

Large language models for error detection in radiology reports: a comparative analysis between closed-source and privacy-compliant open-source models
- PMID: 39979623
- PMCID: PMC12226608
- DOI: 10.1007/s00330-025-11438-y
Large language models for error detection in radiology reports: a comparative analysis between closed-source and privacy-compliant open-source models
Abstract
Purpose: Large language models (LLMs) like Generative Pre-trained Transformer 4 (GPT-4) can assist in detecting errors in radiology reports, but privacy concerns limit their clinical applicability. This study compares closed-source and privacy-compliant open-source LLMs for detecting common errors in radiology reports.
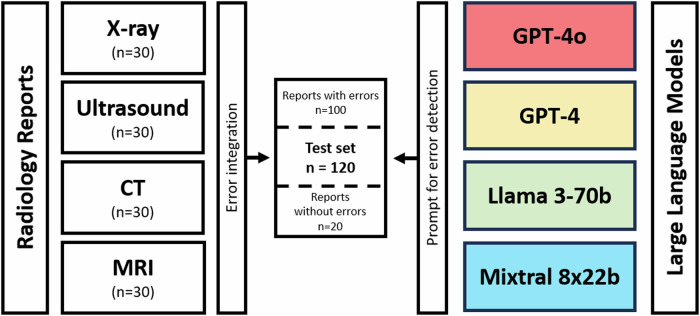
Materials and methods: A total of 120 radiology reports were compiled (30 each from X-ray, ultrasound, CT, and MRI). Subsequently, 397 errors from five categories (typographical, numerical, findings-impression discrepancies, omission/insertion, interpretation) were inserted into 100 of these reports; 20 reports were left unchanged. Two open-source models (Llama 3-70b, Mixtral 8x22b) and two commercial closed-source (GPT-4, GPT-4o) were tasked with error detection using identical prompts. The Kruskall-Wallis test and paired t-test were used for statistical analysis.
Results: Open-source LLMs required less processing time per radiology report than closed-source LLMs (6 ± 2 s vs. 13 ± 4 s; p < 0.001). Closed-source LLMs achieved higher error detection rates than open-source LLMs (GPT-4o: 88% [348/397; 95% CI: 86, 92], GPT-4: 83% [328/397; 95% CI: 80, 87], Llama 3-70b: 79% [311/397; 95% CI: 76, 83], Mixtral 8x22b: 73% [288/397; 95% CI: 68, 77]; p < 0.001). Numerical errors (88% [67/76; 95% CI: 82, 93]) were detected significantly more often than typographical errors (75% [65/86; 95% CI: 68, 82]; p = 0.02), discrepancies between findings and impression (73% [73/101; 95% CI: 67, 80]; p < 0.01), and interpretation errors (70% [50/71; 95% CI: 62, 78]; p = 0.001).
Conclusion: Open-source LLMs demonstrated effective error detection, albeit with comparatively lower accuracy than commercial closed-source models, and have potential for clinical applications when deployed via privacy-compliant local hosting solutions.
Key points: Question Can privacy-compliant open-source large language models (LLMs) match the error-detection performance of commercial non-privacy-compliant closed-source models in radiology reports? Findings Closed-source LLMs achieved slightly higher accuracy in detecting radiology report errors than open-source models, with Llama 3-70b yielding the best results among the open-source models. Clinical relevance Open-source LLMs offer a privacy-compliant alternative for automated error detection in radiology reports, improving clinical workflow efficiency while ensuring patient data confidentiality. Further refinement could enhance their accuracy, contributing to better diagnosis and patient care.
Keywords: Error detection; Generative pre-trained transformers; Large language models; Open source; Radiology reports.
© 2025. The Author(s).
Conflict of interest statement
Compliance with ethical standards. Guarantor: The scientific guarantor of this publication is Alexander Isaak, MD. Conflict of interest: The authors of this manuscript declare no relationships with any companies, whose products or services may be related to the subject matter of the article. Statistics and biometry: No complex statistical methods were necessary for this paper. Informed consent: Informed consent was not required as no patient-identifying information was used. Ethical approval: After consultation, specific approval from the institutional review board was not required as no patient-identifying information was used. Study subjects or cohorts overlap: Not applicable. Methodology: Experimental
Figures



References
-
- McDonald RJ, Schwartz KM, Eckel LJ et al (2015) The effects of changes in utilization and technological advancements of cross-sectional imaging on radiologist workload. Acad Radiol 22:1191–1198 - PubMed
-
- Quint LE, Quint DJ, Myles JD (2008) Frequency and spectrum of errors in final radiology reports generated with automatic speech recognition technology. J Am Coll Radiol 5:1196–1199 - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
