

Benchmark evaluation of DeepSeek large language models in clinical decision-making
- PMID: 40267970
- PMCID: PMC12353792
- DOI: 10.1038/s41591-025-03727-2
Benchmark evaluation of DeepSeek large language models in clinical decision-making
Abstract
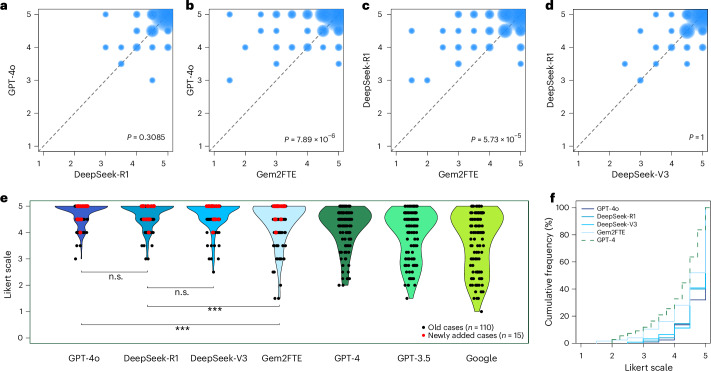
Large language models (LLMs) are increasingly transforming medical applications. However, proprietary models such as GPT-4o face significant barriers to clinical adoption because they cannot be deployed on site within healthcare institutions, making them noncompliant with stringent privacy regulations. Recent advancements in open-source LLMs such as DeepSeek models offer a promising alternative because they allow efficient fine-tuning on local data in hospitals with advanced information technology infrastructure. Here, to demonstrate the clinical utility of DeepSeek-V3 and DeepSeek-R1, we benchmarked their performance on clinical decision support tasks against proprietary LLMs, including GPT-4o and Gemini-2.0 Flash Thinking Experimental. Using 125 patient cases with sufficient statistical power, covering a broad range of frequent and rare diseases, we found that DeepSeek models perform equally well and in some cases better than proprietary LLMs. Our study demonstrates that open-source LLMs can provide a scalable pathway for secure model training enabling real-world medical applications in accordance with data privacy and healthcare regulations.
© 2025. The Author(s).
Conflict of interest statement
Competing interests: The authors declare no competing interests.
Figures



References
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
