

Cross sectional pilot study on clinical review generation using large language models
- PMID: 40108444
- PMCID: PMC11923074
- DOI: 10.1038/s41746-025-01535-z
Cross sectional pilot study on clinical review generation using large language models
Abstract
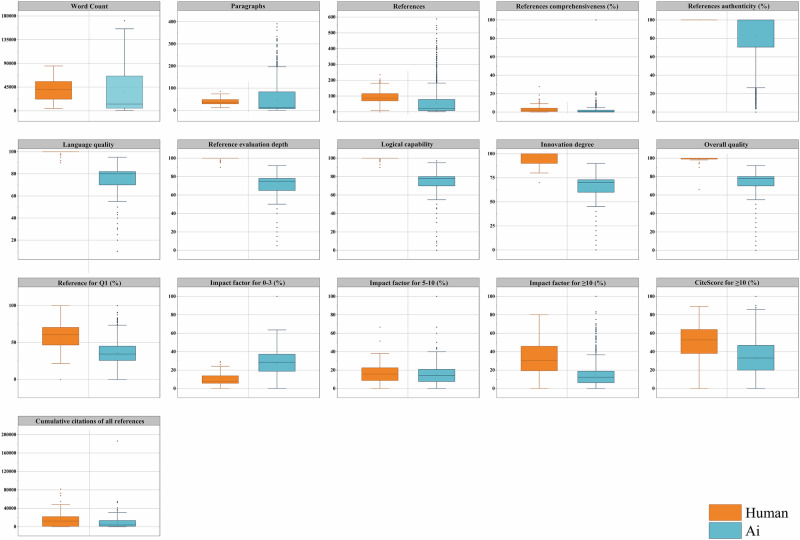
As the volume of medical literature accelerates, necessitating efficient tools to synthesize evidence for clinical practice and research, the interest in leveraging large language models (LLMs) for generating clinical reviews has surged. However, there are significant concerns regarding the reliability associated with integrating LLMs into the clinical review process. This study presents a systematic comparison between LLM-generated and human-authored clinical reviews, revealing that while AI can quickly produce reviews, it often has fewer references, less comprehensive insights, and lower logical consistency while exhibiting lower authenticity and accuracy in their citations. Additionally, a higher proportion of its references are from lower-tier journals. Moreover, the study uncovers a concerning inefficiency in current detection systems for identifying AI-generated content, suggesting a need for more advanced checking systems and a stronger ethical framework to ensure academic transparency. Addressing these challenges is vital for the responsible integration of LLMs into clinical research.
© 2025. The Author(s).
Conflict of interest statement
Competing interests: The authors declare no competing interests.
Figures





References
-
- Rita, G-M, Luca, S., Benjamin, M. S., Philipp, B. & Dmitry, K. The landscape of biomedical research. bioRxiv (2024).
-
- Literature Review and Synthesis Implications on Healthcare Research, Practice, Policy, and Public Messaging. (Springer Publishing Company, New York, NY, 2022).
-
- Thirunavukarasu, A. J. et al. Large language models in medicine. Nat. Med.29, 1930–1940 (2023). - PubMed
-
- The New York Times. How ChatGPT Kicked Off an A.I. Arms Race. (https://www.nytimes.com/2023/02/03/technology/chatgpt-openai-artificial-...) (2023).
-
- Large Language Model Market Size, Share & Trends Analysis Report By Application (Customer Service, Content Generation), By Deployment, By Industry Vertical, By Region, And Segment Forecasts, 2024 - 2030. (https://www.grandviewresearch.com/industry-analysis/large-language-model...) (2024).
LinkOut - more resources
Full Text Sources
Research Materials
