

AI-guided precision parenteral nutrition for neonatal intensive care units
- PMID: 40133525
- PMCID: PMC12176641
- DOI: 10.1038/s41591-025-03601-1
AI-guided precision parenteral nutrition for neonatal intensive care units
Erratum in
-
Author Correction: AI-guided precision parenteral nutrition for neonatal intensive care units.Nat Med. 2025 Jun;31(6):2070. doi: 10.1038/s41591-025-03691-x. Nat Med. 2025. PMID: 40205201 Free PMC article. No abstract available.
Abstract
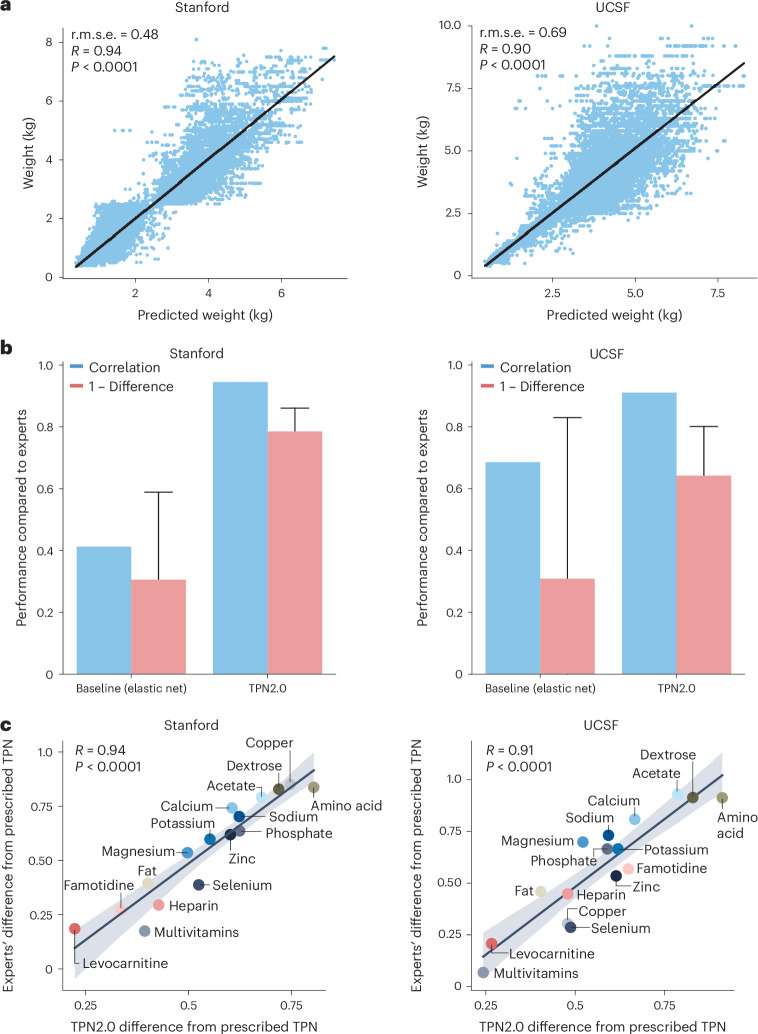
One in ten neonates are admitted to neonatal intensive care units, highlighting the need for precise interventions. However, the application of artificial intelligence (AI) in guiding neonatal care remains underexplored. Total parenteral nutrition (TPN) is a life-saving treatment for preterm neonates; however, implementation of the therapy in its current form is subjective, error-prone and resource-consuming. Here, we developed TPN2.0-a data-driven approach that optimizes and standardizes TPN using information collected routinely in electronic health records. We assembled a decade of TPN compositions (79,790 orders; 5,913 patients) at Stanford to train TPN2.0. In addition to internal validation, we also validated our model in an external cohort (63,273 orders; 3,417 patients) from a second hospital. Our algorithm identified 15 TPN formulas that can enable a precision-medicine approach (Pearson's R = 0.94 compared to experts), increasing safety and potentially reducing cost. A blinded study (n = 192) revealed that physicians rated TPN2.0 higher than current best practice. In patients with high disagreement between the actual prescriptions and TPN2.0, standard prescriptions were associated with increased morbidities (for example, odds ratio = 3.33; P value = 0.0007 for necrotizing enterocolitis), while TPN2.0 recommendations were linked to reduced risk. Finally, we demonstrated that TPN2.0 employing a transformer architecture enabled guideline-adhering, physician-in-the-loop recommendations that allow collaboration between the care team and AI.
© 2025. The Author(s).
Conflict of interest statement
Competing interests: The methods described in this manuscript are covered in the US provisional Patent 63/268,689 (WO2022256850A1; ‘Systems and methods to assess neonatal health risk and uses thereof’) approved in 2022. T.P. is a cofounder of Takeoff41. S.M. is a paid consultant for Danaher and Longitude Capital and receives a paid fellowship from Nucleate. J.H.F. is an advisor to Vitara, OvaryIt, Keriton, EmpoHealth, and Avanos; the consulting medical director of Novonate; and a cofounder for EMME. K.G.S. is a consultant for Avexegen Therapeutics, Infinant Health, mProbe and Mission Biocapital. M.S.A. is a member of the Scientific Advisory Board of Cytonics Inc. and AfaSci Research Laboratories and is a paid consultant for Syneos Health. D.K.S. is a member of the Clinical Advisory Board of Maternica Therapeutics. M.S. is a member of the Scientific Advisory Board of Exagen and Aria Pharmaceuticals and is a shareholder at Somnics. N.A. is a member of the Scientific Advisory Boards of January AI, Parallel Bio and WellSim Biomedical Technologies, is a cofounder of Takeoff41 and is a paid consultant for MaraBio Systems. The other authors declare no competing interests.
Figures















References
-
- Granger, C. L., Okpapi, A., Peters, C. & Campbell, M. G578(P) Potentially preventable unexpected term admissions to neonatal intensive care (NICU). Arch. Dis. Child.100, A263–A263 (2015).
-
- Harrison, W. & Goodman, D. Epidemiologic trends in neonatal intensive care, 2007–2012. JAMA Pediatr.169, 855–862 (2015). - PubMed
-
- Martin, J. A. & Osterman, M. J. K. Shifts in the distribution of births by gestational age: United States, 2014–2022. Natl Vital Stat. Rep.73, 1–11 (2024). - PubMed
-
- Gregory, G. A., Kitterman, J. A., Phibbs, R. H., Tooley, W. H. & Hamilton, W. K. Treatment of the idiopathic respiratory-distress syndrome with continuous positive airway pressure. N. Engl. J. Med.284, 1333–1340 (1971). - PubMed
MeSH terms
Grants and funding
- UL1 TR001872/TR/NCATS NIH HHS/United States
- UL1TR001872/U.S. Department of Health & Human Services | NIH | National Center for Advancing Translational Sciences (NCATS)
- R35GM138353/U.S. Department of Health & Human Services | NIH | National Institute of General Medical Sciences (NIGMS)
- R42HD115517/U.S. Department of Health & Human Services | NIH | Eunice Kennedy Shriver National Institute of Child Health and Human Development (NICHD)
- R35 GM138353/GM/NIGMS NIH HHS/United States
LinkOut - more resources
Full Text Sources
Medical
Research Materials
