

Generalizable deep neural networks for image quality classification of cervical images
- PMID: 39984572
- PMCID: PMC11845747
- DOI: 10.1038/s41598-025-90024-0
Generalizable deep neural networks for image quality classification of cervical images
Abstract
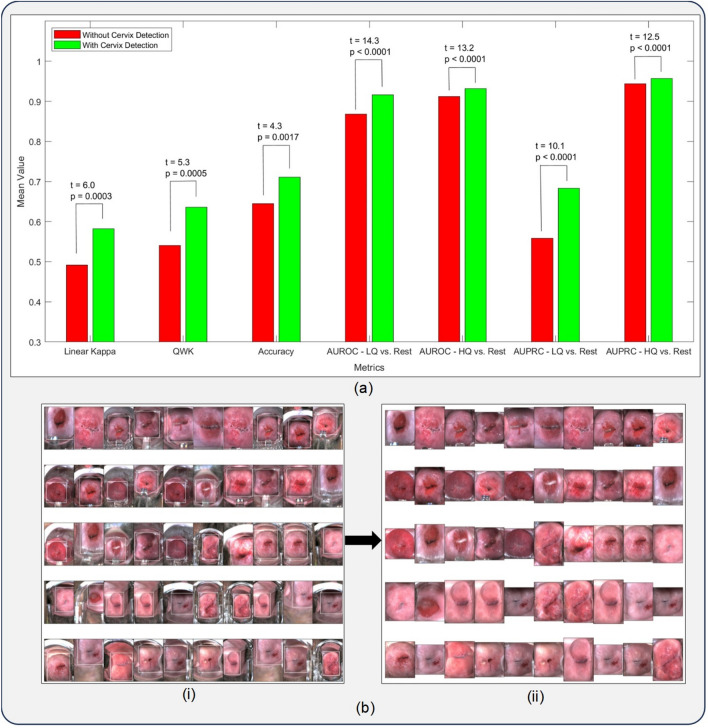
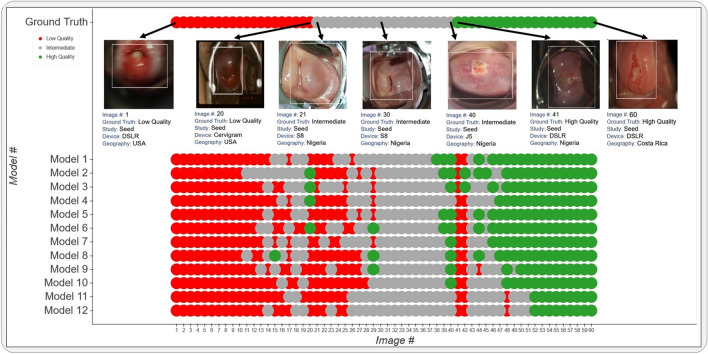
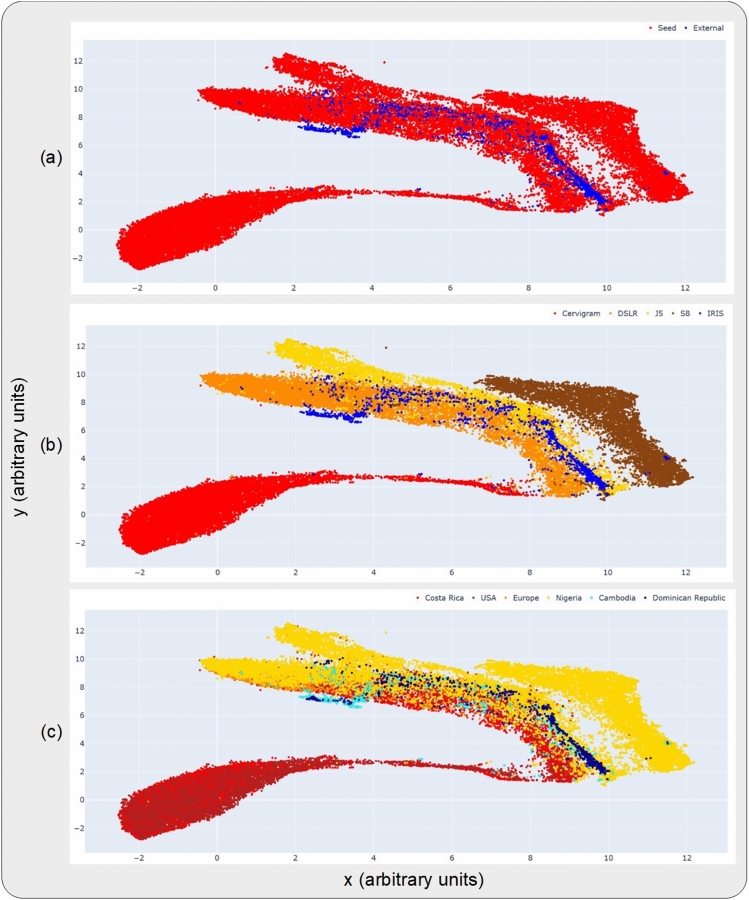
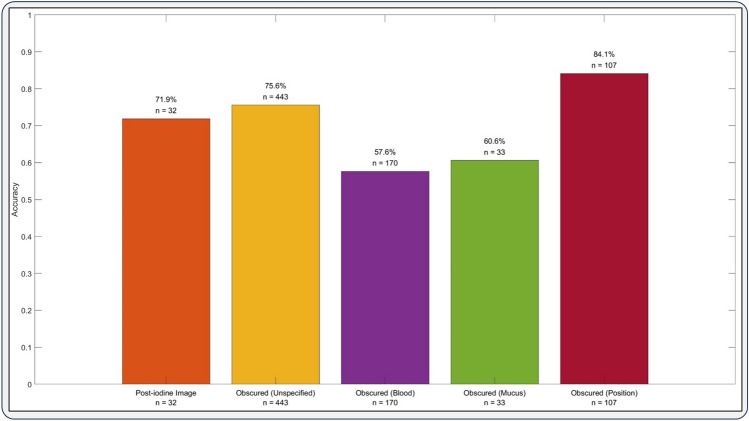
Successful translation of artificial intelligence (AI) models into clinical practice, across clinical domains, is frequently hindered by the lack of image quality control. Diagnostic models are often trained on images with no denotation of image quality in the training data; this, in turn, can lead to misclassifications by these models when implemented in the clinical setting. In the case of cervical images, quality classification is a crucial task to ensure accurate detection of precancerous lesions or cancer; this is true for both gynecologic-oncologists' (manual) and diagnostic AI models' (automated) predictions. Factors that impact the quality of a cervical image include but are not limited to blur, poor focus, poor light, noise, obscured view of the cervix due to mucus and/or blood, improper position, and over- and/or under-exposure. Utilizing a multi-level image quality ground truth denoted by providers, we generated an image quality classifier following a multi-stage model selection process that investigated several key design choices on a multi-heterogenous "SEED" dataset of 40,534 images. We subsequently validated the best model on an external dataset ("EXT"), comprising 1,340 images captured using a different device and