

Massive experimental quantification allows interpretable deep learning of protein aggregation
- PMID: 40305601
- PMCID: PMC12042874
- DOI: 10.1126/sciadv.adt5111
Massive experimental quantification allows interpretable deep learning of protein aggregation
Abstract
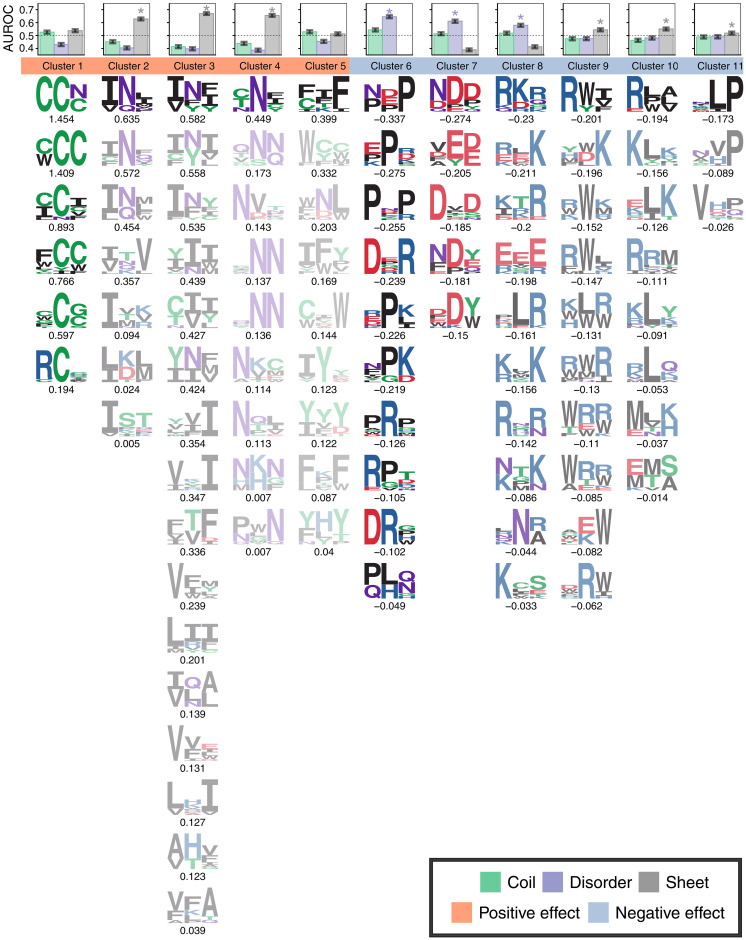
Protein aggregation is a pathological hallmark of more than 50 human diseases and a major problem for biotechnology. Methods have been proposed to predict aggregation from sequence, but these have been trained and evaluated on small and biased experimental datasets. Here we directly address this data shortage by experimentally quantifying the aggregation of >100,000 protein sequences. This unprecedented dataset reveals the limited performance of existing computational methods and allows us to train CANYA, a convolution-attention hybrid neural network that accurately predicts aggregation from sequence. We adapt genomic neural network interpretability analyses to reveal CANYA's decision-making process and learned grammar. Our results illustrate the power of massive experimental analysis of random sequence-spaces and provide an interpretable and robust neural network model to predict aggregation.
Figures






Update of
-
Massive experimental quantification of amyloid nucleation allows interpretable deep learning of protein aggregation.bioRxiv [Preprint]. 2024 Oct 1:2024.07.13.603366. doi: 10.1101/2024.07.13.603366. bioRxiv. 2024. Update in: Sci Adv. 2025 May 2;11(18):eadt5111. doi: 10.1126/sciadv.adt5111. PMID: 39071305 Free PMC article. Updated. Preprint.
References
-
- Chiti F., Dobson C. M., Protein misfolding, amyloid formation, and human disease: A summary of progress over the last decade. Annu. Rev. Biochem. 86, 27–68 (2017). - PubMed
-
- Fowler D. M., Koulov A. V., Balch W. E., Kelly J. W., Functional amyloid--from bacteria to humans. Trends Biochem. Sci. 32, 217–224 (2007). - PubMed
-
- Shire S. J., Formulation and manufacturability of biologics. Curr. Opin. Biotechnol. 20, 708–714 (2009). - PubMed
-
- Ke P. C., Zhou R., Serpell L. C., Riek R., Knowles T. P. J., Lashuel H. A., Gazit E., Hamley I. W., Davis T. P., Fändrich M., Otzen D. E., Chapman M. R., Dobson C. M., Eisenberg D. S., Mezzenga R., Half a century of amyloids: Past, present and future. Chem. Soc. Rev. 49, 5473–5509 (2020). - PMC - PubMed
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
