

CAVE: Connectome Annotation Versioning Engine
- PMID: 40205066
- PMCID: PMC12074985
- DOI: 10.1038/s41592-024-02426-z
CAVE: Connectome Annotation Versioning Engine
Abstract
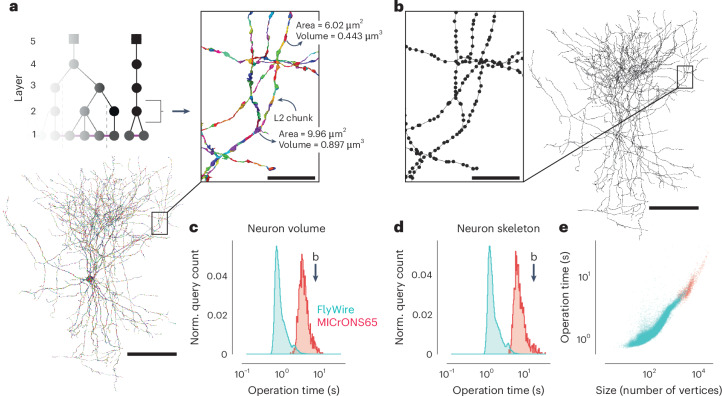
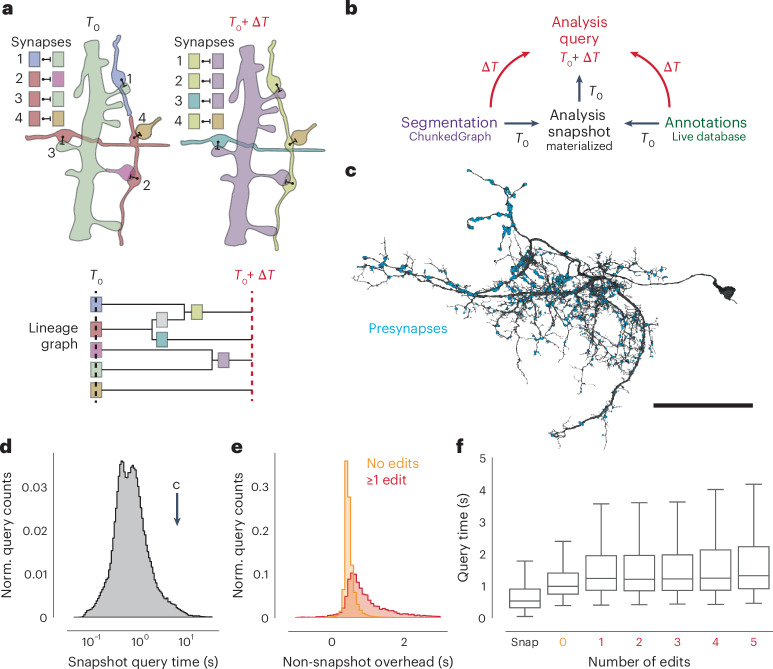
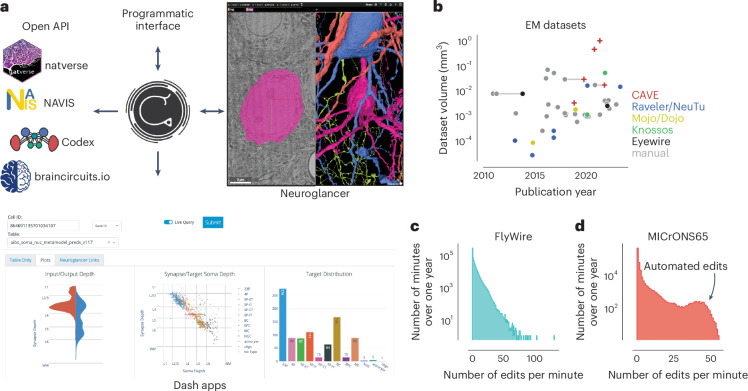
Advances in electron microscopy, image segmentation and computational infrastructure have given rise to large-scale and richly annotated connectomic datasets, which are increasingly shared across communities. To enable collaboration, users need to be able to concurrently create annotations and correct errors in the automated segmentation by proofreading. In large datasets, every proofreading edit relabels cell identities of millions of voxels and thousands of annotations like synapses. For analysis, users require immediate and reproducible access to this changing and expanding data landscape. Here we present the Connectome Annotation Versioning Engine (CAVE), a computational infrastructure that provides scalable solutions for proofreading and flexible annotation support for fast analysis queries at arbitrary time points. Deployed as a suite of web services, CAVE empowers distributed communities to perform reproducible connectome analysis in up to petascale datasets (~1 mm3) while proofreading and annotating is ongoing.
© 2024. The Author(s).
Conflict of interest statement
Competing interests: T.M., K. Lee, S.P., N.K. and H.S.S. declare financial interests in Zetta AI. S.D. and J.M.-S. are employees of Google, which sells cloud computing services. H.S.S. declares in kind donations by Google received as access to cloud compute resources. The other authors declare no competing interests.
Figures











Update of
-
CAVE: Connectome Annotation Versioning Engine.bioRxiv [Preprint]. 2023 Jul 28:2023.07.26.550598. doi: 10.1101/2023.07.26.550598. bioRxiv. 2023. Update in: Nat Methods. 2025 May;22(5):1112-1120. doi: 10.1038/s41592-024-02426-z. PMID: 37546753 Free PMC article. Updated. Preprint.
References
MeSH terms
Grants and funding
- RF1 MH123400/MH/NIMH NIH HHS/United States
- D16PC00004/ODNI | Intelligence Advanced Research Projects Activity (IARPA)
- 2017-17032700004-005/ODNI | Intelligence Advanced Research Projects Activity (IARPA)
- 2124179/NSF | Directorate for Computer & Information Science & Engineering | Division of Information and Intelligent Systems (Information & Intelligent Systems)
- 2014862/National Science Foundation (NSF)
- D16PC0005/ODNI | Intelligence Advanced Research Projects Activity (IARPA)
- RF1MH125932/U.S. Department of Health & Human Services | NIH | National Institute of Mental Health (NIMH)
- RF1 MH125932/MH/NIMH NIH HHS/United States
- U24 NS126935/NS/NINDS NIH HHS/United States
- RF1 MH129268/MH/NIMH NIH HHS/United States
LinkOut - more resources
Full Text Sources