acquired in different geographies from "SEED". We assessed the relative impact of various axes of data heterogeneity, including device, geography, and ground-truth rater on model performance. Our best performing model achieved an area under the receiver operating characteristics curve (AUROC) of 0.92 (low quality, LQ vs. rest) and 0.93 (high quality, HQ vs. rest), and a minimal total %extreme misclassification (%EM) of 2.8% on the internal validation set. Our model also generalized well externally, achieving corresponding AUROCs of 0.83 and 0.82, and %EM of 3.9% when tested out-of-the-box on the external validation ("EXT") set. Additionally, our model was geography agnostic with no meaningful difference in performance across geographies, did not exhibit catastrophic forgetting upon retraining with new data, and mimicked the overall/average ground truth rater behavior well. Our work represents one of the first efforts at generating and externally validating an image quality classifier across multiple axes of data heterogeneity to aid in visual diagnosis of cervical precancer and cancer. We hope that this will motivate the accompaniment of adequate guardrails for AI-based pipelines to account for image quality and generalizability concerns.
Keywords: Artificial intelligence; Cervical cancer screening; Deep learning; Image quality.
© 2025. The Author(s).
Conflict of interest statement
Declarations. Competing interests: The authors declare no competing interests.
Figures





References
-
- Piccialli, F., Somma, V. D., Giampaolo, F., Cuomo, S. & Fortino, G. A survey on deep learning in medicine: Why, how and when?. Inf. Fusion66, 111–137 (2021). - DOI
