

FGeneBERT: function-driven pre-trained gene language model for metagenomics
- PMID: 40211978
- PMCID: PMC11986344
- DOI: 10.1093/bib/bbaf149
FGeneBERT: function-driven pre-trained gene language model for metagenomics
Abstract
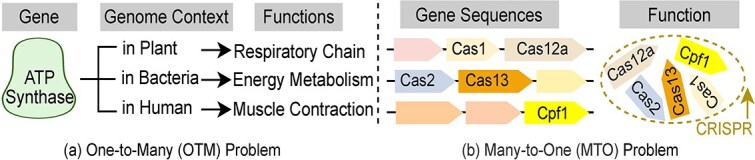
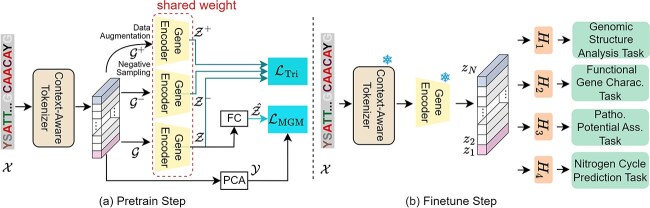
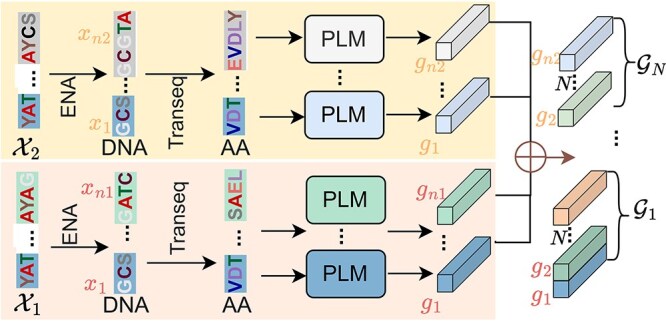
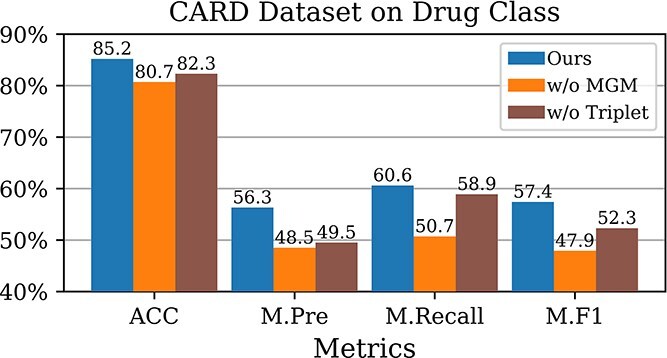
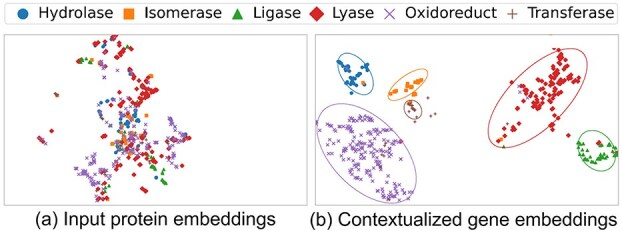
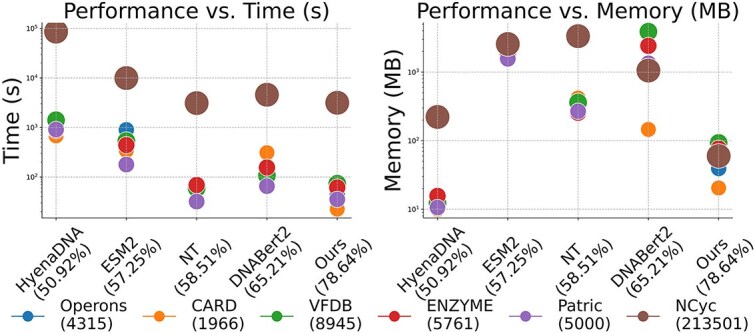
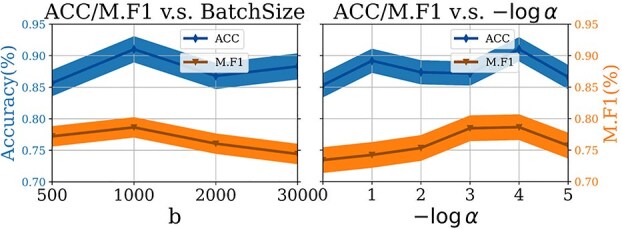
Metagenomic data, comprising mixed multi-species genomes, are prevalent in diverse environments like oceans and soils, significantly impacting human health and ecological functions. However, current research relies on K-mer, which limits the capture of structurally and functionally relevant gene contexts. Moreover, these approaches struggle with encoding biologically meaningful genes and fail to address the one-to-many and many-to-one relationships inherent in metagenomic data. To overcome these challenges, we introduce FGeneBERT, a novel metagenomic pre-trained model that employs a protein-based gene representation as a context-aware and structure-relevant tokenizer. FGeneBERT incorporates masked gene modeling to enhance the understanding of inter-gene contextual relationships and triplet enhanced metagenomic contrastive learning to elucidate gene sequence-function relationships. Pre-trained on over 100 million metagenomic sequences, FGeneBERT demonstrates superior performance on metagenomic datasets at four levels, spanning gene, functional, bacterial, and environmental levels and ranging from 1 to 213 k input sequences. Case studies of ATP synthase and gene operons highlight FGeneBERT's capability for functional recognition and its biological relevance in metagenomic research.
Keywords: DNA; metagenomics; pre-trained language model; transformer.
© The Author(s) 2025. Published by Oxford University Press.
Figures

Similar articles
-
Metagenomic assembly through the lens of validation: recent advances in assessing and improving the quality of genomes assembled from metagenomes.Brief Bioinform. 2019 Jul 19;20(4):1140-1150. doi: 10.1093/bib/bbx098. Brief Bioinform. 2019. PMID: 28968737 Free PMC article.
-
Assessment of k-mer spectrum applicability for metagenomic dissimilarity analysis.BMC Bioinformatics. 2016 Jan 16;17:38. doi: 10.1186/s12859-015-0875-7. BMC Bioinformatics. 2016. PMID: 26774270 Free PMC article.
-
Quality control of microbiota metagenomics by k-mer analysis.BMC Genomics. 2015 Mar 14;16(1):183. doi: 10.1186/s12864-015-1406-7. BMC Genomics. 2015. PMID: 25887914 Free PMC article.
-
Solving genomic puzzles: computational methods for metagenomic binning.Brief Bioinform. 2024 Jul 25;25(5):bbae372. doi: 10.1093/bib/bbae372. Brief Bioinform. 2024. PMID: 39082646 Free PMC article. Review.
-
[A review on the bioinformatics pipelines for metagenomic research].Dongwuxue Yanjiu. 2012 Dec;33(6):574-85. doi: 10.3724/SP.J.1141.2012.06574. Dongwuxue Yanjiu. 2012. PMID: 23266976 Review. Chinese.
Cited by
-
PRCFX-DT: a new graph-based approach for feature selection and classification of genomic sequences.BMC Bioinformatics. 2025 Jun 17;26(1):159. doi: 10.1186/s12859-025-06183-4. BMC Bioinformatics. 2025. PMID: 40528202 Free PMC article.
-
AI-Driven Antimicrobial Peptide Discovery: Mining and Generation.Acc Chem Res. 2025 Jun 17;58(12):1831-1846. doi: 10.1021/acs.accounts.0c00594. Epub 2025 Jun 3. Acc Chem Res. 2025. PMID: 40459283 Free PMC article. Review.
References
-
- De D, Nayak T, Das G. et al. Metagenomics and bioinformatics in microbial ecology: current status and beyond. In: Thatoi H, Pradhan SK, Kumar U. (Eds.), Applications of Metagenomics. Amsterdam, Netherlands: Elsevier, 2024, pp. 359–85. 10.1016/B978-0-323-98394-5.00009-2. - DOI
-
- Duan CR, Zang Z, Li S. et al. Phylogen: language model-enhanced phylogenetic inference via graph structure generation. Adv Neural Inform Process Syst 2024;37:131676–703.
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
