

Edge-Centric Embeddings of Digraphs: Properties and Stability Under Sparsification
- PMID: 40149228
- PMCID: PMC11941605
- DOI: 10.3390/e27030304
Edge-Centric Embeddings of Digraphs: Properties and Stability Under Sparsification
Abstract
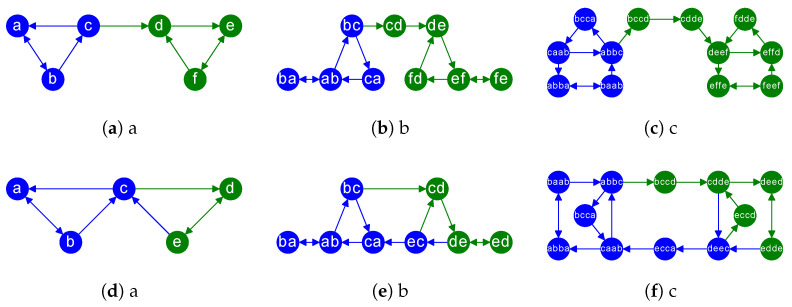
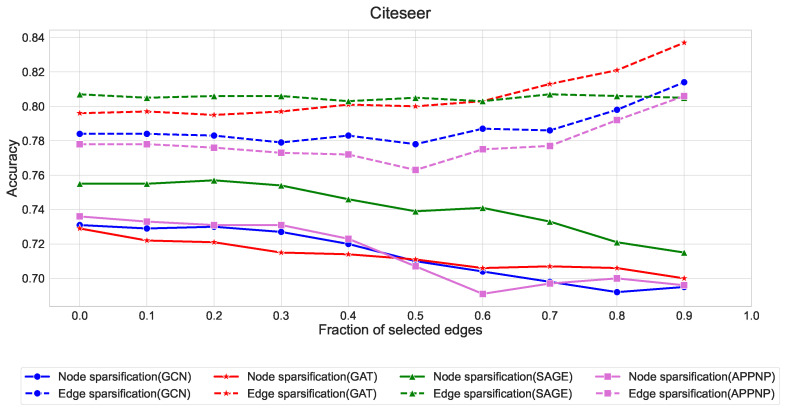
In this paper, we define and characterize the embedding of edges and higher-order entities in directed graphs (digraphs) and relate these embeddings to those of nodes. Our edge-centric approach consists of the following: (a) Embedding line digraphs (or their iterated versions); (b) Exploiting the rank properties of these embeddings to show that edge/path similarity can be posed as a linear combination of node similarities; (c) Solving scalability issues through digraph sparsification; (d) Evaluating the performance of these embeddings for classification and clustering. We commence by identifying the motive behind the need for edge-centric approaches. Then we proceed to introduce all the elements of the approach, and finally, we validate it. Our edge-centric embedding entails a top-down mining of links, instead of inferring them from the similarities of node embeddings. This analysis is key to discovering inter-subgraph links that hold the whole graph connected, i.e., central edges. Using directed graphs (digraphs) allows us to cluster edge-like hubs and authorities. In addition, since directed edges inherit their labels from destination (origin) nodes, their embedding provides a proxy representation for node classification and clustering as well. This representation is obtained by embedding the line digraph of the original one. The line digraph provides nice formal properties with respect to the original graph; in particular, it produces more entropic latent spaces. With these properties at hand, we can relate edge embeddings to node embeddings. The main contribution of this paper is to set and prove the linearity theorem, which poses each element of the transition matrix for an edge embedding as a linear combination of the elements of the transition matrix for the node embedding. As a result, the rank preservation property explains why embedding the line digraph and using the labels of the destination nodes provides better classification and clustering performances than embedding the nodes of the original graph. In other words, we do not only facilitate edge mining but enforce node classification and clustering. However, computing the line digraph is challenging, and a sparsification strategy is implemented for the sake of scalability. Our experimental results show that the line digraph representation of the sparsified input graph is quite stable as we increase the sparsification level, and also that it outperforms the original (node-centric) representation. For the sake of simplicity, our theorem relies on node2vec-like (factorization) embeddings. However, we also include several experiments showing how line digraphs may improve the performance of Graph Neural Networks (GNNs), also following the principle of maximum entropy.
Keywords: digraph sparsification; edge embedding; edge mining; graph neural networks; line digraph; maximum entropy.
Conflict of interest statement
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of the data; in the writing of the manuscript; or in the decision to publish the results.
Figures







References
-
- Kipf T.N., Welling M. Semi-Supervised Classification with Graph Convolutional Networks; Proceedings of the International Conference on Learning Representations (ICLR); Toulon, France. 24–26 April 2017.
-
- Veličković P., Cucurull G., Casanova A., Romero A., Liò P., Bengio Y. Graph Attention Networks; Proceedings of the International Conference on Learning Representations; Vancouver, BC, Canada. 30 April–3 May 2018.
-
- Klicpera J., Bojchevski A., Günnemann S. Personalized Embedding Propagation: Combining Neural Networks on Graphs with Personalized PageRank. arXiv. 20181810.05997
-
- Hamilton W., Ying Z., Leskovec J. Inductive representation learning on large graphs. Adv. Neural Inf. Process. Syst. 2017;30:1025–1035.
-
- Waikhom L., Patgiri R. A survey of graph neural networks in various learning paradigms: Methods, applications, and challenges. Artif. Intell. Rev. 2023;56:6295–6364. doi: 10.1007/s10462-022-10321-2. - DOI
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials
