

Hearing in categories and speech perception at the "cocktail party"
- PMID: 39883695
- PMCID: PMC11781644
- DOI: 10.1371/journal.pone.0318600
Hearing in categories and speech perception at the "cocktail party"
Abstract
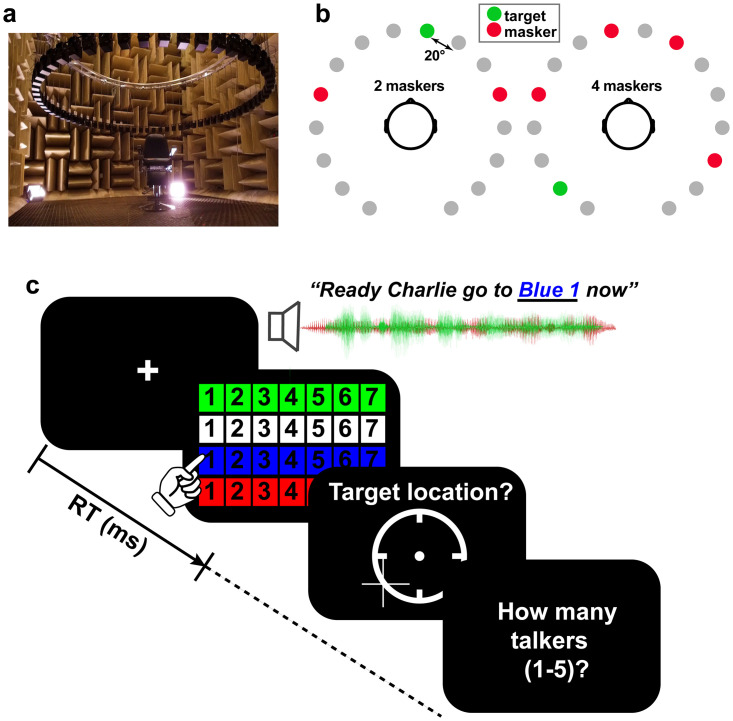
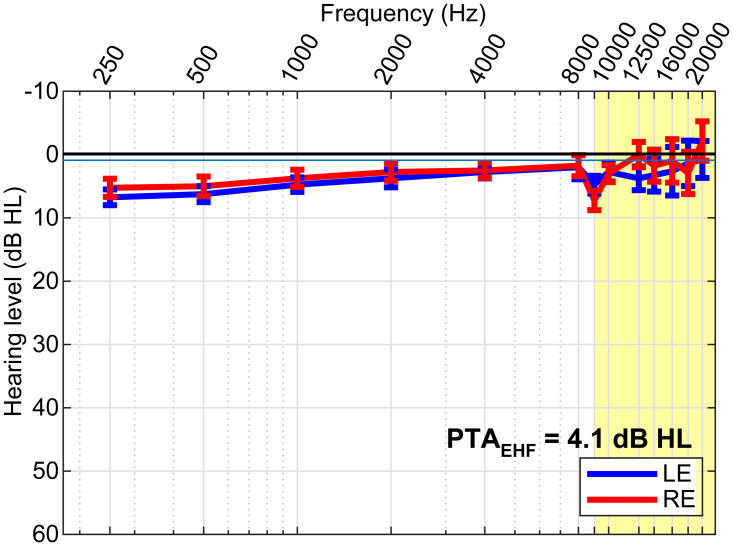
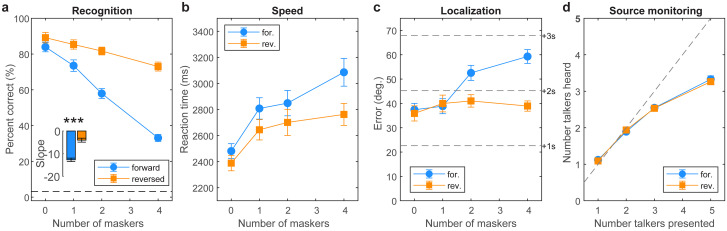
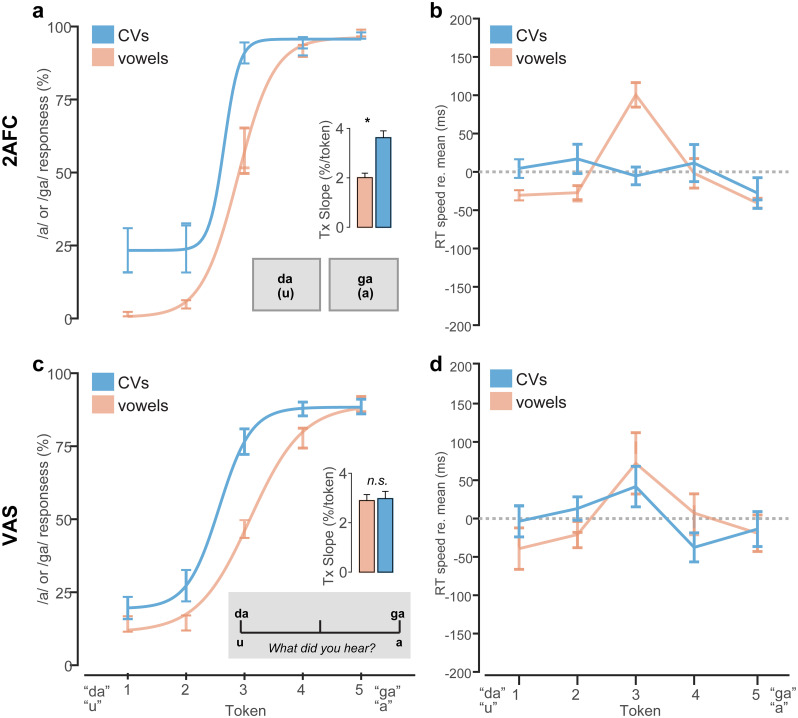
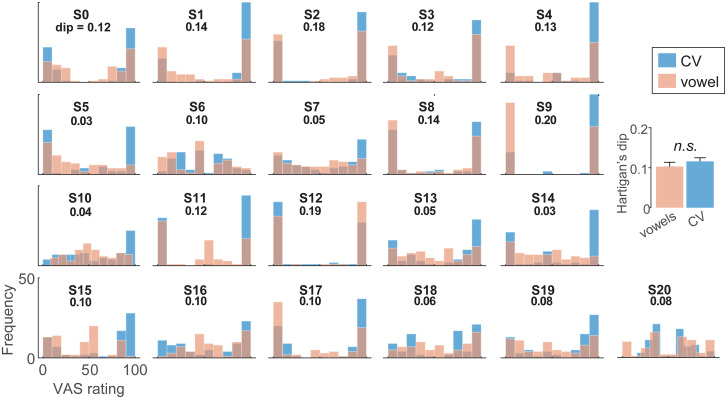
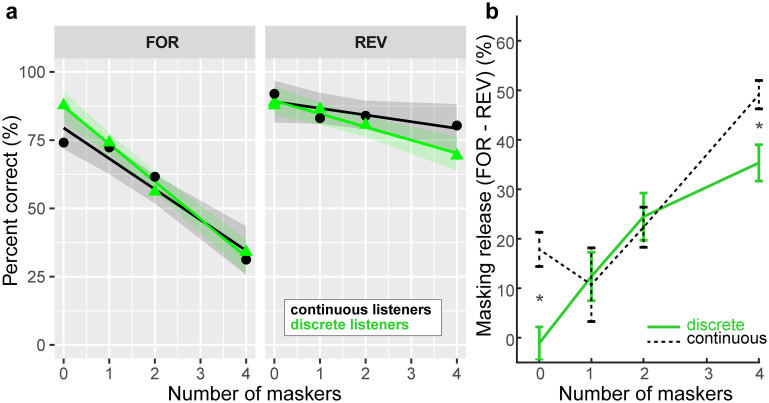
We aimed to test whether hearing speech in phonetic categories (as opposed to a continuous/gradient fashion) affords benefits to "cocktail party" speech perception. We measured speech perception performance (recognition, localization, and source monitoring) in a simulated 3D cocktail party environment. We manipulated task difficulty by varying the number of additional maskers presented at other spatial locations in the horizontal soundfield (1-4 talkers) and via forward vs. time-reversed maskers, the latter promoting a release from masking. In separate tasks, we measured isolated phoneme categorization using two-alternative forced choice (2AFC) and visual analog scaling (VAS) tasks designed to promote more/less categorical hearing and thus test putative links between categorization and real-world speech-in-noise skills. We first show cocktail party speech recognition accuracy and speed decline with additional competing talkers and amidst forward compared to reverse maskers. Dividing listeners into "discrete" vs. "continuous" categorizers based on their VAS labeling (i.e., whether responses were binary or continuous judgments), we then show the degree of release from masking experienced at the cocktail party is predicted by their degree of categoricity in phoneme labeling and not high-frequency audiometric thresholds; more discrete listeners make less effective use of time-reversal and show less release from masking than their gradient responding peers. Our results suggest a link between speech categorization skills and cocktail party processing, with a gradient (rather than discrete) listening strategy benefiting degraded speech perception. These findings suggest that less flexibility in binning sounds into categories may be one factor that contributes to figure-ground deficits.
Copyright: © 2025 Bidelman et al. This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
References
-
- Siegel JA, Siegel W. Absolute identification of notes and intervals by musicians. Percept Psychophys. 1977;21(2):143–52.
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
