

Leveraging long context in retrieval augmented language models for medical question answering
- PMID: 40316710
- PMCID: PMC12048518
- DOI: 10.1038/s41746-025-01651-w
Leveraging long context in retrieval augmented language models for medical question answering
Abstract
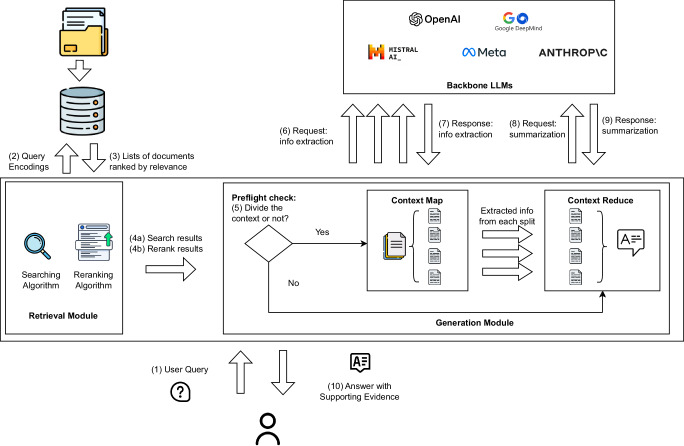
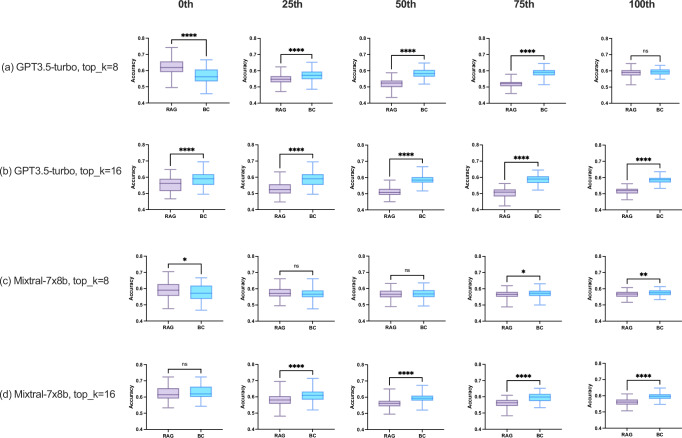
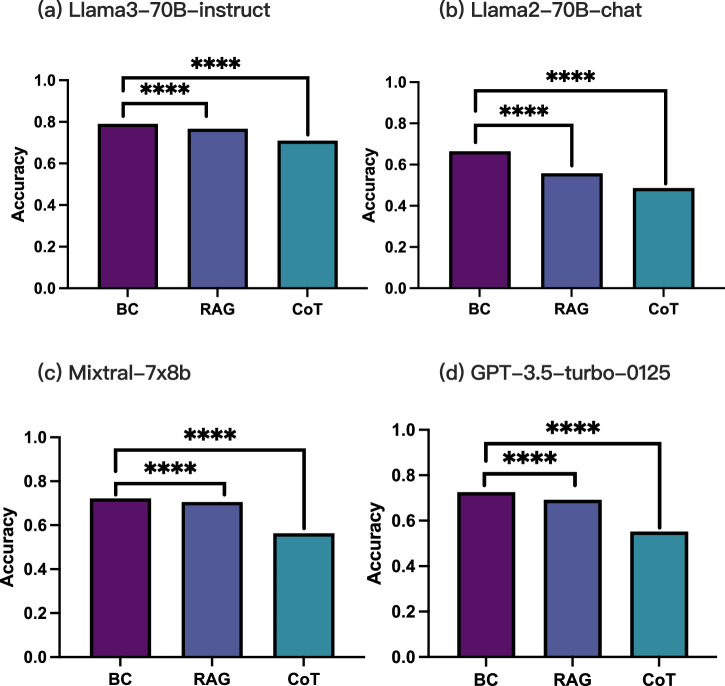
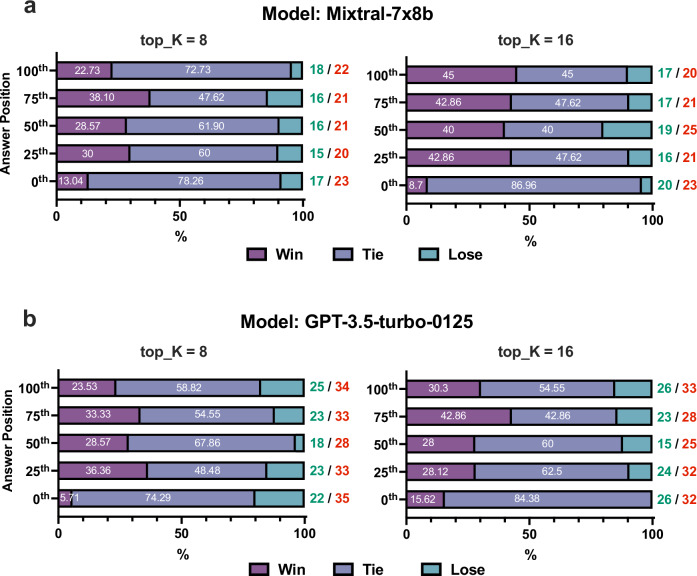
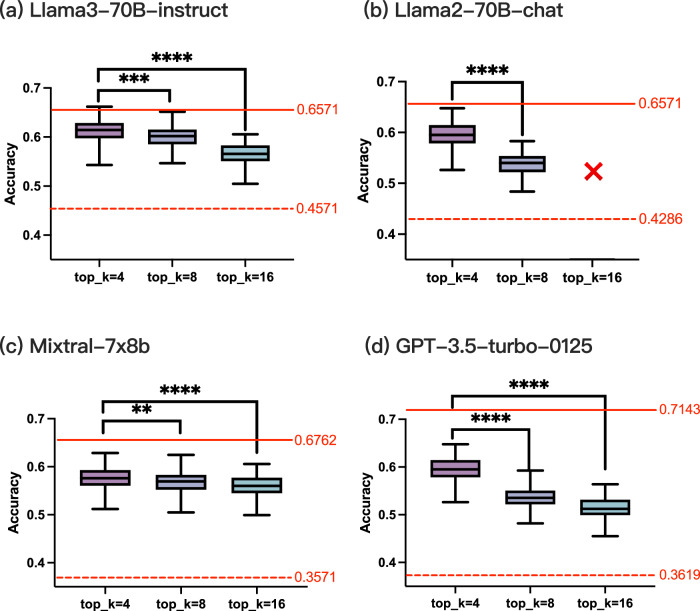
While holding great promise for improving and facilitating healthcare through applications of medical literature summarization, large language models (LLMs) struggle to produce up-to-date responses on evolving topics due to outdated knowledge or hallucination. Retrieval-augmented generation (RAG) is a pivotal innovation that improves the accuracy and relevance of LLM responses by integrating LLMs with a search engine and external sources of knowledge. However, the quality of RAG responses can be largely impacted by the rank and density of key information in the retrieval results, such as the "lost-in-the-middle" problem. In this work, we aim to improve the robustness and reliability of the RAG workflow in the medical domain. Specifically, we propose a map-reduce strategy, BriefContext, to combat the "lost-in-the-middle" issue without modifying the model weights. We demonstrated the advantage of the workflow with various LLM backbones and on multiple QA datasets. This method promises to improve the safety and reliability of LLMs deployed in healthcare domains by reducing the risk of misinformation, ensuring critical clinical content is retained in generated responses, and enabling more trustworthy use of LLMs in critical tasks such as medical question answering, clinical decision support, and patient-facing applications.
© 2025. The Author(s).
Conflict of interest statement
Competing interests: The authors declare no competing interests.
Figures

Similar articles
-
