

Brain-model neural similarity reveals abstractive summarization performance
- PMID: 39747634
- PMCID: PMC11696092
- DOI: 10.1038/s41598-024-84530-w
Brain-model neural similarity reveals abstractive summarization performance
Abstract
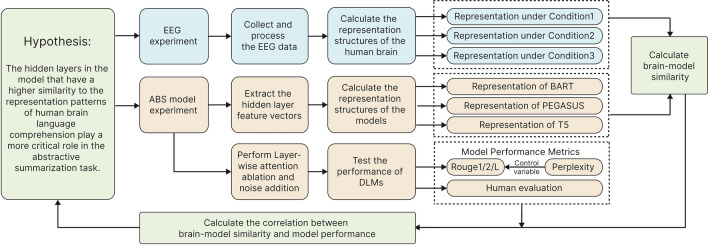
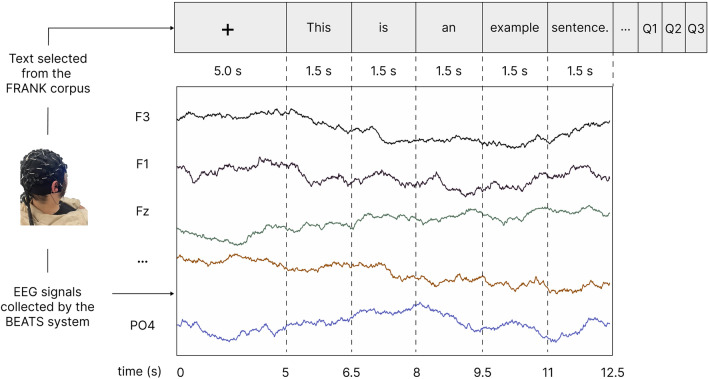
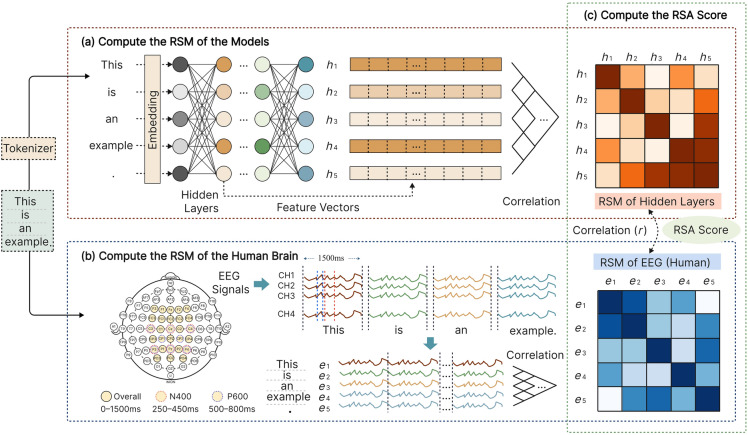
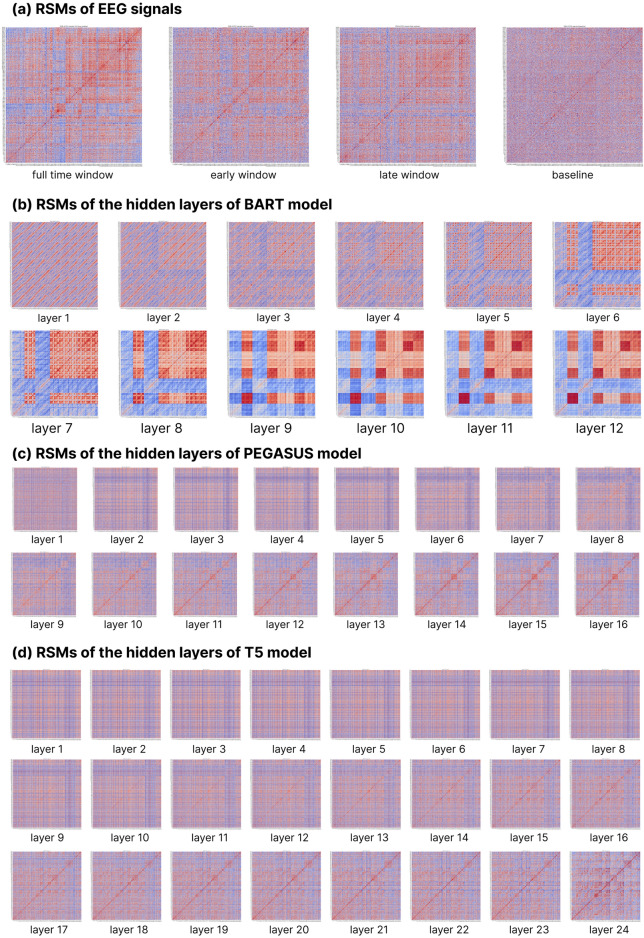
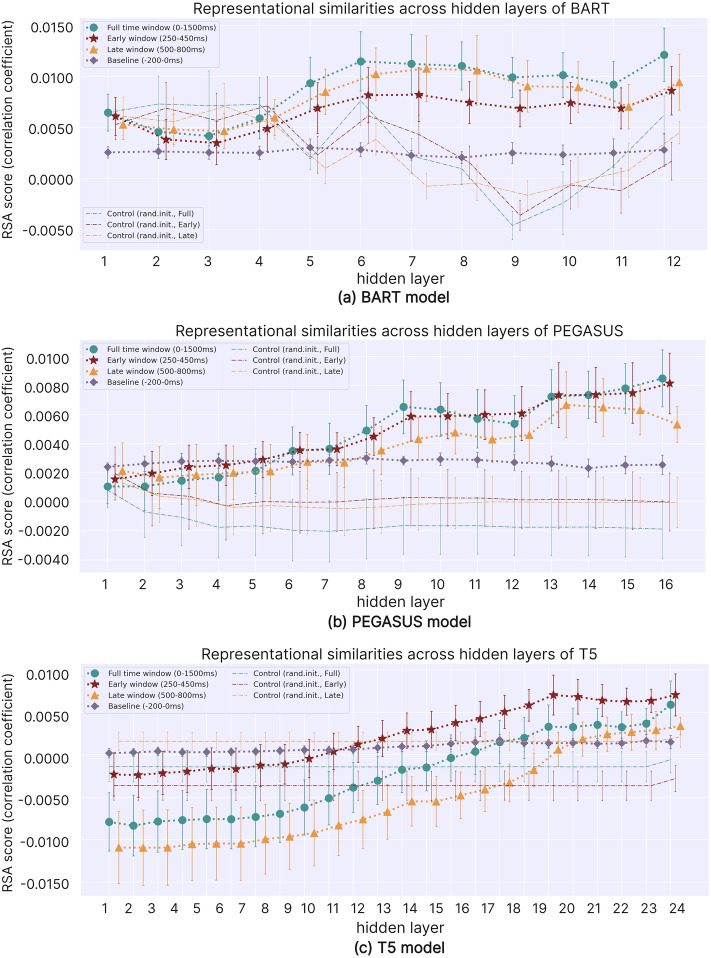
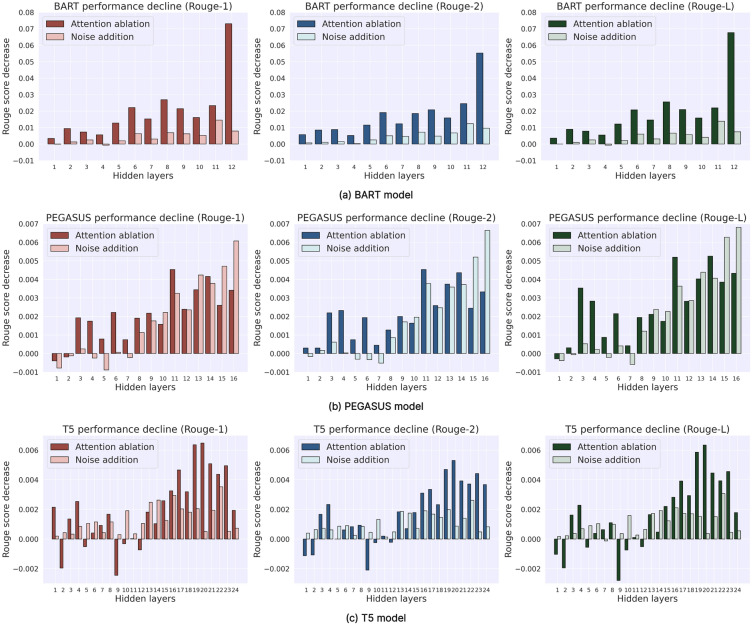
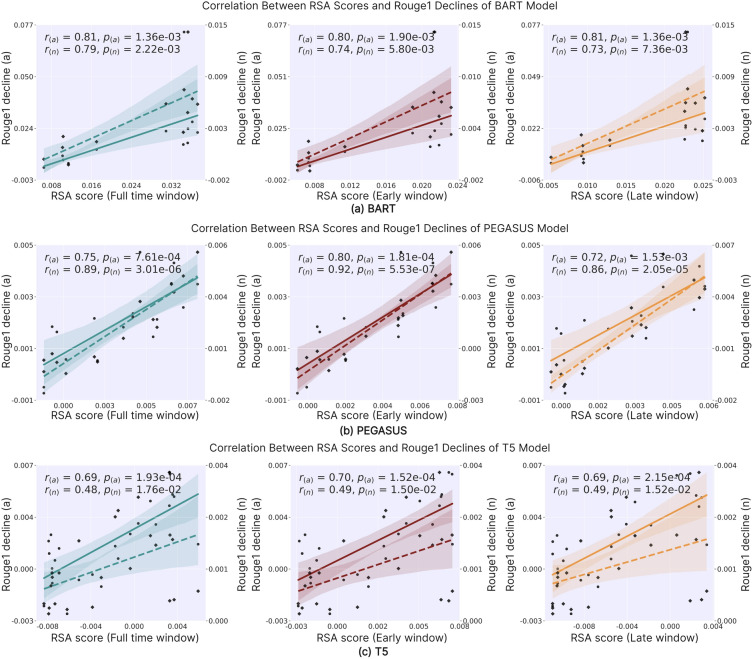
Deep language models (DLMs) have exhibited remarkable language understanding and generation capabilities, prompting researchers to explore the similarities between their internal mechanisms and human language cognitive processing. This study investigated the representational similarity (RS) between the abstractive summarization (ABS) models and the human brain and its correlation to the performance of ABS tasks. Specifically, representational similarity analysis (RSA) was used to measure the similarity between the representational patterns (RPs) of the BART, PEGASUS, and T5 models' hidden layers and the human brain's language RPs under different spatiotemporal conditions. Layer-wise ablation manipulation, including attention ablation and noise addition was employed to examine the hidden layers' effect on model performance. The results demonstrate that as the depth of hidden layers increases, the models' text encoding becomes increasingly similar to the human brain's language RPs. Manipulating deeper layers leads to more substantial decline in summarization performance compared to shallower layers, highlighting the crucial role of deeper layers in integrating essential information. Notably, the study confirms the hypothesis that the hidden layers exhibiting higher similarity to human brain activity play a more critical role in model performance, with their correlations reaching statistical significance even after controlling for perplexity. These findings deepen our understanding of the cognitive mechanisms underlying language representations in DLMs and their neural correlates, potentially providing insights for optimizing and improving language models by aligning them with the human brain's language-processing mechanisms.
Keywords: Abstractive summarization; Deep language models; Electroencephalography; Neural correlates; Representational similarity analysis.
© 2025. The Author(s).
Conflict of interest statement
Declarations. Competing interests: The authors declare no competing interests. Ethical approval declarations: The study was conducted according to the guidelines of the Declaration of Helsinki and approved by the Ethics Committee of the Beijing University of Posts and Telecommunications (Ethic approval code: 202302003).
Figures
References
-
- Chang, Y. et al. A survey on evaluation of large language models. ACM Trans. Intell. Syst. Technol.15, 1–45. 10.1145/3641289 (2024). - DOI
-
- Zhao, W. X. et al. A survey of large language models, 10.48550/arXiv.2303.18223 (2023). arXiv: 2303.18223.
-
- Arana, S., Pesnot Lerousseau, J. & Hagoort, P. Deep learning models to study sentence comprehension in the human brain. Lang. Cognit. Neurosci.. 10.1080/23273798.2023.2198245 (2023).
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
