

Patient- and clinician-based evaluation of large language models for patient education in prostate cancer radiotherapy
- PMID: 39792259
- PMCID: PMC11839798
- DOI: 10.1007/s00066-024-02342-3
Patient- and clinician-based evaluation of large language models for patient education in prostate cancer radiotherapy
Abstract
Background: This study aims to evaluate the capabilities and limitations of large language models (LLMs) for providing patient education for men undergoing radiotherapy for localized prostate cancer, incorporating assessments from both clinicians and patients.
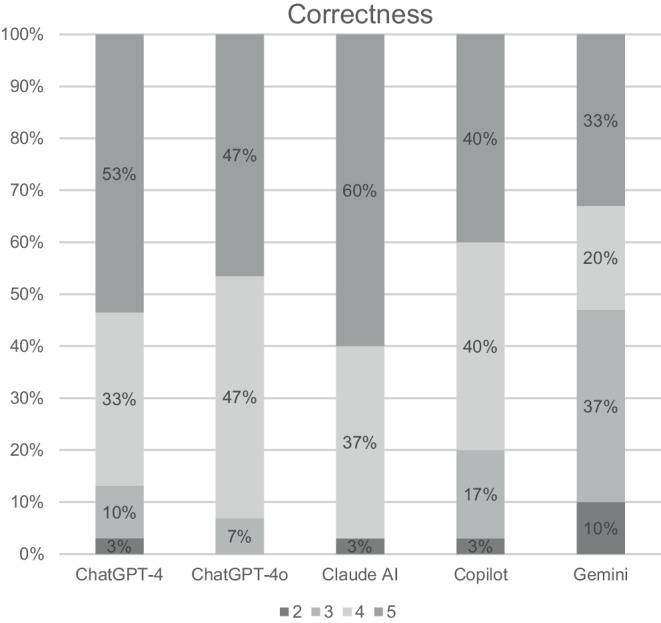
Methods: Six questions about definitive radiotherapy for prostate cancer were designed based on common patient inquiries. These questions were presented to different LLMs [ChatGPT‑4, ChatGPT-4o (both OpenAI Inc., San Francisco, CA, USA), Gemini (Google LLC, Mountain View, CA, USA), Copilot (Microsoft Corp., Redmond, WA, USA), and Claude (Anthropic PBC, San Francisco, CA, USA)] via the respective web interfaces. Responses were evaluated for readability using the Flesch Reading Ease Index. Five radiation oncologists assessed the responses for relevance, correctness, and completeness using a five-point Likert scale. Additionally, 35 prostate cancer patients evaluated the responses from ChatGPT‑4 for comprehensibility, accuracy, relevance, trustworthiness, and overall informativeness.
Results: The Flesch Reading Ease Index indicated that the responses from all LLMs were relatively difficult to understand. All LLMs provided answers that clinicians found to be generally relevant and correct. The answers from ChatGPT‑4, ChatGPT-4o, and Claude AI were also found to be complete. However, we found significant differences between the performance of different LLMs regarding relevance and completeness. Some answers lacked detail or contained inaccuracies. Patients perceived the information as easy to understand and relevant, with most expressing confidence in the information and a willingness to use ChatGPT‑4 for future medical questions. ChatGPT-4's responses helped patients feel better informed, despite the initially standardized information provided.
Conclusion: Overall, LLMs show promise as a tool for patient education in prostate cancer radiotherapy. While improvements are needed in terms of accuracy and readability, positive feedback from clinicians and patients suggests that LLMs can enhance patient understanding and engagement. Further research is essential to fully realize the potential of artificial intelligence in patient education.
Keywords: AI; Artificial intelligence; ChatGPT; Patient information; Radiation oncology.
© 2025. The Author(s).
Conflict of interest statement
Declarations. Conflict of interest: C. Trapp, N. Schmidt-Hegemann, M. Keilholz, S.F. Brose, S.N. Marschner, S. Schönecker, S.H. Maier, D.-C. Dehelean, M. Rottler, D. Konnerth, C. Belka, S. Corradini, and P. Rogowski declare that they have no competing interests. Ethical standards: All procedures performed in studies involving human participants or on human tissue were in accordance with the ethical standards of the institutional and/or national research committee and with the 1975 Helsinki declaration and its later amendments or comparable ethical standards. Informed consent was obtained from all individual participants included in the study.
Figures




References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