Improving Dietary Supplement Information Retrieval: Development of a Retrieval-Augmented Generation System With Large Language Models.J Med Internet Res. 2025 Mar 19;27:e67677. doi: 10.2196/67677. J Med Internet Res. 2025. PMID: 40106799 Free PMC article.
-
MKRAG: Medical Knowledge Retrieval Augmented Generation for Medical Question Answering.AMIA Annu Symp Proc. 2025 May 22;2024:1011-1020. eCollection 2024. AMIA Annu Symp Proc. 2025. PMID: 40417500 Free PMC article.
-
Use of Retrieval-Augmented Large Language Model for COVID-19 Fact-Checking: Development and Usability Study.J Med Internet Res. 2025 Apr 30;27:e66098. doi: 10.2196/66098. J Med Internet Res. 2025. PMID: 40306628 Free PMC article.
-
RAGing ahead in rheumatology: new language model architectures to tame artificial intelligence.Ther Adv Musculoskelet Dis. 2025 Apr 21;17:1759720X251331529. doi: 10.1177/1759720X251331529. eCollection 2025. Ther Adv Musculoskelet Dis. 2025. PMID: 40292012 Free PMC article. Review.
-
A Review of Large Language Models in Medical Education, Clinical Decision Support, and Healthcare Administration.Healthcare (Basel). 2025 Mar 10;13(6):603. doi: 10.3390/healthcare13060603. Healthcare (Basel). 2025. PMID: 40150453 Free PMC article. Review.
Cited by
-
Federated Knowledge Retrieval Elevates Large Language Model Performance on Biomedical Benchmarks.bioRxiv [Preprint]. 2025 Aug 2:2025.08.01.668022. doi: 10.1101/2025.08.01.668022. bioRxiv. 2025. PMID: 40766637 Free PMC article. Preprint.
-
Using large language models to generate child-friendly education materials on myopia.Digit Health. 2025 Jul 30;11:20552076251362338. doi: 10.1177/20552076251362338. eCollection 2025 Jan-Dec. Digit Health. 2025. PMID: 40755959 Free PMC article.
-
CLEAR: A vision to support clinical evidence lifecycle with continuous learning.J Biomed Inform. 2025 Jul 29;169:104884. doi: 10.1016/j.jbi.2025.104884. Online ahead of print. J Biomed Inform. 2025. PMID: 40744316
References
-
- Haupt, C. E. & Marks, M. AI-Generated Medical Advice—GPT and Beyond. JAMA329, 1349–1350 (2023). - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources
