

Classification of intracranial pressure epochs using a novel machine learning framework
- PMID: 40210973
- PMCID: PMC11986046
- DOI: 10.1038/s41746-025-01612-3
Classification of intracranial pressure epochs using a novel machine learning framework
Abstract
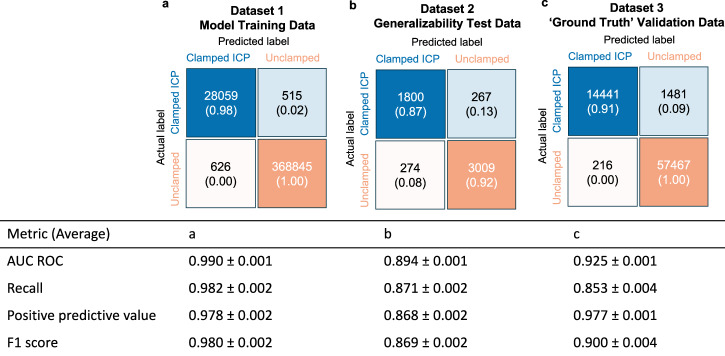
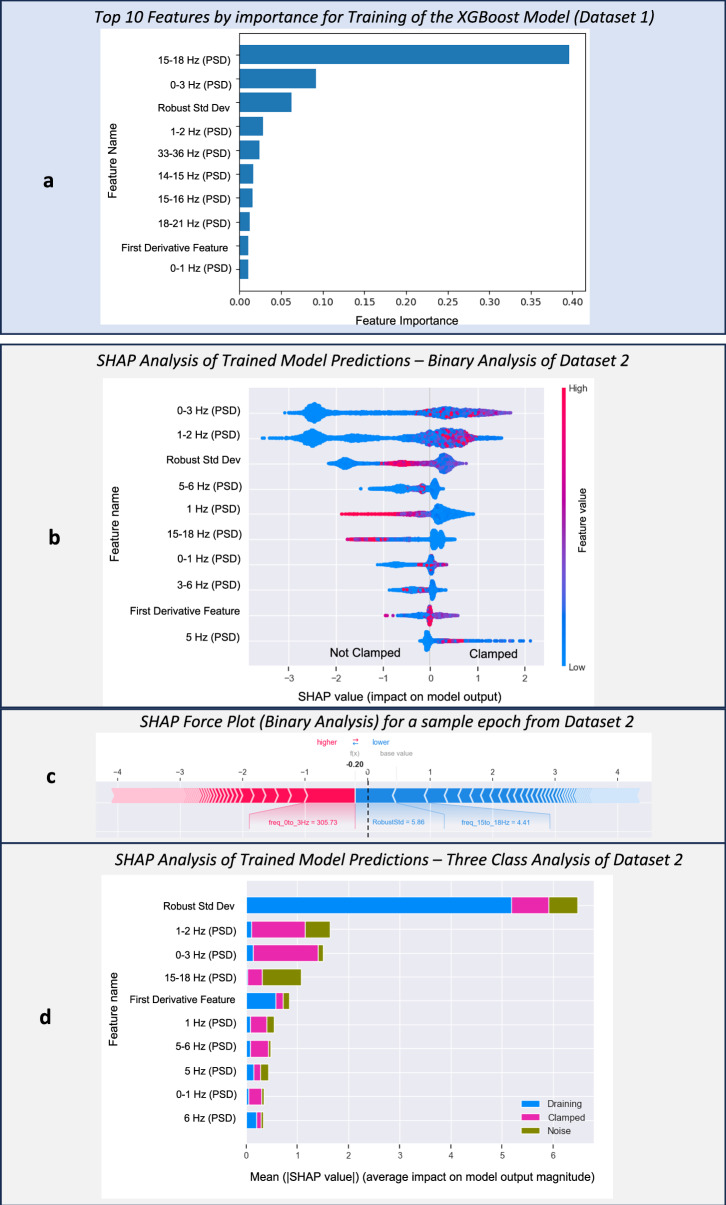
Patients with acute brain injuries are at risk for life threatening elevated intracranial pressure (ICP). External Ventricular Drains (EVDs) are used to measure and treat ICP, which switch between clamped and draining configurations, with accurate ICP data only available during clamped periods. While traditional guidelines focus on mean ICP values, evolving evidence indicates other waveform features may hold prognostic value. However, current machine learning models using ICP waveforms exclude EVD data due to a lack of digital labels indicating the clamped state, markedly limiting their generalizability. We introduce, detail, and validate CICL (Classification of ICP epochs using a machine Learning framework), a semi-supervised approach to classify ICP segments from EVDs as clamped, draining, or noise. This paves the way for multiple applications, including generalizable ICP crisis prediction, potentially benefiting tens of thousands of patients annually and highlights an innovate methodology to label large high frequency physiological time series datasets.
© 2025. The Author(s).
Conflict of interest statement
Competing interests: The authors declare no competing financial or non-financial interests that have a relationship to this work as defined by Nature Portfolio. The authors declare the following non-competing disclosures: Vishank Shah disclosures: VS received honoraria (<1000$) from Astra Zeneca and serves on the Editorial Board for Neurohospitalist. Sudha Yellapantula works as a Researcher for Medical Informatics Corp (MIC, Houston TX) and reports no competing interests. MIC is a company that provides the Sickbay platform to various hospitals, for clinical and research use of the data. Medical Informatics provided no funding and/or support for the study. Jose I Suarez disclosures: ex-officio member of the Board of Directors of the Neurocritical Care Society; member of the Scientific Advisory Board for Cyban; Member of the Data Safety Monitoring Board for clinical trials sponsored by Acasti and Perfuze; member of the Advisory Board for AstraZeneca for Andexxa Medical Strategy. Susanne Muehlschlegel disclosures: ex-officio member of the Board of Directors of the Neurocritical Care Society; Consultant for Acasti Pharma as a member of the clinical endpoint adjudication committee. Has received speaking and writing honoraria from the American Academy of Neurology. Serves on the Editorial Board for Neurocritical Care and Stroke (unpaid).
Figures






Similar articles
-
Automatic identification of intracranial pressure waveform during external ventricular drainage clamping: segmentation via wavelet analysis.Physiol Meas. 2023 Jul 4;44(6):10.1088/1361-6579/acdf3b. doi: 10.1088/1361-6579/acdf3b. Physiol Meas. 2023. PMID: 37327793 Free PMC article.
-
Evolving concepts in intracranial pressure monitoring - from traditional monitoring to precision medicine.Neurotherapeutics. 2025 Jan;22(1):e00507. doi: 10.1016/j.neurot.2024.e00507. Epub 2025 Jan 3. Neurotherapeutics. 2025. PMID: 39753383 Free PMC article. Review.
-
Deriving Automated Device Metadata From Intracranial Pressure Waveforms: A Transforming Research and Clinical Knowledge in Traumatic Brain Injury ICU Physiology Cohort Analysis.Crit Care Explor. 2024 Jul 16;6(7):e1118. doi: 10.1097/CCE.0000000000001118. eCollection 2024 Jul 1. Crit Care Explor. 2024. PMID: 39016273 Free PMC article.
-
Evaluation of a New Catheter for Simultaneous Intracranial Pressure Monitoring and Cerebral Spinal Fluid Drainage: A Pilot Study.Neurocrit Care. 2019 Jun;30(3):617-625. doi: 10.1007/s12028-018-0648-z. Neurocrit Care. 2019. PMID: 30511345 Free PMC article.
-
The current status of noninvasive intracranial pressure monitoring: A literature review.Clin Neurol Neurosurg. 2024 Apr;239:108209. doi: 10.1016/j.clineuro.2024.108209. Epub 2024 Feb 29. Clin Neurol Neurosurg. 2024. PMID: 38430649 Review.
References
-
- Le Roux, P. et al. Consensus summary statement of the international multidisciplinary consensus conference on multimodality monitoring in neurocritical care: a statement for healthcare professionals from the neurocritical care society and the european society of intensive care medicine. Neurocritical Care21, 1–26 (2014). - PMC - PubMed
-
- Carney, N. et al. Guidelines for the management of severe traumatic brain injury. Neurosurgery80, 6–15 (2017). - PubMed
-
- Stocchetti, N. & Maas, A. I. Traumatic intracranial hypertension. N. Engl. J. Med.370, 2121–2130 (2014). - PubMed
-
- Rosner, M. J. & Becker, D. P. Origin and evolution of plateau waves: experimental observations and a theoretical model. J. Neurosurg.60, 312–324 (1984). - PubMed
-
- Robba, C. et al. Intracranial pressure monitoring in patients with acute brain injury in the intensive care unit (synapse-icu): an international, prospective observational cohort study. Lancet Neurol.20, 548–558 (2021). - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources
