

Utilizing Large language models to select literature for meta-analysis shows workload reduction while maintaining a similar recall level as manual curation
- PMID: 40295957
- PMCID: PMC12036192
- DOI: 10.1186/s12874-025-02569-3
Utilizing Large language models to select literature for meta-analysis shows workload reduction while maintaining a similar recall level as manual curation
Abstract
Background: Large language models (LLMs) like ChatGPT showed great potential in aiding medical research. A heavy workload in filtering records is needed during the research process of evidence-based medicine, especially meta-analysis. However, few studies tried to use LLMs to help screen records in meta-analysis.
Objective: In this research, we aimed to explore the possibility of incorporating multiple LLMs to facilitate the screening step based on the title and abstract of records during meta-analysis.
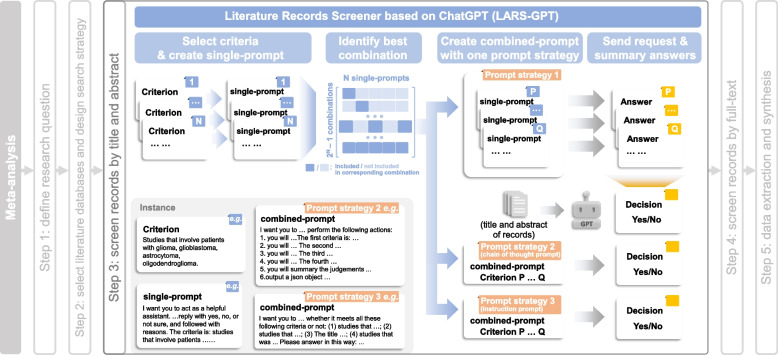
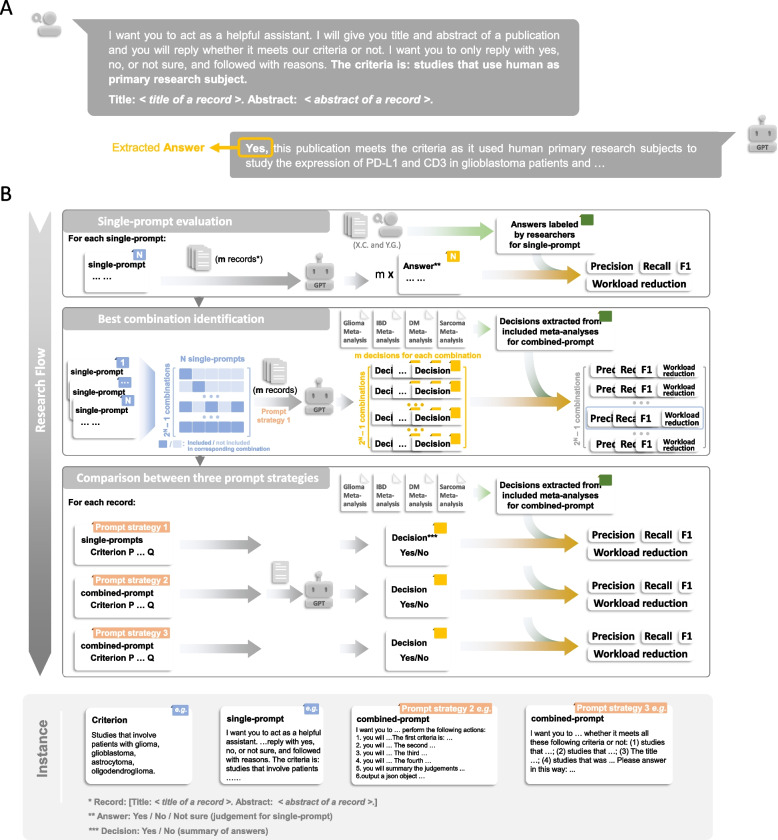
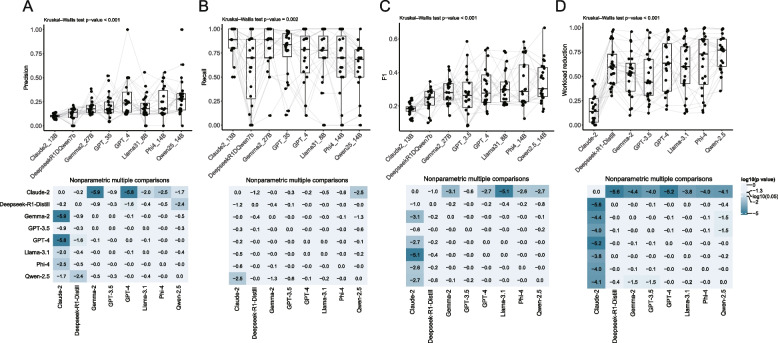
Methods: Various LLMs were evaluated, which includes GPT-3.5, GPT-4, Deepseek-R1-Distill, Qwen-2.5, Phi-4, Llama-3.1, Gemma-2 and Claude-2. To assess our strategy, we selected three meta-analyses from the literature, together with a glioma meta-analysis embedded in the study, as additional validation. For the automatic selection of records from curated meta-analyses, a four-step strategy called LARS-GPT was developed, consisting of (1) criteria selection and single-prompt (prompt with one criterion) creation, (2) best combination identification, (3) combined-prompt (prompt with one or more criteria) creation, and (4) request sending and answer summary. Recall, workload reduction, precision, and F1 score were calculated to assess the performance of LARS-GPT.
