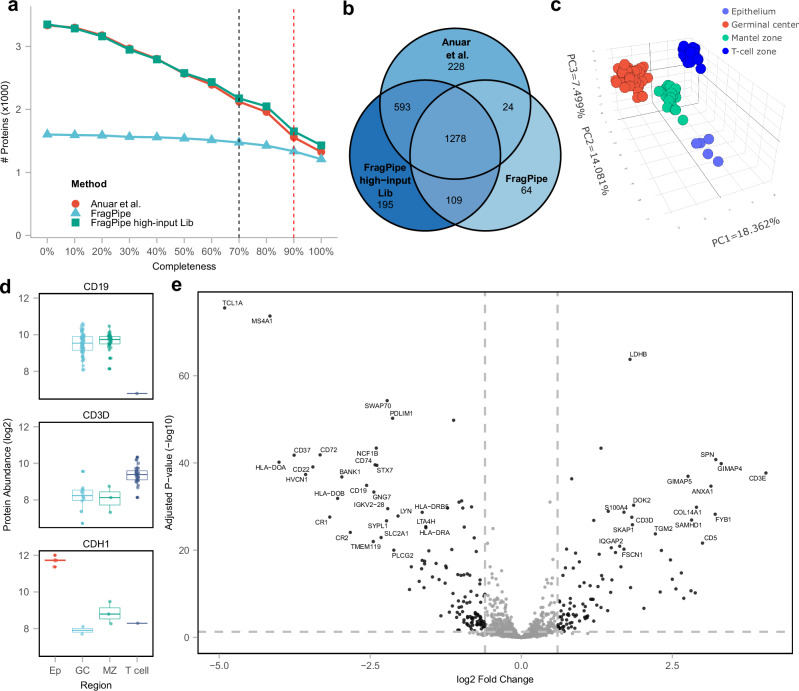
Data-independent acquisition has become a widely used strategy for peptide and protein quantification in liquid chromatography-tandem mass spectrometry-based proteomics studies. The integration of ion mobility separation into data-independent acquisition analysis, such as the diaPASEF technology available on Bruker's timsTOF platform, further improves the quantification accuracy and protein depth achievable using data-independent acquisition. We introduce diaTracer, a spectrum-centric computational tool optimized for diaPASEF data. diaTracer performs three-dimensional (mass to charge ratio, retention time, ion mobility) peak tracing and feature detection to generate precursor-resolved "pseudo-tandem mass spectra", facilitating direct ("spectral-library free") peptide identification and quantification from diaPASEF data. diaTracer is available as a stand-alone tool and is fully integrated into the widely used FragPipe computational platform. We demonstrate the performance of diaTracer and FragPipe using diaPASEF data from triple-negative breast cancer, cerebrospinal fluid, and plasma samples, data from phosphoproteomics and human leukocyte antigens immunopeptidomics experiments, and low-input data from a spatial proteomics study. We also show that diaTracer enables unrestricted identification of post-translational modifications from diaPASEF data using open/mass-offset searches.
© 2024. The Author(s).
Conflict of interest statement
Competing interests: A.I.N. and F.Y. receive royalties from the University of Michigan for the sale of MSFragger, IonQuant, and diaTracer software licenses to commercial entities. K.L. receives royalties from the University of Michigan for the sale of diaTracer software licenses to commercial entities. All license transactions are managed by the University of Michigan Innovation Partnerships office, and all proceeds are subject to university technology transfer policy. Other authors declare no other competing interests.
Figures



Update of
-
diaTracer enables spectrum-centric analysis of diaPASEF proteomics data.bioRxiv [Preprint]. 2024 Oct 16:2024.05.25.595875. doi: 10.1101/2024.05.25.595875. bioRxiv. 2024. Update in: Nat Commun. 2025 Jan 2;16(1):95. doi: 10.1038/s41467-024-55448-8. PMID: 38854051 Free PMC article. Updated. Preprint.
References
-
- Aebersold, R. & Mann, M. Mass-spectrometric exploration of proteome structure and function. Nature537, 347–355 (2016). - PubMed
-
- Venable, J. D., Dong, M.-Q., Wohlschlegel, J., Dillin, A. & Yates, J. R. Automated approach for quantitative analysis of complex peptide mixtures from tandem mass spectra. Nat. Methods1, 39–45 (2004). - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
