

Leveraging large language models to mimic domain expert labeling in unstructured text-based electronic healthcare records in non-english languages
- PMID: 40165165
- PMCID: PMC11959812
- DOI: 10.1186/s12911-025-02871-6
Leveraging large language models to mimic domain expert labeling in unstructured text-based electronic healthcare records in non-english languages
Abstract
Background: The integration of big data and artificial intelligence (AI) in healthcare, particularly through the analysis of electronic health records (EHR), presents significant opportunities for improving diagnostic accuracy and patient outcomes. However, the challenge of processing and accurately labeling vast amounts of unstructured data remains a critical bottleneck, necessitating efficient and reliable solutions. This study investigates the ability of domain specific, fine-tuned large language models (LLMs) to classify unstructured EHR texts with typographical errors through named entity recognition tasks, aiming to improve the efficiency and reliability of supervised learning AI models in healthcare.
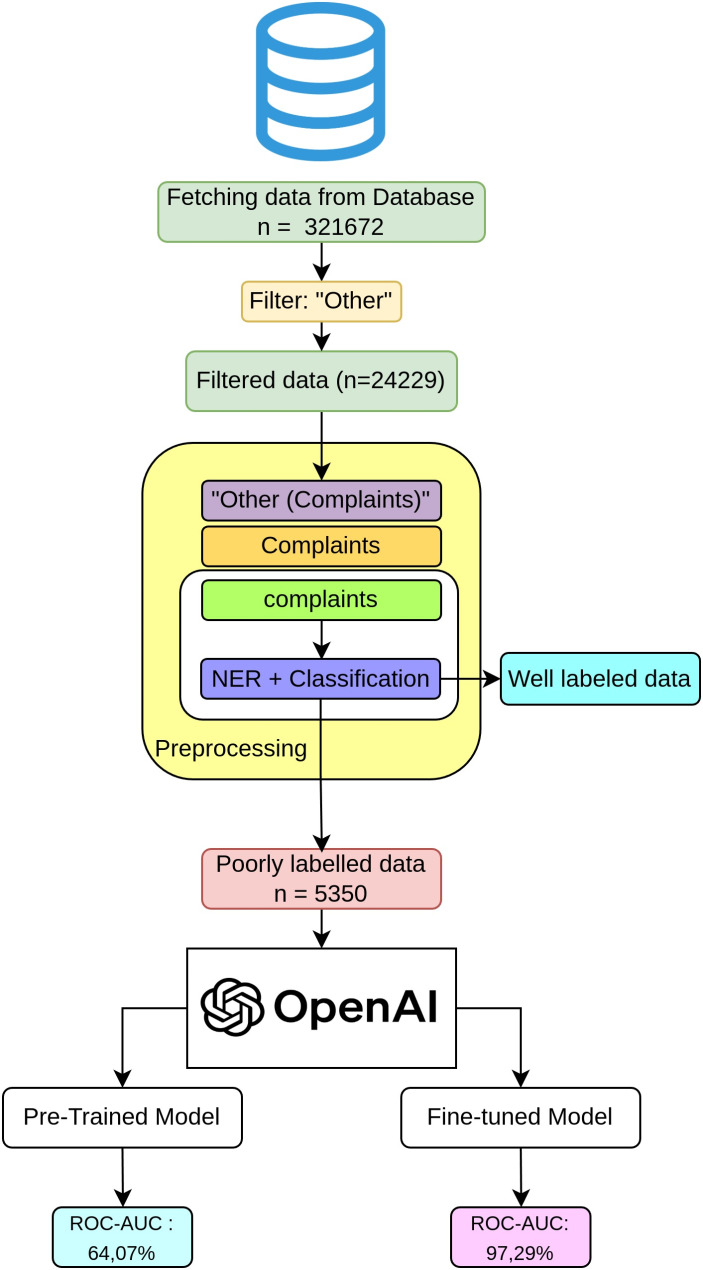
Methods: Turkish clinical notes from pediatric emergency room admissions at Hacettepe University İhsan Doğramacı Children's Hospital from 2018 to 2023 were analyzed. The data were preprocessed with open source Python libraries and categorized using a pretrained GPT-3 model, "text-davinci-003," before and after fine-tuning with domain-specific data on respiratory tract infections (RTI). The model's predictions were compared against ground truth labels established by pediatric specialists.
Results: Out of 24,229 patient records classified as poorly labeled, 18,879 were identified without typographical errors and confirmed for RTI through filtering methods. The fine-tuned model achieved a 99.88% accuracy, significantly outperforming the pretrained model's 78.54% accuracy in identifying RTI cases among the remaining records. The fine-tuned model demonstrated superior performance metrics across all evaluated aspects compared to the pretrained model.
Conclusions: Fine-tuned LLMs can categorize unstructured EHR data with high accuracy, closely approximating the performance of domain experts. This approach significantly reduces the time and costs associated with manual data labeling, demonstrating the potential to streamline the processing of large-scale healthcare data for AI applications.
Keywords: Artificial intelligence; Electronic healthcare records; Large language models; Respiratory tract infections.
© 2025. The Author(s).
Conflict of interest statement
Declarations. Ethics approval and consent to participate: The Hacettepe University Clinical Research Ethics Committee approved our study’s design and procedures under protocol number GO-23/508, ensuring adherence to the ethical standards in clinical research. The data sourced from Hacettepe University İhsan Doğramacı Children’s Hospital, which underwent a de-identification process through the redaction of protected health information, received approval for utilization in a quality improvement project by the hospital. In this context, the Hacettepe University Research Ethics Board granted a waiver for the necessity of its approval and the procurement of informed consent for this study. Furthermore, all procedures complied with the relevant guidelines and standards outlined in the Declaration of Helsinki. Consent for publication: Not applicable. Competing interests: The authors declare no competing interests.
Figures
Similar articles
-
Using Synthetic Health Care Data to Leverage Large Language Models for Named Entity Recognition: Development and Validation Study.J Med Internet Res. 2025 Mar 18;27:e66279. doi: 10.2196/66279. J Med Internet Res. 2025. PMID: 40101227 Free PMC article.
-
Classifying Unstructured Text in Electronic Health Records for Mental Health Prediction Models: Large Language Model Evaluation Study.JMIR Med Inform. 2025 Jan 21;13:e65454. doi: 10.2196/65454. JMIR Med Inform. 2025. PMID: 39864953 Free PMC article.
-
A large language model-based generative natural language processing framework fine-tuned on clinical notes accurately extracts headache frequency from electronic health records.Headache. 2024 Apr;64(4):400-409. doi: 10.1111/head.14702. Epub 2024 Mar 25. Headache. 2024. PMID: 38525734 Free PMC article.
-
Large Language Model Applications for Health Information Extraction in Oncology: Scoping Review.JMIR Cancer. 2025 Mar 28;11:e65984. doi: 10.2196/65984. JMIR Cancer. 2025. PMID: 40153782 Free PMC article.
-
Utilizing large language models for gastroenterology research: a conceptual framework.Therap Adv Gastroenterol. 2025 Apr 1;18:17562848251328577. doi: 10.1177/17562848251328577. eCollection 2025. Therap Adv Gastroenterol. 2025. PMID: 40171241 Free PMC article. Review.
References
-
- Saggi MK, Jain S. A survey towards an integration of big data analytics to big insights for value-creation. Inf Process Manag. 2018;54(5):758–90.
-
- Mishra S, Tripathy HK, Mishra BK, Sahoo S. Usage and Analysis of Big Data in E-Health Domain. In: Research Anthology on Big Data Analytics, Architectures, and Applications. IGI Global; 2022 [cited 2024 Feb 8]. pp. 417–30. Available from: https://www.igi-global.com/chapter/usage-and-analysis-of-big-data-in-e-h...
MeSH terms
LinkOut - more resources
Full Text Sources
