

Differences in psychologists' cognitive traits are associated with scientific divides
- PMID: 40246997
- PMCID: PMC12185325
- DOI: 10.1038/s41562-025-02153-1
Differences in psychologists' cognitive traits are associated with scientific divides
Abstract
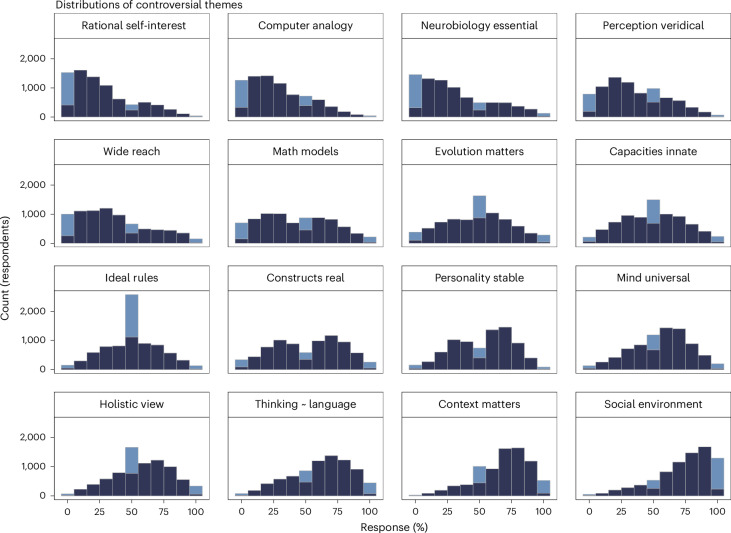
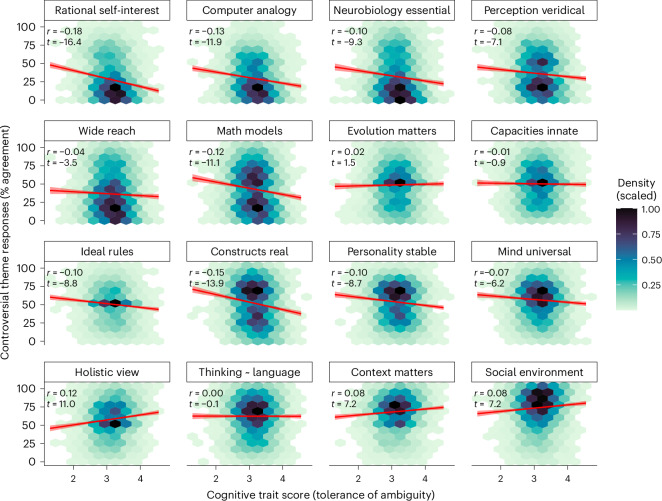
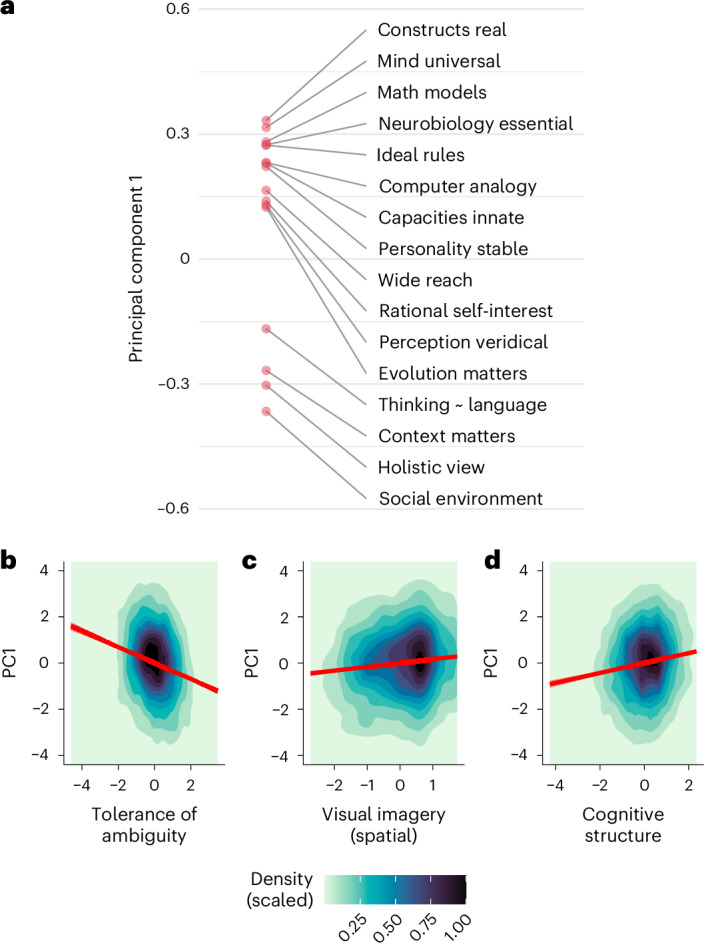
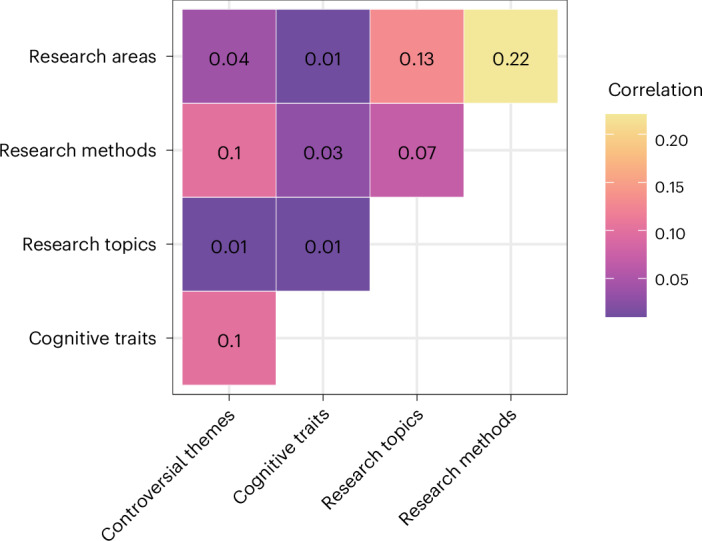
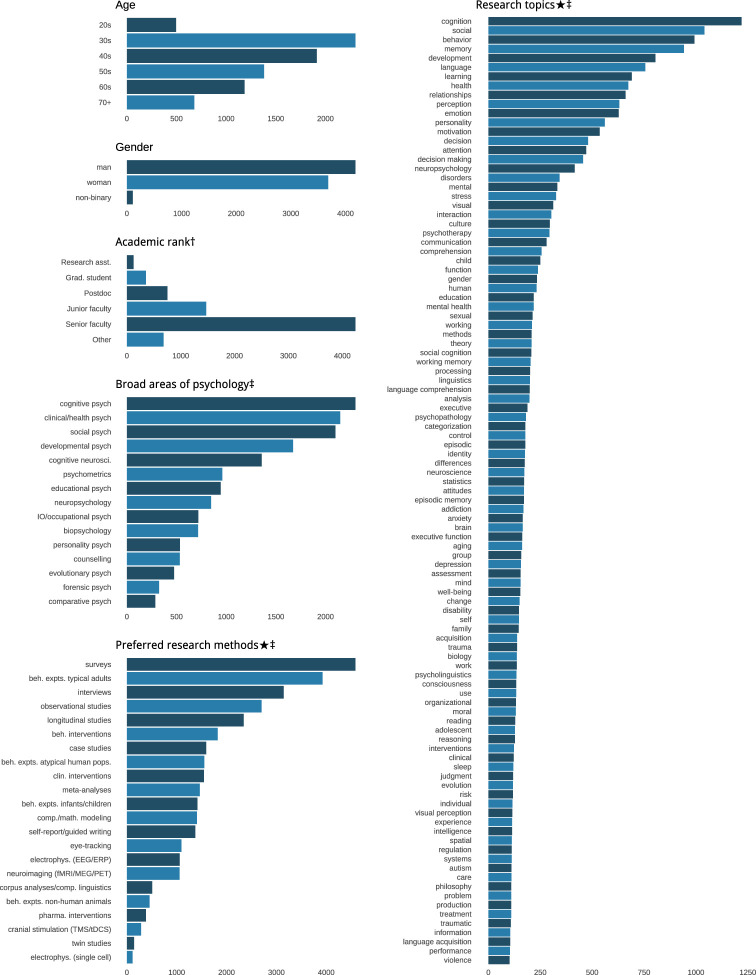
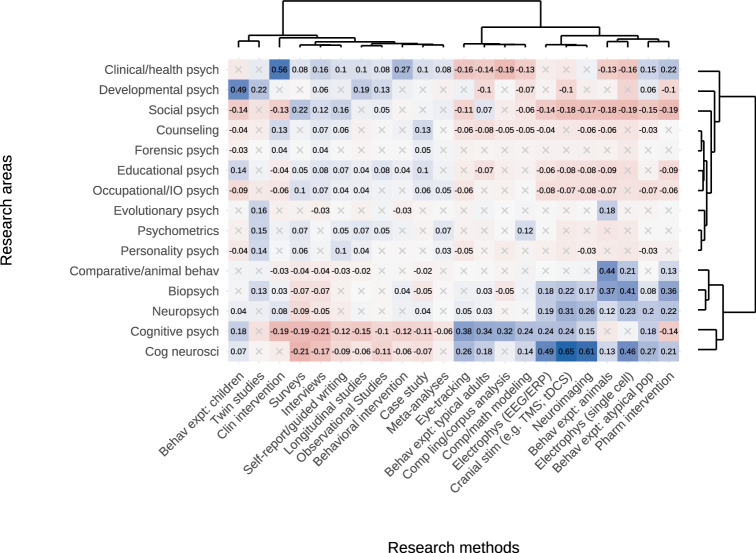
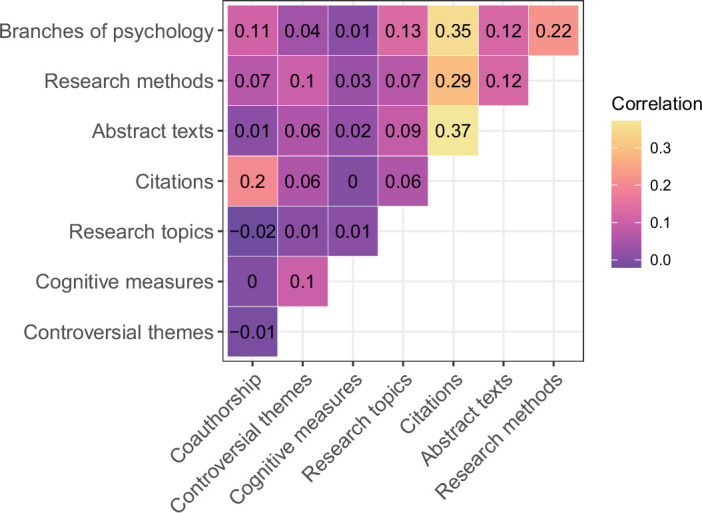
Scientific research is often characterized by schools of thought. We investigate whether these divisions are associated with differences in researchers' cognitive traits such as tolerance for ambiguity. These differences may guide researchers to prefer different problems, tackle identical problems in different ways, and even reach different conclusions when studying the same problems in the same way. We surveyed 7,973 researchers in psychological sciences and investigated links between what they research, their stances on open questions in the field, and their cognitive traits and dispositions. Our results show that researchers' stances on scientific questions are associated