

The landscape of N6-methyladenosine in localized primary prostate cancer
- PMID: 40128621
- PMCID: PMC11985349
- DOI: 10.1038/s41588-025-02128-y
The landscape of N6-methyladenosine in localized primary prostate cancer
Abstract
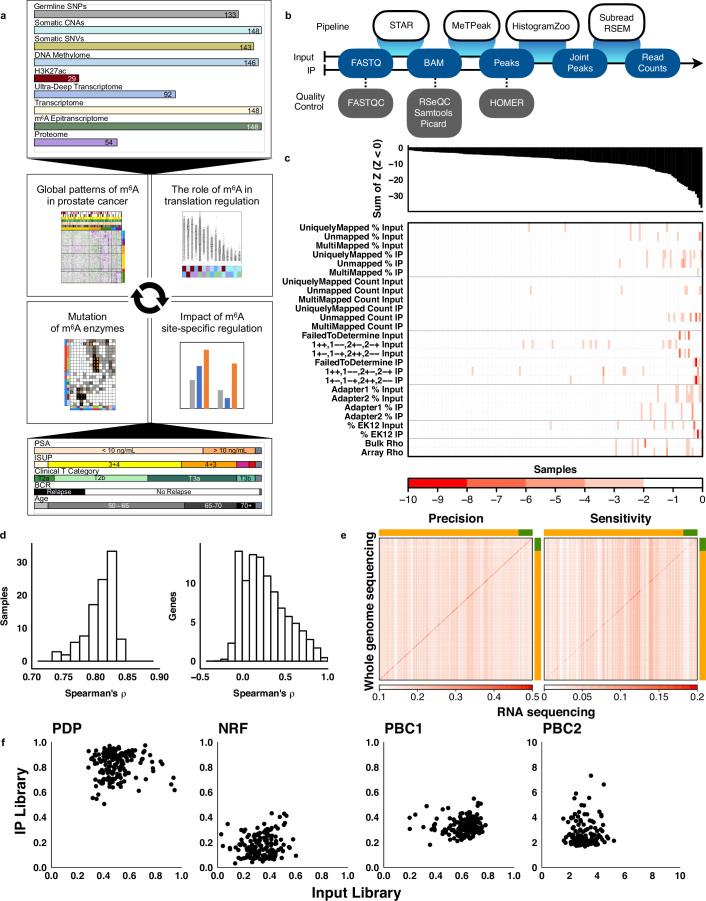
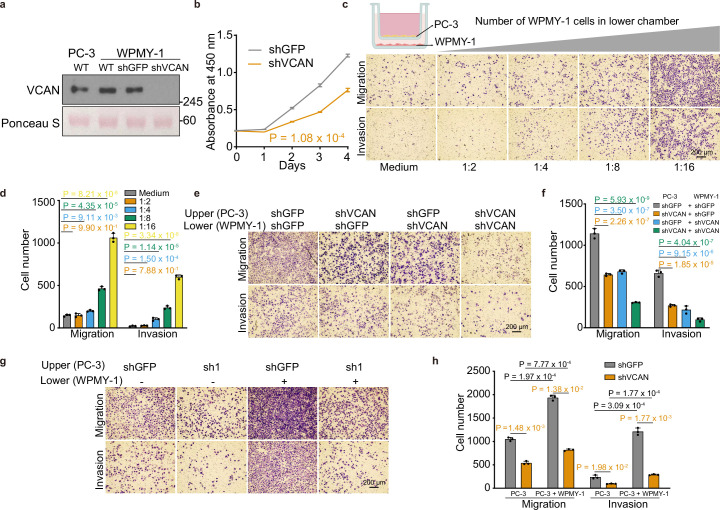
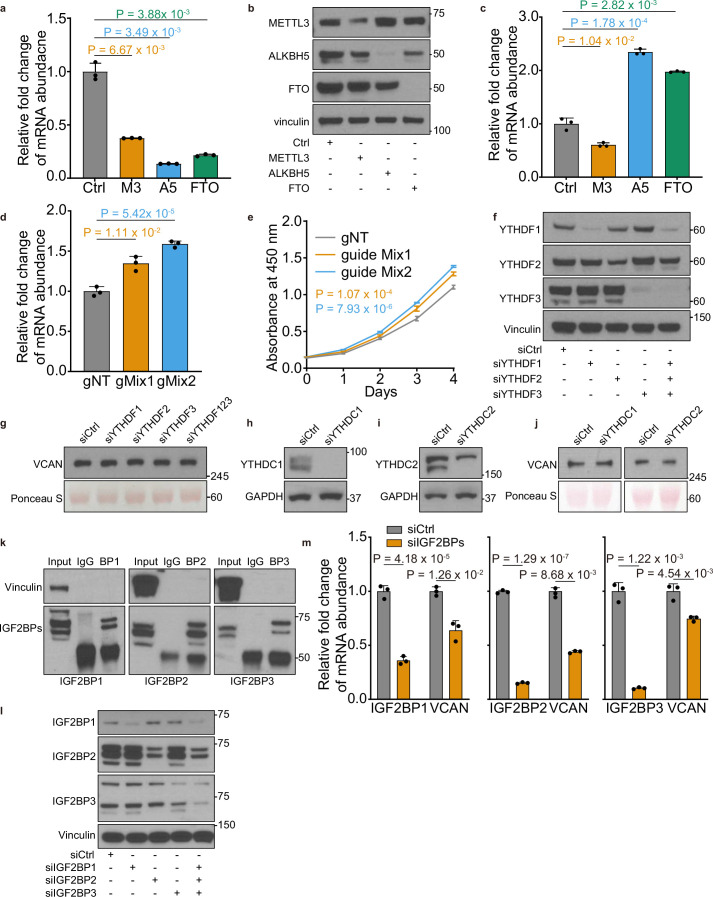
N6-methyladenosine (m6A), the most abundant internal RNA modification in humans, regulates most aspects of RNA processing. Prostate cancer is characterized by widespread transcriptomic dysregulation; therefore, we characterized the m6A landscape of 162 localized prostate tumors with matched DNA, RNA and protein profiling. m6A abundance varied dramatically across tumors, with global patterns emerging via complex germline-somatic cooperative regulation. Individual germline polymorphisms regulated m6A abundance, cooperating with somatic mutation of cancer driver genes and m6A regulators. The resulting complex patterns were associated with prognostic clinical features and established the biomarker potential of global and locus-specific m6A patterns. Tumor hypoxia dysregulates m6A profiles, bridging prior genomic and proteomic observations. Specific m6A sites, such as those in VCAN, drive disease aggression, associating with poor outcomes, tumor growth and metastasis. m6A dysregulation is thus associated with key events in the natural history of prostate cancer: germline risk, microenvironmental dysregulation, somatic mutation and metastasis.
© 2025. The Author(s).
Conflict of interest statement
Competing interests: For a portion of the time during the preparation of this paper, H.Z. was an employee at Deep Genomics. All contributions to the design, analysis and interpretation of results of this project were completed outside of the term of employment. P.C.B. sits on the scientific advisory boards of Sage Bionetworks, Intersect Diagnostics and BioSymetrics. Y. Shao and X.W. are shareholders and/or employees of Geneseeq Technology. The other authors declare no competing interests.
Figures













References
-
- Hanahan, D. & Weinberg, R. A. The hallmarks of cancer. Cell100, 57–70 (2000). - PubMed
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