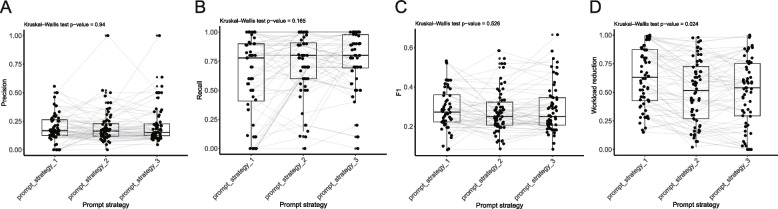
Results: A variable performance was found between different single-prompts, with a mean recall of 0.800. Based on these single-prompts, we were able to find combinations with better performance than the pre-set threshold. Finally, with a best combination of criteria identified, LARS-GPT showed a 40.1% workload reduction on average with a recall greater than 0.9.
Conclusions: We show here the groundbreaking finding that automatic selection of literature for meta-analysis is possible with LLMs. We provide it here as a pipeline, LARS-GPT, which showed a great workload reduction while maintaining a pre-set recall.
Keywords: ChatGPT; Deepseek; Large language model; Meta-analysis; Phi.
© 2025. The Author(s).
Conflict of interest statement
Declarations. Ethics approval and consent to participate: Not applicable. Consent for publication: Not applicable. Competing interests: The authors declare no competing interests.
Figures
Similar articles
-
Using Large Language Models to Annotate Complex Cases of Social Determinants of Health in Longitudinal Clinical Records.medRxiv [Preprint]. 2024 Apr 27:2024.04.25.24306380. doi: 10.1101/2024.04.25.24306380. medRxiv. 2024. PMID: 38712224 Free PMC article. Preprint.
-
Quality of Answers of Generative Large Language Models Versus Peer Users for Interpreting Laboratory Test Results for Lay Patients: Evaluation Study.J Med Internet Res. 2024 Apr 17;26:e56655. doi: 10.2196/56655. J Med Internet Res. 2024. PMID: 38630520 Free PMC article.
-
Cancer Vaccine Adjuvant Name Recognition from Biomedical Literature using Large Language Models.ArXiv [Preprint]. 2025 Feb 12:arXiv:2502.09659v1. ArXiv. 2025. PMID: 40196147 Free PMC article. Preprint.
-
An Empirical Evaluation of Prompting Strategies for Large Language Models in Zero-Shot Clinical Natural Language Processing: Algorithm Development and Validation Study.JMIR Med Inform. 2024 Apr 8;12:e55318. doi: 10.2196/55318. JMIR Med Inform. 2024. PMID: 38587879 Free PMC article.
-
Assessing the Application of Large Language Models in Generating Dermatologic Patient Education Materials According to Reading Level: Qualitative Study.JMIR Dermatol. 2024 May 16;7:e55898. doi: 10.2196/55898. JMIR Dermatol. 2024. PMID: 38754096 Free PMC article.
Cited by
-
The emergence of large language models as tools in literature reviews: a large language model-assisted systematic review.J Am Med Inform Assoc. 2025 Jun 1;32(6):1071-1086. doi: 10.1093/jamia/ocaf063. J Am Med Inform Assoc. 2025. PMID: 40332983 Free PMC article.
References
-
- Subbiah V. The next generation of evidence-based medicine. Nat Med. 2023;29(1):49–58. - PubMed
-
- Abdelkader W, Navarro T, Parrish R, Cotoi C, Germini F, Linkins LA, et al. A Deep Learning Approach to Refine the Identification of High-Quality Clinical Research Articles From the Biomedical Literature: Protocol for Algorithm Development and Validation. JMIR Res Protoc. 2021;10(11):e29398. - PMC - PubMed
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
