

A unified hypothesis-free feature extraction framework for diverse epigenomic data
- PMID: 40078573
- PMCID: PMC11897706
- DOI: 10.1093/bioadv/vbaf013
A unified hypothesis-free feature extraction framework for diverse epigenomic data
Abstract
Motivation: Epigenetic assays using next-generation sequencing have furthered our understanding of the functional genomic regions and the mechanisms of gene regulation. However, a single assay produces billions of data points, with limited information about the biological process due to numerous sources of technical and biological noise. To draw biological conclusions, numerous specialized algorithms have been proposed to summarize the data into higher-order patterns, such as peak calling and the discovery of differentially methylated regions. The key principle underlying these approaches is the search for locally consistent patterns.
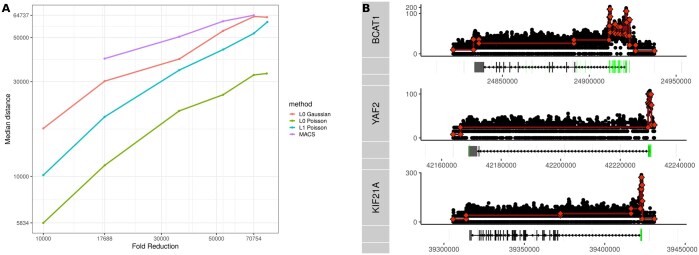
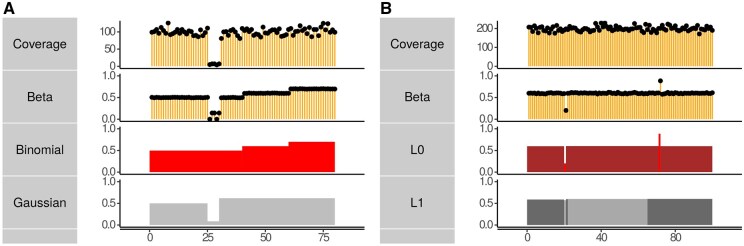
Results: We propose segmentation as a universal framework for extracting locally coherent signals for diverse epigenetic sources. serves to compress the input signal by approximating it as a piecewise constant. We implement a highly scalable segmentation with additional loss functions designed for sequencing epigenetic data types including Poisson loss for single tracks and binomial loss for methylation/coverage data. We show that the segmentation approach retains the salient features of the data yet can identify subtle features, such as transcription end sites, missed by other analytic approaches.
Availability and implementation: Our approach is implemented as an R package "l01segmentation" with a C++ backend. Available at https://github.com/boooooogey/l01segmentation.
© The Author(s) 2025. Published by Oxford University Press.
Conflict of interest statement
None declared.
Figures






References
-
- Gong B, Purdom E. Methcp: differentially methylated region detection with change point models. J Comput Biol 2020;27:458–71. - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources
