

The sociolinguistic foundations of language modeling
- PMID: 39871863
- PMCID: PMC11770026
- DOI: 10.3389/frai.2024.1472411
The sociolinguistic foundations of language modeling
Abstract
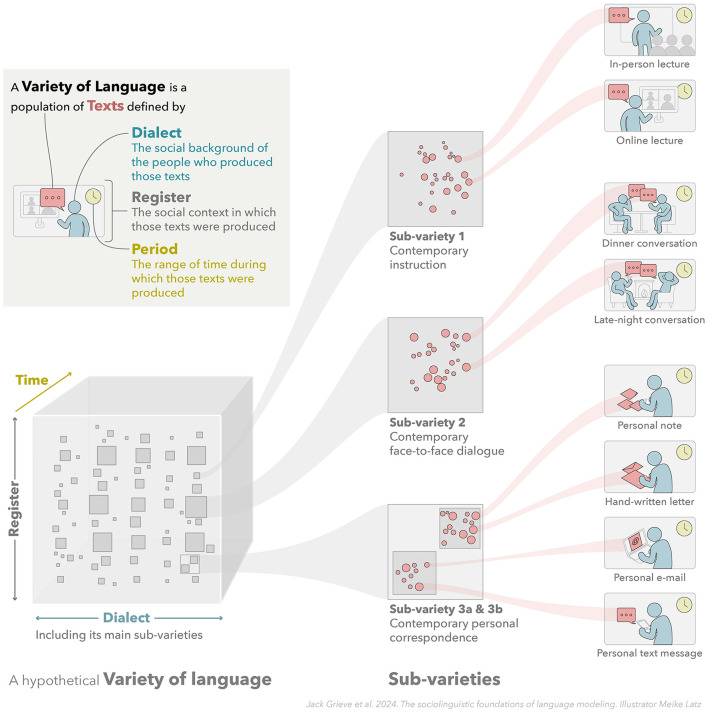
In this article, we introduce a sociolinguistic perspective on language modeling. We claim that language models in general are inherently modeling varieties of language, and we consider how this insight can inform the development and deployment of language models. We begin by presenting a technical definition of the concept of a variety of language as developed in sociolinguistics. We then discuss how this perspective could help us better understand five basic challenges in language modeling: social bias, domain adaptation, alignment, language change, and scale. We argue that to maximize the performance and societal value of language models it is important to carefully compile training corpora that accurately represent the specific varieties of language being modeled, drawing on theories, methods, and descriptions from the field of sociolinguistics.
Keywords: AI ethics; artificial intelligence; computational sociolinguistics; corpus linguistics; large language models; natural language processing; varieties of language.
Copyright © 2025 Grieve, Bartl, Fuoli, Grafmiller, Huang, Jawerbaum, Murakami, Perlman, Roemling and Winter.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest. The author(s) declared that they were an editorial board member of Frontiers, at the time of submission. This had no impact on the peer review process and the final decision.
Figures



References
-
- Achiam J., Adler S., Agarwal S., Ahmad L., Akkaya I., Aleman F. L., et al. . (2023). Gpt-4 technical report. arXiv [preprint] arXiv:2303.08774. 10.48550/arXiv.2303.08774 - DOI
-
- Aggarwal D., Sathe A., Sitaram S. (2024). Exploring pretraining via active forgetting for improving cross lingual transfer for decoder language models. arXiv [preprint] arXiv:2410.16168. 10.48550/arXiv.2410.16168 - DOI
-
- Aitken A. J. (1985). Is scots a language? English Today 1, 41–45. 10.1017/S0266078400001292 - DOI
-
- Baack S. (2024). “A critical analysis of the largest source for generative ai training data: Common crawl,” in The 2024 ACM Conference on Fairness, Accountability, and Transparency (Rio de Janeiro: Association for Computing Machinery; ), 2199–2208.
Publication types
LinkOut - more resources
Full Text Sources