

Large Language Models: Pioneering New Educational Frontiers in Childhood Myopia
- PMID: 40257570
- PMCID: PMC12069199
- DOI: 10.1007/s40123-025-01142-x
Large Language Models: Pioneering New Educational Frontiers in Childhood Myopia
Abstract
Introduction: This study aimed to evaluate the performance of three large language models (LLMs), namely ChatGPT-3.5, ChatGPT-4o (o1 Preview), and Google Gemini, in producing patient education materials (PEMs) and improving the readability of online PEMs on childhood myopia.
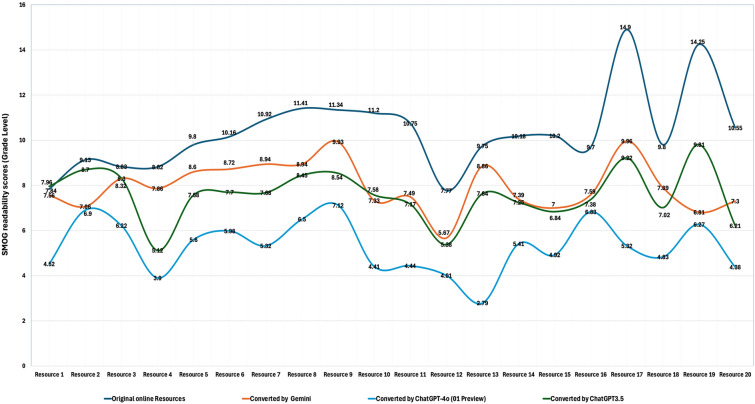
Methods: LLM-generated responses were assessed using three prompts. Prompt A requested to "Write educational material on childhood myopia." Prompt B added a modifier specifying "a sixth-grade reading level using the FKGL (Flesch-Kincaid Grade Level) readability formula." Prompt C aimed to rewrite existing PEMs to a sixth-grade level using FKGL. Reponses were assessed for quality (DISCERN tool), readability (FKGL, SMOG (Simple Measure of Gobbledygook)), Patient Education Materials Assessment Tool (PEMAT, understandability/actionability), and accuracy.
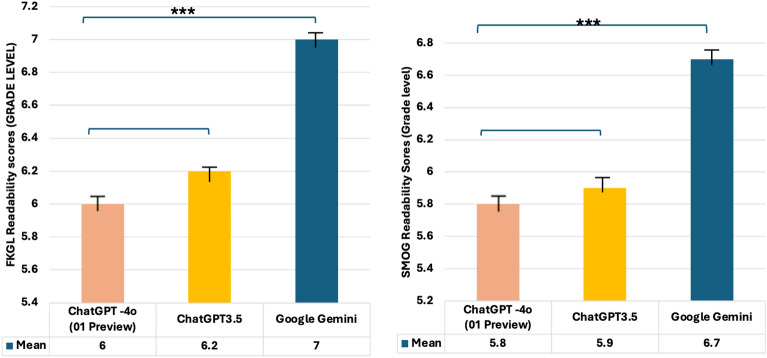
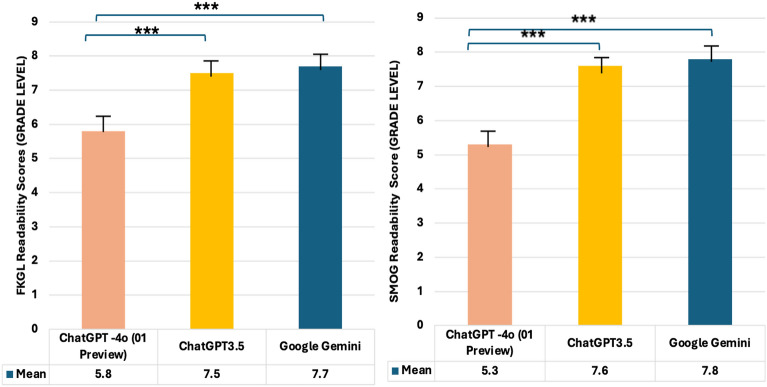
Results: ChatGPT-4o (01) and ChatGPT-3.5 generated good-quality PEMs (DISCERN 52.8 and 52.7, respectively); however, quality declined from prompt A to prompt B (p = 0.001 and p = 0.013). Google Gemini produced fair-quality (DISCERN 43) but improved with prompt B (p = 0.02). All PEMs exceeded the 70% PEMAT understandability threshold but failed the 70% actionability threshold (40%). No misinformation was identified. Readability improved with prompt B; ChatGPT-4o (01) and ChatGPT-3.5 achieved a sixth-grade level or below (FGKL 6 ± 0.6 and 6.2 ± 0.3), while Google Gemini did not (FGKL 7 ± 0.6). ChatGPT-4o (01) outperformed Google Gemini in readability (p < 0.001) but was comparable to ChatGPT-3.5 (p = 0.846). Prompt C improved readability across all LLMs, with ChatGPT-4o (o1 Preview) showing the most significant gains (FKGL 5.8 ± 1.5; p < 0.001).
Conclusions: ChatGPT-4o (o1 Preview) demonstrates potential in producing accurate, good-quality, understandable PEMs, and in improving online PEMs on childhood myopia.
Keywords: Childhood myopia; Large language models; Patient education materials.
© 2025. The Author(s).
Conflict of interest statement
Declarations. Conflict of Interest: Mohammad Delsoz, Amr Hassan, Amin Nabavi, Amir Rahdar, Brian Fowler, Natalie C. Kerr, Lauren Claire Ditta, Mary E. Hoehn, Margaret M DeAngelis, and Yih-Chung Tham have nothing to disclose. Andrzej Grzybowski is an Editorial Board member of Ophthalmology and Therapy. Andrzej Grzybowski was not involved in the selection of peer reviewers for the manuscript nor any of the subsequent editorial decisions. Siamak Yousefi: Received prototype instruments from Remidio, M&S Technologies, and Visrtucal Fields. He gives consultations to the InsihgtAEye and Enolink. Ethical Approval: The study was exempt from ethical review of The University of Tennessee Health Science Center as it did not involve human participants or their personal data, focusing instead on evaluating the performance of the latest AI models. The focus on publicly available data and AI-generated text ensured compliance with privacy and research ethics standards. The study took place from October to December 2024, following the principles of the Declaration of Helsinki.
Figures
References
-
- Liang J, Pu Y, Chen J, et al. Global prevalence, trend and projection of myopia in children and adolescents from 1990 to 2050: a comprehensive systematic review and meta-analysis. Br J Ophthalmol. 2024. 10.1136/bjo-2024-325427. - PubMed
-
- Modjtahedi BS, Ferris FL, Hunter DG, Fong DS. Public health burden and potential interventions for myopia. Ophthalmology. 2018;125(5):628–30. - PubMed
-
- Schweitzer K. With nearsightedness in children on the rise, experts push for outdoor time, disease designation. JAMA. 2024;332(19):1599–601. 10.1001/jama.2024.21043. - PubMed
-
- Huang J, Wen D, Wang Q, et al. Efficacy comparison of 16 interventions for myopia control in children: a network meta-analysis. Ophthalmology. 2016;123(4):697–708. - PubMed
LinkOut - more resources
Full Text Sources
