

This is a preprint.
A Generalist Intracortical Motor Decoder
- PMID: 39975007
- PMCID: PMC11838490
- DOI: 10.1101/2025.02.02.634313
A Generalist Intracortical Motor Decoder
Abstract
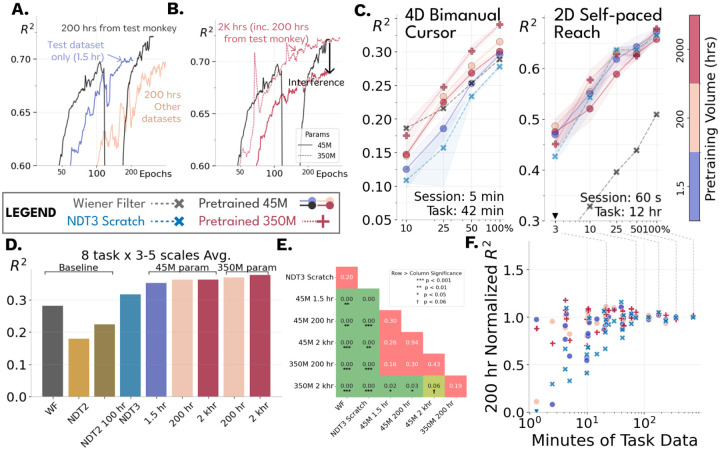
Mapping the relationship between neural activity and motor behavior is a central aim of sensorimotor neuroscience and neurotechnology. While most progress to this end has relied on restricting complexity, the advent of foundation models instead proposes integrating a breadth of data as an alternate avenue for broadly advancing downstream modeling. We quantify this premise for motor decoding from intracortical microelectrode data, pretraining an autoregressive Transformer on 2000 hours of neural population spiking activity paired with diverse motor covariates from over 30 monkeys and humans. The resulting model is broadly useful, benefiting decoding on 8 downstream decoding tasks and generalizing to a variety of neural distribution shifts. However, we also highlight that scaling autoregressive Transformers seems unlikely to resolve limitations stemming from sensor variability and output stereotypy in neural datasets. Code: https://github.com/joel99/ndt3.
Figures




References
-
- Abnar S., Dehghani M., Neyshabur B., and Sedghi H.. Exploring the limits of large scale pre-training, 2021. URL https://arxiv.org/abs/2110.02095.
-
- Adelson E. H., Bergen J. R., et al. The plenoptic function and the elements of early vision, volume 2. Vision and Modeling Group, Media Laboratory, Massachusetts Institute of; …, 1991.
-
- Aghajanyan A., Yu L., Conneau A., Hsu W.-N., Hambardzumyan K., Zhang S., Roller S., Goyal N., Levy O., and Zettlemoyer L.. Scaling laws for generative mixed-modal language models. In International Conference on Machine Learning, pages 265–279. PMLR, 2023.
-
- Antonello R., Vaidya A., and Huth A. G.. Scaling laws for language encoding models in fmri, 2024. URL https://arxiv.org/abs/2305.11863. - PMC - PubMed
-
- Azabou M., Arora V., Ganesh V., Mao X., Nachimuthu S., Mendelson M., Richards B., Perich M., Lajoie G., and Dyer E.. A unified, scalable framework for neural population decoding. Advances in Neural Information Processing Systems, 36, 2024.
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources