

Evaluating the Performance and Safety of Large Language Models in Generating Type 2 Diabetes Mellitus Management Plans: A Comparative Study With Physicians Using Real Patient Records
- PMID: 40248538
- PMCID: PMC12003111
- DOI: 10.7759/cureus.80737
Evaluating the Performance and Safety of Large Language Models in Generating Type 2 Diabetes Mellitus Management Plans: A Comparative Study With Physicians Using Real Patient Records
Abstract
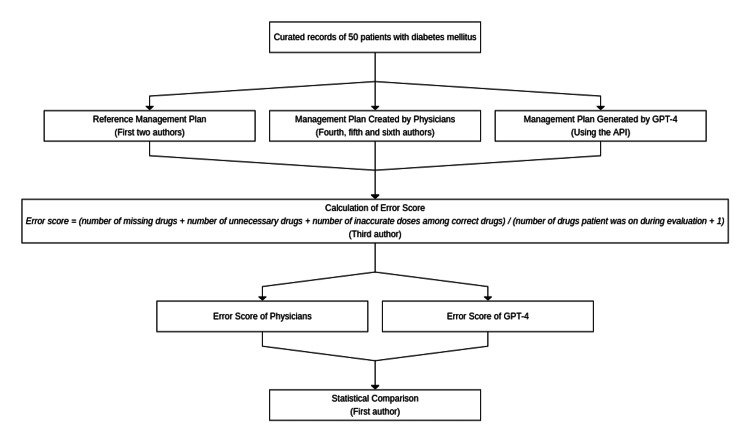
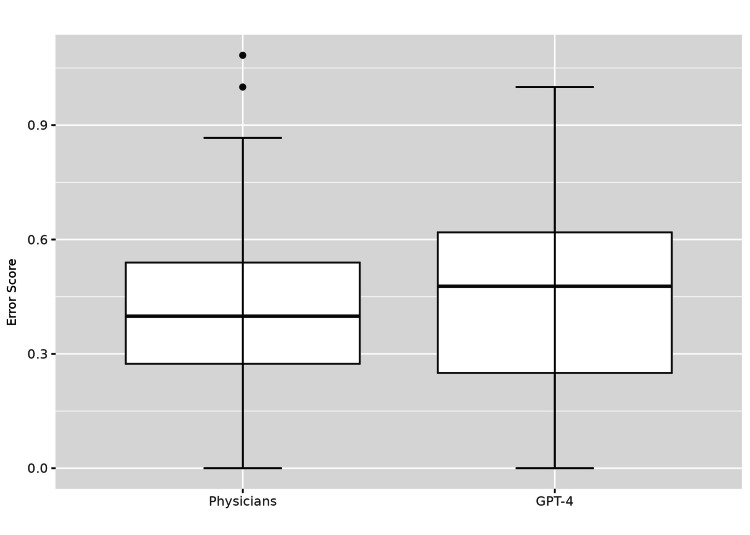
Background The integration of large language models (LLMs) such as GPT-4 into healthcare presents potential benefits and challenges. While LLMs show promise in applications ranging from scientific writing to personalized medicine, their practical utility and safety in clinical settings remain under scrutiny. Concerns about accuracy, ethical considerations, and bias necessitate rigorous evaluation of these technologies against established medical standards. Methods This study involved a comparative analysis using anonymized patient records from a healthcare setting in the state of West Bengal, India. Management plans for 50 patients with type 2 diabetes mellitus were generated by GPT-4 and three physicians, who were blinded to each other's responses. These plans were evaluated against a reference management plan based on American Diabetes Society guidelines. Completeness, necessity, and dosage accuracy were quantified and a Prescribing Error Score was devised to assess the quality of the generated management plans. The safety of the management plans generated by GPT-4 was also assessed. Results Results indicated that physicians' management plans had fewer missing medications compared to those generated by GPT-4 (p=0.008). However, GPT-4-generated management plans included fewer unnecessary medications (p=0.003). No significant difference was observed in the accuracy of drug dosages (p=0.975). The overall error scores were comparable between physicians and GPT-4 (p=0.301). Safety issues were noted in 16% of the plans generated by GPT-4, highlighting potential risks associated with AI-generated management plans. Conclusion The study demonstrates that while GPT-4 can effectively reduce unnecessary drug prescriptions, it does not yet match the performance of physicians in terms of plan completeness. The findings support the use of LLMs as supplementary tools in healthcare, highlighting the need for enhanced algorithms and continuous human oversight to ensure the efficacy and safety of artificial intelligence in clinical settings.
Keywords: artificial intelligence in medicine; clinical decision support system; diabetes mellitus type 2; large language model(llm); oral hypoglycemic agents.
Copyright © 2025, Mondal et al.
Conflict of interest statement
Human subjects: Consent for treatment and open access publication was obtained or waived by all participants in this study. Clinimed Independent Ethics Committee, Kolkata issued approval CLPL/CIEC/001/2024 dated May 11, 2024. Animal subjects: All authors have confirmed that this study did not involve animal subjects or tissue. Conflicts of interest: In compliance with the ICMJE uniform disclosure form, all authors declare the following: Payment/services info: All authors have declared that no financial support was received from any organization for the submitted work. Financial relationships: All authors have declared that they have no financial relationships at present or within the previous three years with any organizations that might have an interest in the submitted work. Other relationships: All authors have declared that there are no other relationships or activities that could appear to have influenced the submitted work.
Figures
References
-
- GPT-4 technical report [PREPRINT] OpenAI OpenAI, Achiam J, Adler S, et al. arXiv. 2023
LinkOut - more resources
Full Text Sources