

This is a preprint.
A Comparative Evaluation of Computational Models for RNA modification detection using Nanopore sequencing with RNA004 Chemistry
- PMID: 39975272
- PMCID: PMC11838592
- DOI: 10.1101/2025.02.03.636352
A Comparative Evaluation of Computational Models for RNA modification detection using Nanopore sequencing with RNA004 Chemistry
Update in
-
A comparative evaluation of computational models for RNA modification detection using nanopore sequencing with RNA004 chemistry.Brief Bioinform. 2025 Jul 2;26(4):bbaf404. doi: 10.1093/bib/bbaf404. Brief Bioinform. 2025. PMID: 40802798 Free PMC article.
Abstract
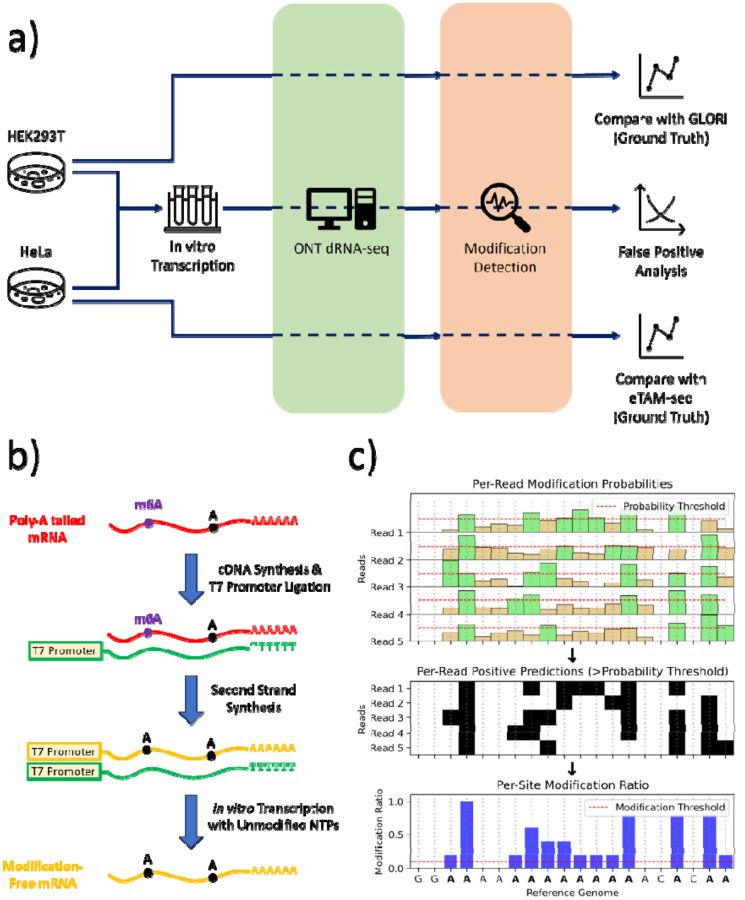
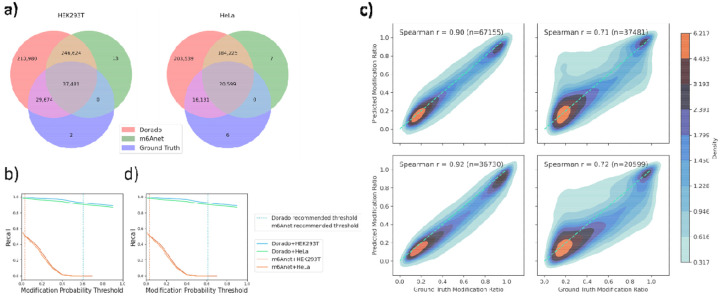
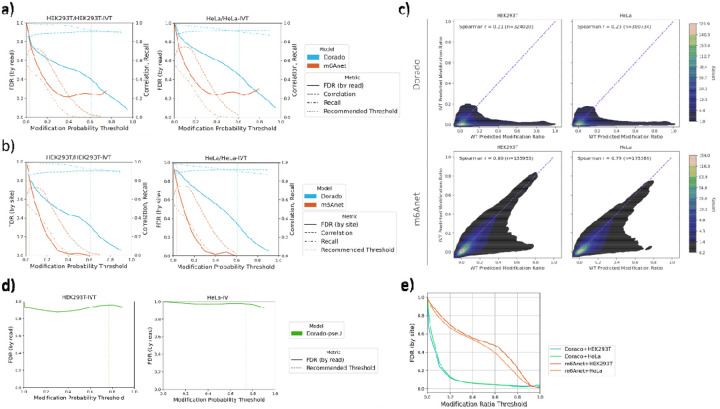
Direct RNA sequencing from Oxford Nanopore Technologies (ONT) has become a valuable method for studying RNA modifications such as N6-methyladenosine (m6A), pseudouridine (ψ), and 5-methylcytosine (m5C). Recent advancements in the RNA004 chemistry substantially reduce sequencing errors compared to previous chemistries (e.g., RNA002), thereby promising enhanced accuracy for epitranscriptomic analysis. In this study, we benchmark the performance of two state-of-the-art RNA modification detection models capable of handling RNA004 data - ONT's Dorado and m6Anet - using two wild-type (WT) cell lines, HEK293T and HeLa, with respective ground truths from GLORI and eTAM-seq, and their paired in vitro transcribed (IVT) RNA as negative controls. We found that under default settings and considering sites with ≥10% modification ratio and ≥10X coverage, Dorado has higher recall (~0.92) than m6Anet (~0.51) for m6A detection. Among the overlapping methylated sites between ground truth and computational predictions, there are high correlations of site-specific m6A modification stoichiometry, with correlation coefficient of ~0.89 for Dorado-truth comparison and ~0.72 for m6Anet-truth comparison. However, combined assessment of WT and IVT datasets show that while the per-site false positive rate (FPR) can be lower (~8% for Dorado and ~33% for m6Anet), both computational tools can have high per-site false discovery rate (FDR) of m6A (~40% for Dorado and ~80% for m6Anet) due to the low prevalence of m6A in transcriptome, with a similar trend observed for pseudouridine (~95% FDR for Dorado). Additional motif analysis reveals that both Dorado and m6Anet exhibit high heterogeneity of false positive calls across sequence contexts, suggesting that sequence contexts help determine accuracy of specific modification calls. There is also a substantial overlap of false positive calls between the two IVT samples, suggesting a post-filtering strategy to improve modification calling by compiling a set of low-confidence sites with a probabilistic model from several IVT samples across diverse cells/tissues. Our analysis highlights key strengths and limitations of the current generation of m6A detection algorithms and offers insights into optimizing thresholds and interpretability. The IVT datasets generated by the RNA004 chemistry provides a publicly available benchmark resource for further development and refinement of computational methods.
Conflict of interest statement
Competing Interests The authors declare no competing interests.
Figures



References
-
- Delaunay S, Helm M, Frye M: RNA modifications in physiology and disease: towards clinical applications. Nature Reviews Genetics 2024, 25(2):104–122. - PubMed
-
- Alfonzo JD, Brown JA, Byers PH, Cheung VG, Maraia RJ, Ross RL: A call for direct sequencing of full-length RNAs to identify all modifications. Nature Genetics 2021, 53(8):1113–1116. - PubMed
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources