

Proficiency, Clarity, and Objectivity of Large Language Models Versus Specialists' Knowledge on COVID-19's Impacts in Pregnancy: Cross-Sectional Pilot Study
- PMID: 39794312
- PMCID: PMC11840386
- DOI: 10.2196/56126
Proficiency, Clarity, and Objectivity of Large Language Models Versus Specialists' Knowledge on COVID-19's Impacts in Pregnancy: Cross-Sectional Pilot Study
Abstract
Background: The COVID-19 pandemic has significantly strained health care systems globally, leading to an overwhelming influx of patients and exacerbating resource limitations. Concurrently, an "infodemic" of misinformation, particularly prevalent in women's health, has emerged. This challenge has been pivotal for health care providers, especially gynecologists and obstetricians, in managing pregnant women's health. The pandemic heightened risks for pregnant women from COVID-19, necessitating balanced advice from specialists on vaccine safety versus known risks. In addition, the advent of generative artificial intelligence (AI), such as large language models (LLMs), offers promising support in health care. However, they necessitate rigorous testing.
Objective: This study aimed to assess LLMs' proficiency, clarity, and objectivity regarding COVID-19's impacts on pregnancy.
Methods: This study evaluates 4 major AI prototypes (ChatGPT-3.5, ChatGPT-4, Microsoft Copilot, and Google Bard) using zero-shot prompts in a questionnaire validated among 159 Israeli gynecologists and obstetricians. The questionnaire assesses proficiency in providing accurate information on COVID-19 in relation to pregnancy. Text-mining, sentiment analysis, and readability (Flesch-Kincaid grade level and Flesch Reading Ease Score) were also conducted.
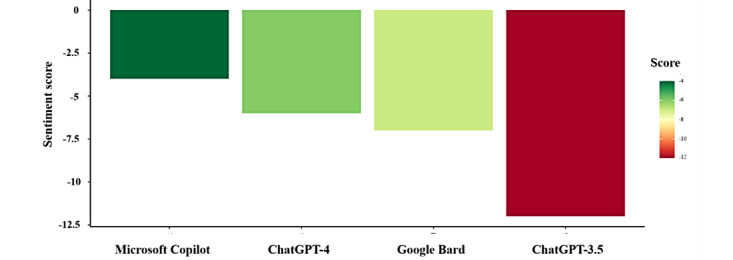
Results: In terms of LLMs' knowledge, ChatGPT-4 and Microsoft Copilot each scored 97% (32/33), Google Bard 94% (31/33), and ChatGPT-3.5 82% (27/33). ChatGPT-4 incorrectly stated an increased risk of miscarriage due to COVID-19. Google Bard and Microsoft Copilot had minor inaccuracies concerning COVID-19 transmission and complications. In the sentiment analysis, Microsoft Copilot achieved the least negative score (-4), followed by ChatGPT-4 (-6) and Google Bard (-7), while ChatGPT-3.5 obtained the most negative score (-12). Finally, concerning the readability analysis, Flesch-Kincaid Grade Level and Flesch Reading Ease Score showed that Microsoft Copilot was the most accessible at 9.9 and 49, followed by ChatGPT-4 at 12.4 and 37.1, while ChatGPT-3.5 (12.9 and 35.6) and Google Bard (12.9 and 35.8) generated particularly complex responses.
Conclusions: The study highlights varying knowledge levels of LLMs in relation to COVID-19 and pregnancy. ChatGPT-3.5 showed the least knowledge and alignment with scientific evidence. Readability and complexity analyses suggest that each AI's approach was tailored to specific audiences, with ChatGPT versions being more suitable for specialized readers and Microsoft Copilot for the general public. Sentiment analysis revealed notable variations in the way LLMs communicated critical information, underscoring the essential role of neutral and objective health care communication in ensuring that pregnant women, particularly vulnerable during the COVID-19 pandemic, receive accurate and reassuring guidance. Overall, ChatGPT-4, Microsoft Copilot, and Google Bard generally provided accurate, updated information on COVID-19 and vaccines in maternal and fetal health, aligning with health guidelines. The study demonstrated the potential role of AI in supplementing health care knowledge, with a need for continuous updating and verification of AI knowledge bases. The choice of AI tool should consider the target audience and required information detail level.
Keywords: COVID-19; accuracy; chatGPT; generative artificial intelligence; google bard; gynecology; infectious; large language model; microsoft copilot; natural language processing; obstetric; pregnancy; readability; reproductive health; sentiment; text mining; vaccination; vaccine; women; zero shot.
©Nicola Luigi Bragazzi, Michèle Buchinger, Hisham Atwan, Ruba Tuma, Francesco Chirico, Lukasz Szarpak, Raymond Farah, Rola Khamisy-Farah. Originally published in JMIR Formative Research (https://formative.jmir.org), 05.02.2025.
Conflict of interest statement
Conflicts of Interest: None declared.
Figures
Similar articles
-
Assessing the Responses of Large Language Models (ChatGPT-4, Gemini, and Microsoft Copilot) to Frequently Asked Questions in Breast Imaging: A Study on Readability and Accuracy.Cureus. 2024 May 9;16(5):e59960. doi: 10.7759/cureus.59960. eCollection 2024 May. Cureus. 2024. PMID: 38726360 Free PMC article.
-
Appropriateness and readability of Google Bard and ChatGPT-3.5 generated responses for surgical treatment of glaucoma.Rom J Ophthalmol. 2024 Jul-Sep;68(3):243-248. doi: 10.22336/rjo.2024.45. Rom J Ophthalmol. 2024. PMID: 39464759 Free PMC article.
-
Microsoft Copilot Provides More Accurate and Reliable Information About Anterior Cruciate Ligament Injury and Repair Than ChatGPT and Google Gemini; However, No Resource Was Overall the Best.Arthrosc Sports Med Rehabil. 2024 Nov 19;7(2):101043. doi: 10.1016/j.asmr.2024.101043. eCollection 2025 Apr. Arthrosc Sports Med Rehabil. 2024. PMID: 40297090 Free PMC article.
-
Harnessing artificial intelligence in bariatric surgery: comparative analysis of ChatGPT-4, Bing, and Bard in generating clinician-level bariatric surgery recommendations.Surg Obes Relat Dis. 2024 Jul;20(7):603-608. doi: 10.1016/j.soard.2024.03.011. Epub 2024 Mar 24. Surg Obes Relat Dis. 2024. PMID: 38644078 Review.
-
Exploring the role of artificial intelligence, large language models: Comparing patient-focused information and clinical decision support capabilities to the gynecologic oncology guidelines.Int J Gynaecol Obstet. 2025 Feb;168(2):419-427. doi: 10.1002/ijgo.15869. Epub 2024 Aug 20. Int J Gynaecol Obstet. 2025. PMID: 39161265 Free PMC article. Review.
References
-
- Filip R, Gheorghita Puscaselu R, Anchidin-Norocel L, Dimian M, Savage WK. Global challenges to public health care systems during the COVID-19 pandemic: a review of pandemic measures and problems. J Pers Med. 2022;12(8):1295. doi: 10.3390/jpm12081295. https://www.mdpi.com/resolver?pii=jpm12081295 jpm12081295 - DOI - PMC - PubMed
-
- Forati AM, Ghose R. Geospatial analysis of misinformation in COVID-19 related tweets. Appl Geogr. 2021;133:102473. doi: 10.1016/j.apgeog.2021.102473. https://europepmc.org/abstract/MED/34103772 S0143-6228(21)00089-8 - DOI - PMC - PubMed
-
- Marquini GV, Martins SB, Oliveira LM, Dias MM, Takano CC, Sartori MGF. Effects of the COVID-19 pandemic on gynecological health: an integrative review. Rev Bras Ginecol Obstet. 2022;44(2):194–200. doi: 10.1055/s-0042-1742294. https://europepmc.org/abstract/MED/35213918 - DOI - PMC - PubMed
-
- Alberca RW, Pereira NZ, Oliveira LMDS, Gozzi-Silva SC, Sato MN. Pregnancy, viral infection, and COVID-19. Front Immunol. 2020;11:1672. doi: 10.3389/fimmu.2020.01672. https://europepmc.org/abstract/MED/32733490 - DOI - PMC - PubMed
-
- Hanna N, Hanna M, Sharma S. Is pregnancy an immunological contributor to severe or controlled COVID-19 disease? Am J Reprod Immunol. 2020;84(5):e13317. doi: 10.1111/aji.13317. https://europepmc.org/abstract/MED/32757366 - DOI - PMC - PubMed
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
