

Expanding the human gut microbiome atlas of Africa
- PMID: 39880958
- PMCID: PMC11839480
- DOI: 10.1038/s41586-024-08485-8
Expanding the human gut microbiome atlas of Africa
Abstract
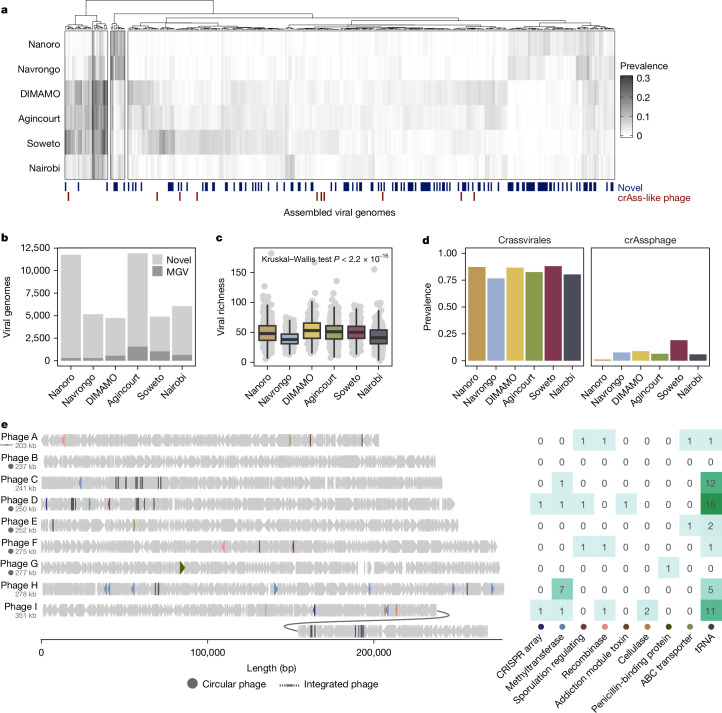
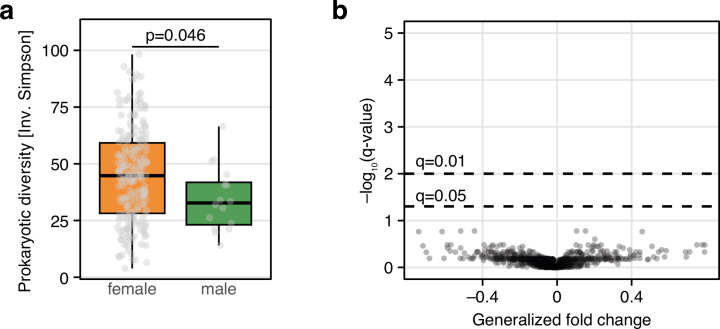
Population studies provide insights into the interplay between the gut microbiome and geographical, lifestyle, genetic and environmental factors. However, low- and middle-income countries, in which approximately 84% of the world's population lives1, are not equitably represented in large-scale gut microbiome research2-4. Here we present the AWI-Gen 2 Microbiome Project, a cross-sectional gut microbiome study sampling 1,801 women from Burkina Faso, Ghana, Kenya and South Africa. By engaging with communities that range from rural and horticultural to post-industrial and urban informal settlements, we capture a far greater breadth of the world's population diversity. Using shotgun metagenomic sequencing, we identify taxa with geographic and lifestyle associations, including Treponema and Cryptobacteroides species loss and Bifidobacterium species gain in urban populations. We uncover 1,005 bacterial metagenome-assembled genomes, and we identify antibiotic susceptibility as a factor that might drive Treponema succinifaciens absence in urban populations. Finally, we find an HIV infection signature defined by several taxa not previously associated with HIV, including Dysosmobacter welbionis and Enterocloster sp. This study represents the largest population-representative survey of gut metagenomes of African individuals so far, and paired with extensive clinical biomarkers and demographic data, provides extensive opportunity for microbiome-related discovery.
© 2025. The Author(s).
Conflict of interest statement
Competing interests: The authors declare no competing interests.
Figures












Update of
-
Expanding the human gut microbiome atlas of Africa.bioRxiv [Preprint]. 2024 Mar 14:2024.03.13.584859. doi: 10.1101/2024.03.13.584859. bioRxiv. 2024. Update in: Nature. 2025 Feb;638(8051):718-728. doi: 10.1038/s41586-024-08485-8. PMID: 38559015 Free PMC article. Updated. Preprint.
References
-
- World Bank Open Data. Population, total – Low & middle income, High income.https://data.worldbank.org/indicator/SP.POP.TOTL?locations=XO-XD (2023).
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
