

The Development Landscape of Large Language Models for Biomedical Applications
- PMID: 40169010
- PMCID: PMC12372014
- DOI: 10.1146/annurev-biodatasci-102224-074736
The Development Landscape of Large Language Models for Biomedical Applications
Abstract
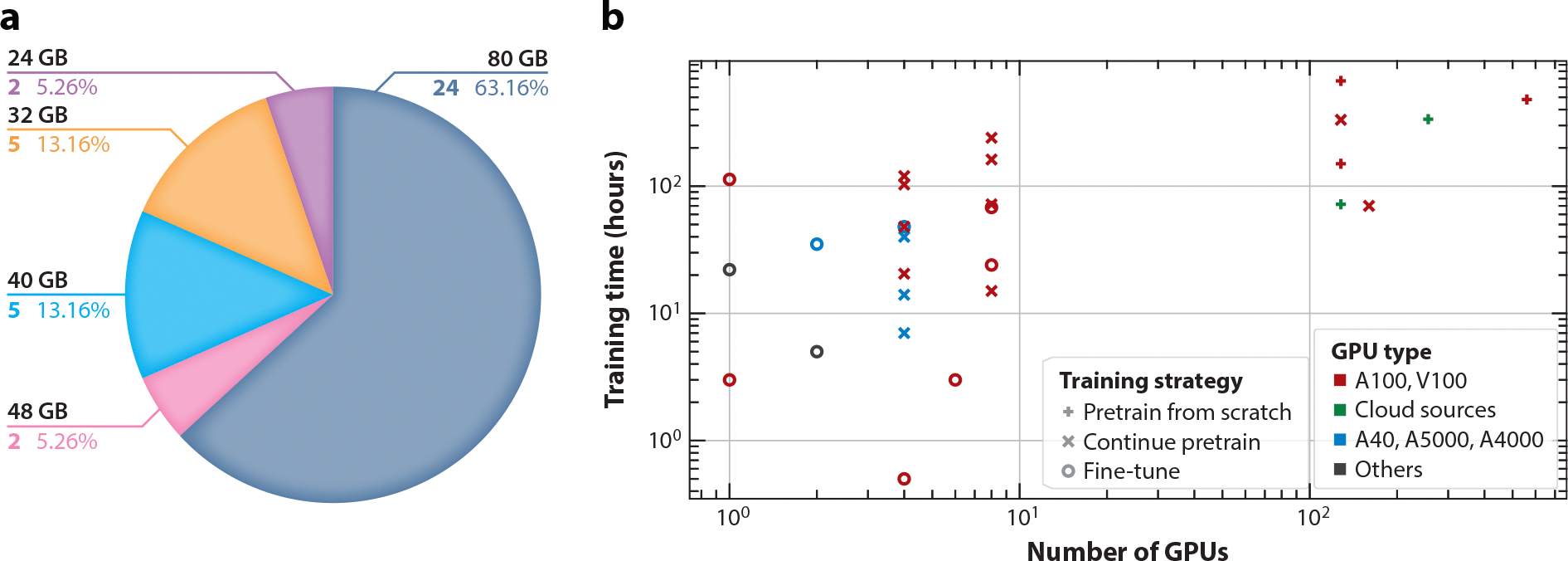
Large language models (LLMs) have become powerful tools for biomedical applications, offering potential to transform healthcare and medical research. Since the release of ChatGPT in 2022, there has been a surge in LLMs for diverse biomedical applications. This review examines the landscape of text-based biomedical LLM development, analyzing model characteristics (e.g., architecture), development processes (e.g., training strategy), and applications (e.g., chatbots). Following PRISMA guidelines, 82 articles were selected out of 5,512 articles since 2022 that met our rigorous criteria, including the requirement of using biomedical data when training LLMs. Findings highlight the predominant use of decoder-only architectures such as Llama 7B, prevalence of task-specific fine-tuning, and reliance on biomedical literature for training. Challenges persist in balancing data openness with privacy concerns and detailing model development, including computational resources used. Future efforts would benefit from multimodal integration, LLMs for specialized medical applications, and improved data sharing and model accessibility.
Keywords: biomedical applications; clinical NLP; healthcare AI; large language models.
Figures


References
-
- Brown TB, Mann B, Ryder N, Subbiah M, Kaplan J, et al. 2020. Language models are few-shot learners. Preprint, arXiv:2005.14165v4 [cs.CL]
-
- Achiam J, Adler S, Agarwal S, Ahmad L, Akkaya I, et al. 2024. GPT-4 technical report. Preprint, arXiv:2303.08774v6 [cs.CL]
-
- GLM T, Zeng A, Xu B, Wang B, Zhang C, et al. 2024. ChatGLM: a family of large language models from GLM-130B to GLM-4 all tools. Preprint, arXiv:2406.12793v2 [cs.CL]
-
- Touvron H, Lavril T, Izacard G, Martinet X, Lachaux M-A, et al. 2023. LLaMA: open and efficient foundation language models. Preprint, arXiv:2302.13971v1 [cs.CL]
-
- Touvron H, Martin L, Stone K, Albert P, Almahairi A, et al. 2023. Llama 2: OPEN foundation and fine-tuned chat models. Preprint, arXiv:2307.09288v2 [cs.CL]
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