with what they research and with their cognitive traits. Further, these associations are detectable in their publication histories. These findings support the idea that divisions in scientific fields reflect differences in the researchers themselves, hinting that some divisions may be more difficult to bridge than suggested by a traditional view of data-driven scientific consensus.
© 2025. The Author(s).
Conflict of interest statement
Competing interests: J.E. has a commercial affiliation with Google, but Google had no role in the design and analysis of this study. The other authors declare no competing interests.
Figures








Similar articles
-
How lived experiences of illness trajectories, burdens of treatment, and social inequalities shape service user and caregiver participation in health and social care: a theory-informed qualitative evidence synthesis.Health Soc Care Deliv Res. 2025 Jun;13(24):1-120. doi: 10.3310/HGTQ8159. Health Soc Care Deliv Res. 2025. PMID: 40548558
-
Home treatment for mental health problems: a systematic review.Health Technol Assess. 2001;5(15):1-139. doi: 10.3310/hta5150. Health Technol Assess. 2001. PMID: 11532236
-
Factors that influence parents' and informal caregivers' views and practices regarding routine childhood vaccination: a qualitative evidence synthesis.Cochrane Database Syst Rev. 2021 Oct 27;10(10):CD013265. doi: 10.1002/14651858.CD013265.pub2. Cochrane Database Syst Rev. 2021. PMID: 34706066 Free PMC article.
-
Behavioral interventions to reduce risk for sexual transmission of HIV among men who have sex with men.Cochrane Database Syst Rev. 2008 Jul 16;(3):CD001230. doi: 10.1002/14651858.CD001230.pub2. Cochrane Database Syst Rev. 2008. PMID: 18646068
-
Maternal and neonatal outcomes of elective induction of labor.Evid Rep Technol Assess (Full Rep). 2009 Mar;(176):1-257. Evid Rep Technol Assess (Full Rep). 2009. PMID: 19408970 Free PMC article.
References
-
- Campbell, D. T. in The Social Psychology of Science (eds Shadish, W. & Fuller, S.) Ch. 2 (Guilford Press, 1994).
-
- Gergen, K. The social constructionist movement in modern psychology. Am Psychol.40, 266–275 (1985).
-
- Maines, D. The social construction of meaning. Contemp. Sociol.29, 577–584 (2000).
-
- Zerubavel, E. The five pillars of essentialism: reification and the social construction of an objective reality. Cult. Sociol.10, 69–76 (2016).
MeSH terms
LinkOut - more resources
Full Text Sources
