

Beyond Binary Decisions: Evaluating the Effects of AI Error Type on Trust and Performance in AI-Assisted Tasks
- PMID: 40104968
- PMCID: PMC12273520
- DOI: 10.1177/00187208251326795
Beyond Binary Decisions: Evaluating the Effects of AI Error Type on Trust and Performance in AI-Assisted Tasks
Abstract
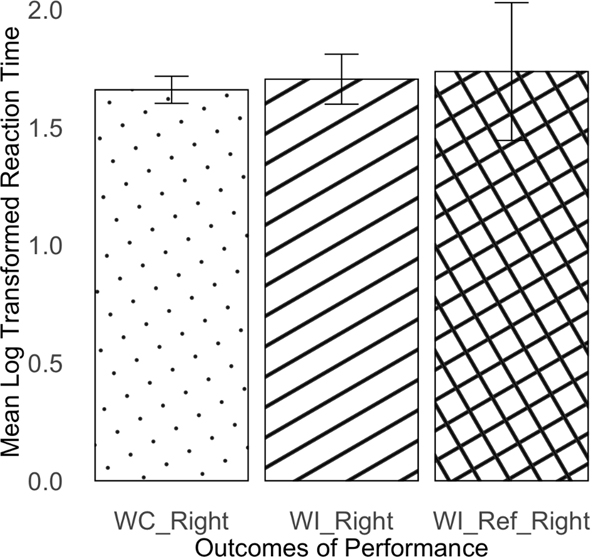
ObjectiveWe investigated how various error patterns from an AI aid in the nonbinary decision scenario influence human operators' trust in the AI system and their task performance.BackgroundExisting research on trust in automation/autonomy predominantly uses the signal detection theory (SDT) to model autonomy performance. The SDT classifies the world into binary states and hence oversimplifies the interaction observed in real-world scenarios. Allowing multi-class classification of the world reveals intriguing error patterns previously unexplored in prior literature.MethodThirty-five participants completed 60 trials of a simulated mental rotation task assisted by an AI with 70-80% reliability. Participants' trust in and dependence on the AI system and their performance were measured. By combining participants' initial performance and the AI aid's performance, five distinct patterns emerged. Mixed-effects models were built to examine the effects of different patterns on trust adjustment, performance, and reaction time.ResultsVarying error patterns from AI impacted performance, reaction times, and trust. Some AI errors provided false reassurance, misleading operators into believing their incorrect decisions were correct, worsening performance and trust. Paradoxically, some AI errors prompted safety checks and verifications, which, despite causing a moderate decrease in trust, ultimately enhanced overall performance.ConclusionThe findings demonstrate that the types of errors made by an AI system significantly affect human trust and performance, emphasizing the need to model the complicated human-AI interaction in real life.ApplicationThese insights can guide the development of AI systems that classify the state of the world into multiple classes, enabling the operators to make more informed and accurate decisions based on feedback.
Keywords: human–AI interaction; human–automation interaction; human–autonomy interaction; multi-class classification; trust dynamics.
Figures


















Similar articles
-
Accreditation through the eyes of nurse managers: an infinite staircase or a phenomenon that evaporates like water.J Health Organ Manag. 2025 Jun 30. doi: 10.1108/JHOM-01-2025-0029. Online ahead of print. J Health Organ Manag. 2025. PMID: 40574247
-
Sexual Harassment and Prevention Training.2024 Mar 29. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan–. 2024 Mar 29. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan–. PMID: 36508513 Free Books & Documents.
-
Trust, Trustworthiness, and the Future of Medical AI: Outcomes of an Interdisciplinary Expert Workshop.J Med Internet Res. 2025 Jun 2;27:e71236. doi: 10.2196/71236. J Med Internet Res. 2025. PMID: 40455564 Free PMC article.
-
Factors that influence the provision of intrapartum and postnatal care by skilled birth attendants in low- and middle-income countries: a qualitative evidence synthesis.Cochrane Database Syst Rev. 2017 Nov 17;11(11):CD011558. doi: 10.1002/14651858.CD011558.pub2. Cochrane Database Syst Rev. 2017. PMID: 29148566 Free PMC article.
-
Parents' and informal caregivers' views and experiences of communication about routine childhood vaccination: a synthesis of qualitative evidence.Cochrane Database Syst Rev. 2017 Feb 7;2(2):CD011787. doi: 10.1002/14651858.CD011787.pub2. Cochrane Database Syst Rev. 2017. PMID: 28169420 Free PMC article.
Cited by
-
Comparative Analysis of Generative Artificial Intelligence Systems in Solving Clinical Pharmacy Problems: Mixed Methods Study.JMIR Med Inform. 2025 Jul 24;13:e76128. doi: 10.2196/76128. JMIR Med Inform. 2025. PMID: 40705654 Free PMC article.
References
-
- Albayram Y, Jensen T, Khan MMH, Fahim MAA, Buck R, & Coman E. (2020). Investigating the effects of (empty) promises on human-automation interaction and trust repair. In Proceedings of the 8th International Conference on Human-Agent Interaction (pp. 6–14).
-
- Ashktorab Z, Jain M, Liao QV, & Weisz JD (2019). Resilient chatbots: Repair strategy preferences for conversational breakdowns. In Proceedings of the 2019 CHI conference on human factors in computing systems (pp. 1–12).
-
- Azevedo-Sa H, Jayaraman SK, Esterwood CT, Yang XJ, Robert LP, & Tilbury DM (2020). Comparing the effects of false alarms and misses on humans’ trust in (semi) autonomous vehicles. In Companion of the 2020 acm/ieee international conference on human-robot interaction (pp. 113–115).
-
- Baker AL, Phillips EK, Ullman D, & Keebler JR (2018). Toward an understanding of trust repair in human-robot interaction: Current research and future directions. ACM Transactions on Interactive Intelligent Systems (TiiS), 8 (4), 1–30.
Grants and funding
LinkOut - more resources
Full Text Sources
