

Machine learning-driven risk assessment of coronary heart disease: Analysis of NHANES data from 1999 to 2018
- PMID: 39788507
- PMCID: PMC11628228
- DOI: 10.11817/j.issn.1672-7347.2024.240394
Machine learning-driven risk assessment of coronary heart disease: Analysis of NHANES data from 1999 to 2018
Abstract
Objectives: The high incidence of coronary artery heart disease (CHD) poses a significant burden and challenge to public health systems globally. Effective prevention and early diagnosis of CHD have become key strategies to alleviate this burden. This study aims to explore the application of advanced machine learning techniques to enhance the accuracy of early screening and risk assessment for CHD.
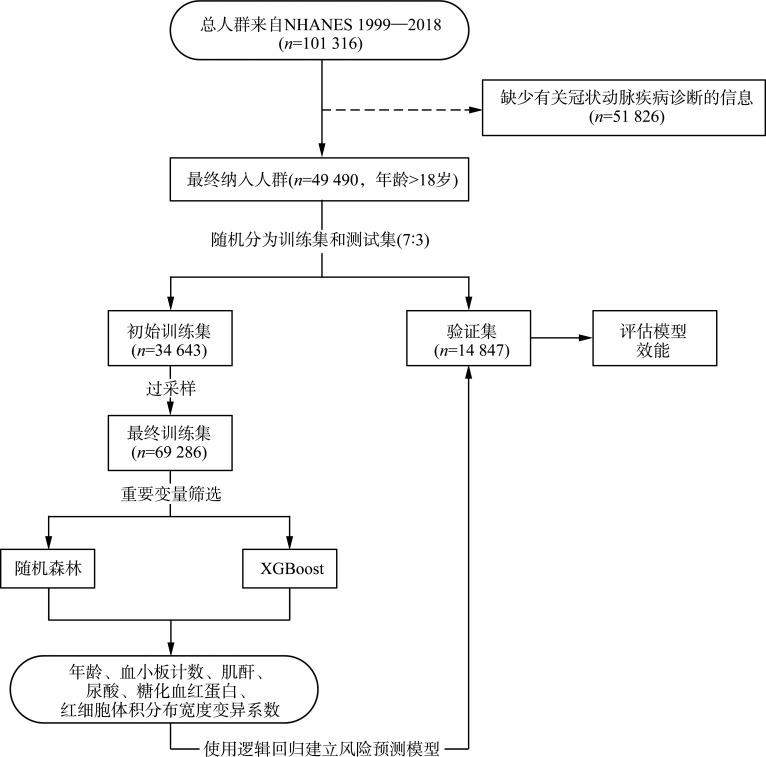
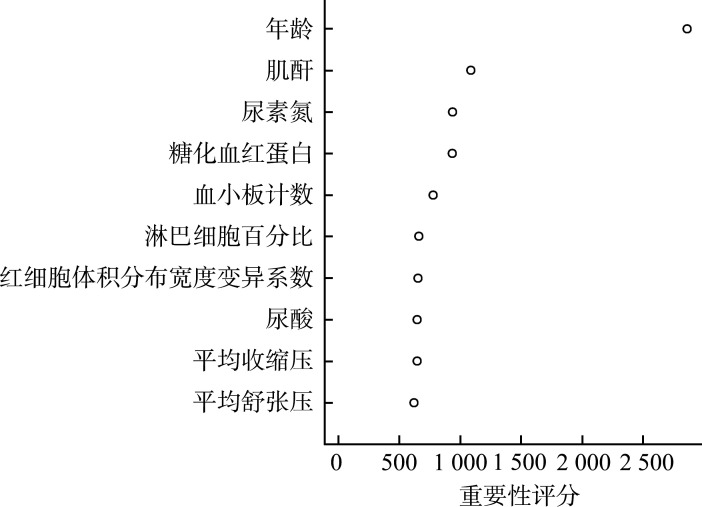
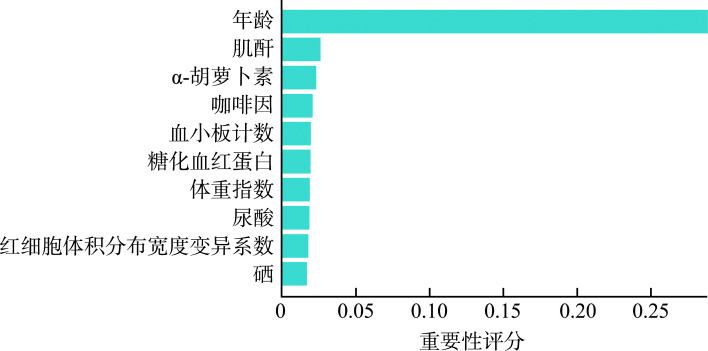
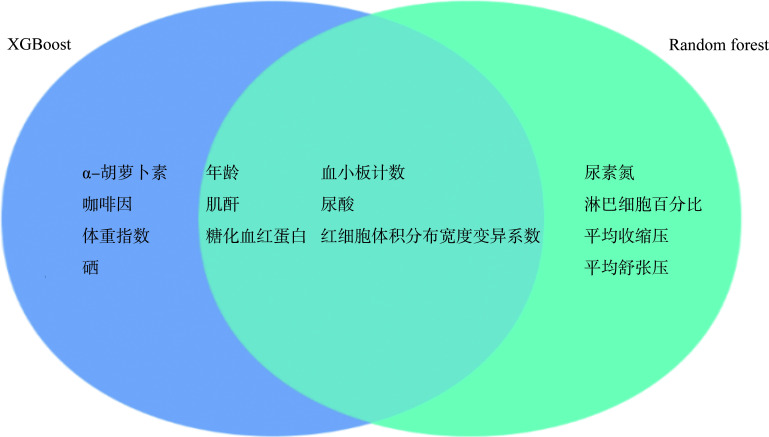
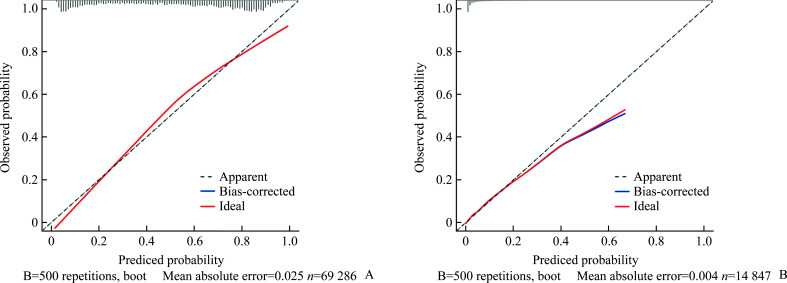
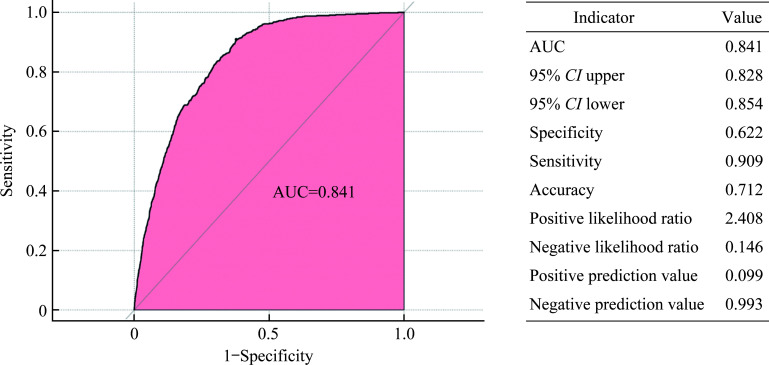
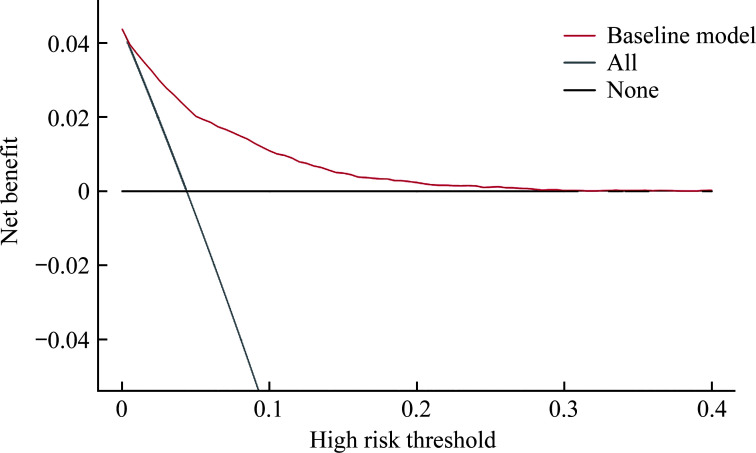
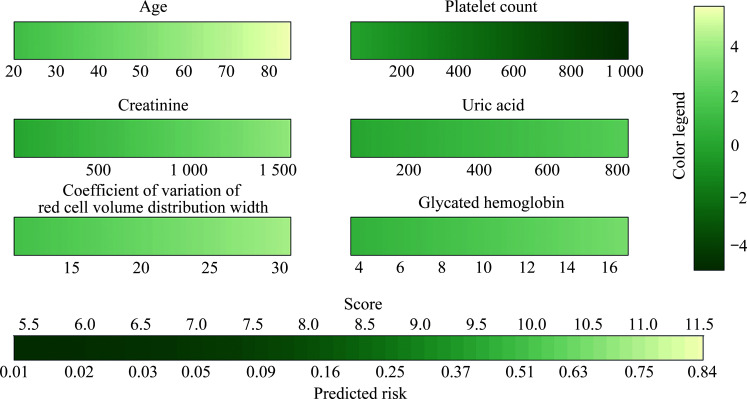
Methods: A total of 49 490 study subjects from the National Health and Nutrition Examination Survey (NHANES) database spanning from 1999 to 2018 were included. The dataset was randomly divided into training (70%) and testing (30%) sets. The dependent variable (outcome variable) was whether the subjects were informed of a CHD diagnosis, categorizing them into a CHD group and a non-CHD group. We reviewed the literature on risk factors associated with CHD, ultimately including 68 independent variables. The variable characteristics of the study subjects were analyzed, comparing differences between the CHD and non-CHD groups. Machine learning algorithms, specifically random forest (randomForest_4.7-1.1) and XGBoost (xgboost_1.7.7.1) were utilized for variable selection. A comprehensive analysis of the top 10 variables identified by these 2 algorithms were conducted, selecting those mutually recognized by both. A generalized linear model was used to analyze the relationships between variables and CHD, and classical logistic regression was used to construct the CHD risk prediction model. The model's ability to distinguish between CHD and non-CHD individuals was assessed using the area under the receiver operating characteristic curve (AUC); calibration measurements were conducted with the Hosmer-Lemeshow goodness-of-fit test to evaluate the consistency between predicted values and actual CHD proportions; and decision curve analysis was applied to evaluate the clinical benefits of the model's risk prediction. Finally, a nomogram was constructed to visually present the risk scoring of the final model.
Results: The mean age of the overall population was (49.53±18.31) years, with males comprising 51.8%. Compared to the non-CHD group, the CHD group was older [(69.05± 11.32) years vs (48.67±18.07) years, P<0.001], had a higher proportion of females (67.1% vs 47.4%, P<0.001), and exhibited statistically significant differences in classical cardiovascular risk factors such as body mass index, systolic blood pressure, diastolic blood pressure, and smoking (all P<0.001). Additionally, there were statistically significant differences in non-classical cardiovascular factors, such as energy intake, vitamins E, vitamin K, calcium, phosphorus, magnesium, zinc, copper, sodium, potassium, and selenium (all P<0.05). Six key variables most associated with CHD occurrence were ultimately identified. The CHD risk prediction model constructed was as follows: logit(p)= -7.783+0.074×age+0.003×creatinine-0.003×platelets+0.257×glycated hemoglobin+0.003× uric acid+0.101×coefficient of variation of red cell distribution width. The model demonstrated excellent discriminative ability in predicting CHD, with an accuracy of 0.712 and an AUC of 0.841. Calibration curves indicated good consistency between predicted probabilities and actual values in both the training and testing sets, demonstrating model stability and reliability. Decision curve analysis suggested that the model provided net benefits across a range of threshold probabilities, supporting its potential application in clinical decision-making.
Conclusions: This study successfully identified potential risk factors for CHD using machine learning techniques and developed a concise and practical clinical prediction model. Further prospective clinical cohort studies are needed to validate its potential for clinical application, enabling effective cardiovascular disease prevention and intervention strategies in real-world healthcare settings.
目的: 全球冠心病(coronary artery heart disease,CHD)发病率居高不下,给公共卫生系统带来了极大的负担和挑战。有效预防和早期诊断CHD成为减轻这一负担的关键策略。本研究致力于探索运用先进的机器学习技术来提高CHD早期筛查和风险评估的准确性。方法: 纳入美国国家卫生和营养调查(National Health and Nutrition Examination Survey,NHANES)数据库1999至2018年49 490名研究对象,将数据集按7꞉3划分为训练集和测试集。以研究对象是否被告知患有CHD为因变量(输出变量),并以此为依据分为CHD组和非CHD组。通过查阅CHD相关危险因素的文献,最终纳入68个自变量。分析研究对象的变量特征,并比较其在CHD组与非CHD组之间差异。采用机器学习算法随机森林(randomForest_4.7-1.1)和XGBoost(xgboost_1.7.7.1)进行变量选择。综合分析这2种算法识别出的重要性排名前10的变量,选取这2个算法共同认定的变量。使用广义线性模型来分析变量与CHD之间的关系,采用经典的逻辑回归构建CHD风险预测模型。使用受试者操作特征(receiver operating characteristic,ROC)曲线下面积(area under curve,AUC)评估模型在区分CHD和非CHD个体方面的能力;采用Hosmer-Lemeshow拟合优度检验进行校准测量,评估预测值与实际CHD比例之间的一致性;应用决策曲线评估模型风险预测的临床益处;采用诺谟图直观展示最终模型风险评分。结果: 总人群的年龄为(49.53±18.31)岁,男性占51.8%。与非CHD组相比,CHD组患者的年龄较大[(69.05±11.32)岁 vs (48.67±18.07)岁,P<0.001],女性比例更高(67.1% vs 47.4%,P<0.001),且在体重指数、收缩压、舒张压和吸烟等经典心血管危险因素上的差异均有统计学意义(均P<0.001)。此外,CHD组与非CHD组在能量摄入量、维生素E、维生素K、钙、磷、镁、锌、铜、钠、钾、硒等非经典心血管影响因素上的差异也均有统计学意义(均P<0.05)。最终确定了6个与CHD发生最相关的关键变量。并构建CHD风险预测模型如下:logit(p)=-7.783+0.074×年龄+0.003×肌酐-0.003×血小板+0.257×糖化血糖蛋白+0.003×尿酸+0.101×红细胞体积分布宽度变异系数。模型在预测CHD方面表现出优异的判别能力,其准确度为0.712,AUC值为0.841。校准曲线显示在训练集和测试集中,预测概率与实际值之间有良好的一致性,表明模型稳定、可靠。决策曲线表明该模型在不同阈值概率范围内提供了净效益,支持其在临床决策中的应用潜力。结论: 本研究利用机器学习技术识别可能的CHD风险因素,并成功开发了一个简洁且实用的临床预测模型。未来需要进一步前瞻性临床队列研究验证其在临床应用中的潜力,使其能够在实际医疗环境中提供有效的心血管疾病预防和干预策略。.
Keywords: National Health and Nutrition Examination Survey; coronary artery heart disease; machine learning; risk assessment; risk factors.
Conflict of interest statement
作者声称无任何利益冲突。
Figures
Similar articles
-
Development and validation of a prediction model for coronary heart disease risk in depressed patients aged 20 years and older using machine learning algorithms.Front Cardiovasc Med. 2025 Jan 9;11:1504957. doi: 10.3389/fcvm.2024.1504957. eCollection 2024. Front Cardiovasc Med. 2025. PMID: 39850379 Free PMC article.
-
Application of machine learning algorithms to construct and validate a prediction model for coronary heart disease risk in patients with periodontitis: a population-based study.Front Cardiovasc Med. 2023 Nov 29;10:1296405. doi: 10.3389/fcvm.2023.1296405. eCollection 2023. Front Cardiovasc Med. 2023. PMID: 38094122 Free PMC article.
-
Machine Learning Analysis of Nutrient Associations with Peripheral Arterial Disease: Insights from NHANES 1999-2004.Ann Vasc Surg. 2025 May;114:154-162. doi: 10.1016/j.avsg.2024.12.077. Epub 2025 Jan 30. Ann Vasc Surg. 2025. PMID: 39892831
-
The CMLA score: A novel tool for early prediction of renal replacement therapy in patients with cardiogenic shock.Curr Probl Cardiol. 2024 Dec;49(12):102870. doi: 10.1016/j.cpcardiol.2024.102870. Epub 2024 Sep 27. Curr Probl Cardiol. 2024. PMID: 39343053 Review.
-
Machine learning in predicting heart failure survival: a review of current models and future prospects.Heart Fail Rev. 2025 Mar;30(2):431-442. doi: 10.1007/s10741-024-10474-y. Epub 2024 Dec 10. Heart Fail Rev. 2025. PMID: 39656330 Review.
References
-
- Writing Committee Members, Lawton JS, Tamis-Holland JE, et al. . 2021 ACC/AHA/SCAI guideline for coronary artery revascularization: executive summary: a report of the American college of cardiology/American heart association joint committee on clinical practice guidelines[J]. J Am Coll Cardiol, 2022, 79(2): 197-215. 10.1016/j.jacc.2021.09.005. - DOI - PubMed
-
- 中国心血管健康疾病报告撰写委员会 . 《中国心血管健康与疾病报告2022》要点解读[J]. 中国心血管杂志, 2023, 28(4): 297-312. 10.3969/j.issn.1007-5410.2023.04.001. - DOI
- The Writing Committee of the Report on Cardiovascular Health Diseases in China . Interpretation of report on cardiovascular health and diseases in China 2022[J]. Chinese Journal of Cardiovascular Medicine, 2023, 28(4): 297-312. 10.3969/j.issn.1007-5410.2023.04.001. - DOI
MeSH terms
LinkOut - more resources
Full Text Sources
