

ModuCLIP: multi-scale CLIP framework for predicting foundation pit deformation in multi-modal robotic systems
- PMID: 40236467
- PMCID: PMC11996866
- DOI: 10.3389/fnbot.2025.1544694
ModuCLIP: multi-scale CLIP framework for predicting foundation pit deformation in multi-modal robotic systems
Abstract
Introduction: Foundation pit deformation prediction is a critical aspect of underground engineering safety assessment, influencing construction quality and personnel safety. However, due to complex geological conditions and numerous environmental interference factors, traditional prediction methods struggle to achieve precise modeling. Conventional approaches, including numerical simulations, empirical formulas, and machine learning models, suffer from limitations such as high computational costs, poor generalization, or excessive dependence on specific data distributions. Recently, deep learning models, particularly cross-modal architectures, have demonstrated great potential in engineering applications. However, effectively integrating multi-modal data for improved prediction accuracy remains a significant challenge.
Methods: This study proposes a Multi-Scale Contrastive Language-Image Pretraining (CLP) framework, ModuCLIP, designed for foundation pit deformation prediction in multi-modal robotic systems. The framework leverages a self-supervised contrastive learning mechanism to integrate multi-source information, including images, textual descriptions, and sensor data, while employing a multi-scale feature learning approach to enhance adaptability to complex conditions. Experiments conducted on multiple foundation pit engineering datasets demonstrate that ModuCLIP outperforms existing methods in terms of prediction accuracy, generalization, and robustness.
Results and discussion: The findings suggest that this framework provides an efficient and precise solution for foundation pit deformation prediction while offering new insights into multi-modal robotic perception and engineering monitoring applications.
Keywords: contrastive learning; deep learning; foundation pit deformation prediction; multi-modal robotics; multi-scale features.
Copyright © 2025 Wenbo, Tingting and Xiao.
Conflict of interest statement
LX was employed by Guangdong Nonferrous Industry Building Quality Inspection Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures
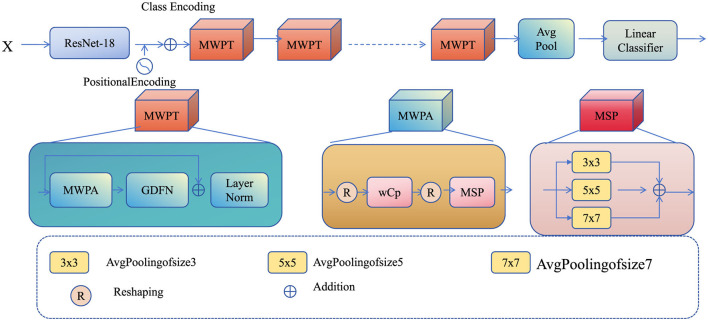
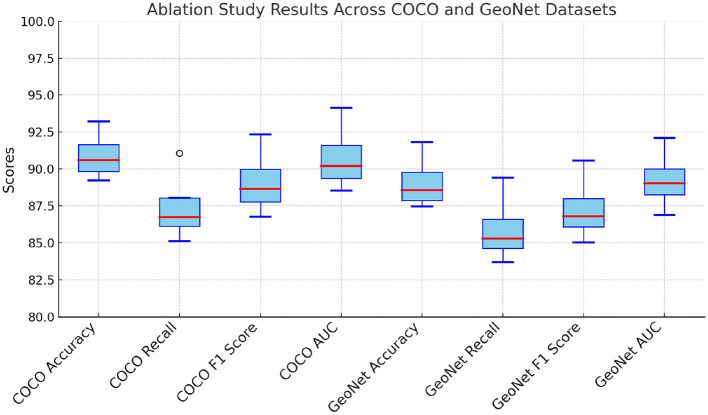
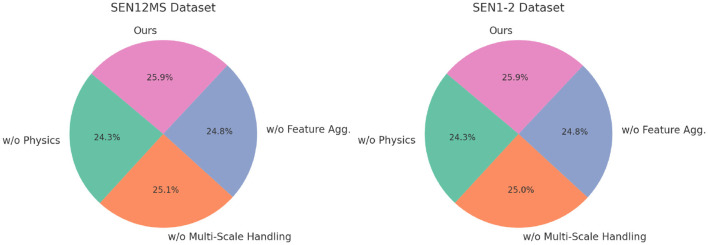
References
-
- Cao H., Zhang Z., Xia Y., Li X., Xia J., Chen G., et al. . (2024). “Embracing events and frames with hierarchical feature refinement network for object detection,” in European Conference on Computer Vision (Cham: Springer; ), 161–177. 10.1007/978-3-031-72907-2_10 - DOI
-
- Chai W., Wang G. (2022). Deep vision multimodal learning: Methodology, benchmark, and trend. Appl. Sci. 12:6588. 10.3390/app12136588 - DOI
-
- Chango W., Lara J., Cerezo R., Romero C. (2022). A review on data fusion in multimodal learning analytics and educational data mining. WIREs Data Mining Knowl. Discov. 12:e1458. 10.1002/widm.1458 - DOI
-
- Cui Y., Wang Q., Li C., Ren W., Knoll A. (2025). Eenet: an effective and efficient network for single image dehazing. Pattern Recognit. 158:111074. 10.1016/j.patcog.2024.111074 - DOI
LinkOut - more resources
Full Text Sources
Miscellaneous