

Task relevant autoencoding enhances machine learning for human neuroscience
- PMID: 39779744
- PMCID: PMC11711280
- DOI: 10.1038/s41598-024-83867-6
Task relevant autoencoding enhances machine learning for human neuroscience
Abstract
In human neuroscience, machine learning can help reveal lower-dimensional neural representations relevant to subjects' behavior. However, state-of-the-art models typically require large datasets to train, and so are prone to overfitting on human neuroimaging data that often possess few samples but many input dimensions. Here, we capitalized on the fact that the features we seek in human neuroscience are precisely those relevant to subjects' behavior rather than noise or other irrelevant factors. We thus developed a Task-Relevant Autoencoder via Classifier Enhancement (TRACE) designed to identify behaviorally-relevant target neural patterns. We benchmarked TRACE against a standard autoencoder and other models for two severely truncated machine learning datasets (to match the data typically available in functional magnetic resonance imaging [fMRI] data for an individual subject), then evaluated all models on fMRI data from 59 subjects who observed animals and objects. TRACE outperformed alternative models nearly unilaterally, showing up to 12% increased classification accuracy and up to 56% improvement in discovering "cleaner", task-relevant representations. These results showcase TRACE's potential for a wide variety of data related to human behavior.
Keywords: Autoencoder; Dimensionality reduction; Human neuroscience; MVPA; Machine learning; Task-relevant representation; fMRI.
© 2024. The Author(s).
Conflict of interest statement
Declarations. Competing interests: The authors declare no competing interests.
Figures
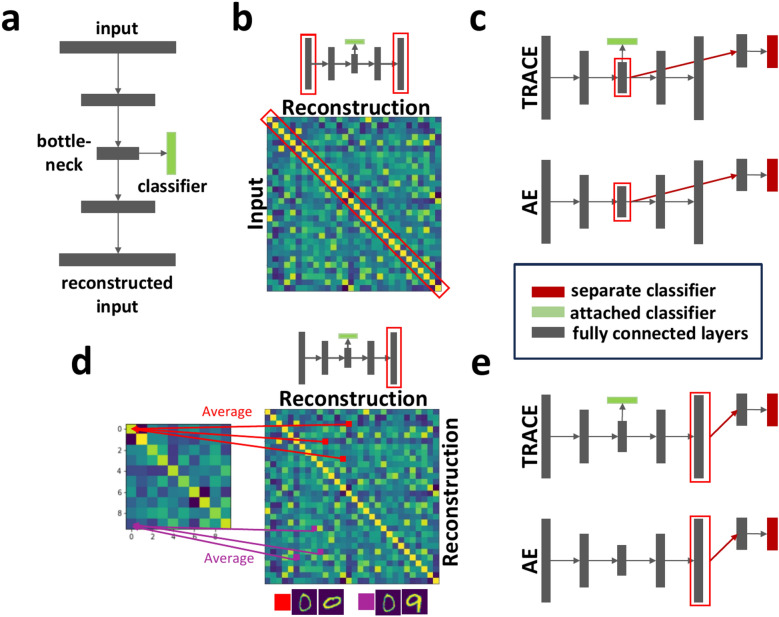


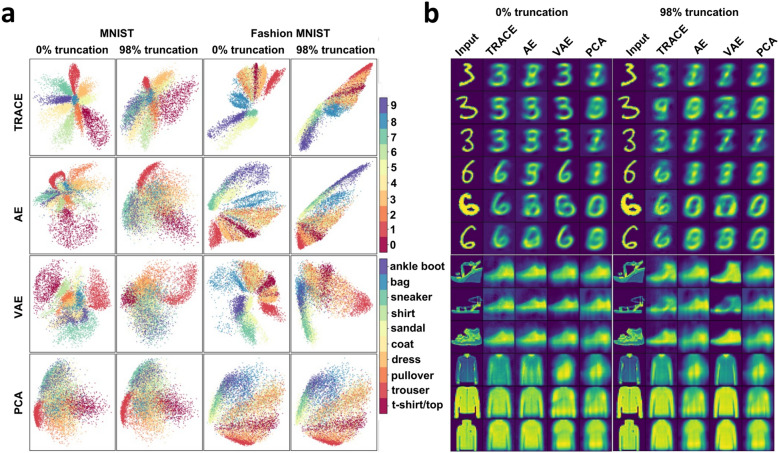
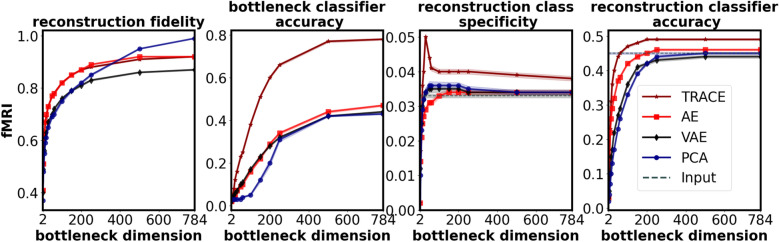
References
-
- Mannfolk, P., Wirestam, R., Nilsson, M., Ståhlberg, F. & Olsrud, J. Dimensionality reduction of fMRI time series data using locally linear embedding. MAGMA23, 327–338 (2010). - PubMed
-
- P.-H. (cameron) Chen, et al., A Reduced-Dimension fMRI Shared Response Model in Advances, In: Neural Information Processing Systems, C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, R. Garnett, (Eds). (Curran Associates, Inc., London), (2015).
