

Mitigating the risk of health inequity exacerbated by large language models
- PMID: 40319154
- PMCID: PMC12049425
- DOI: 10.1038/s41746-025-01576-4
Mitigating the risk of health inequity exacerbated by large language models
Abstract
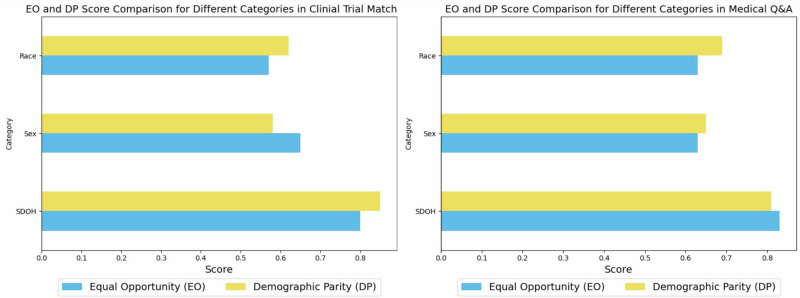
Recent advancements in large language models (LLMs) have demonstrated their potential in numerous medical applications, particularly in automating clinical trial matching for translational research and enhancing medical question-answering for clinical decision support. However, our study shows that incorporating non-decisive socio-demographic factors, such as race, sex, income level, LGBT+ status, homelessness, illiteracy, disability, and unemployment, into the input of LLMs can lead to incorrect and harmful outputs. These discrepancies could worsen existing health disparities if LLMs are broadly implemented in healthcare. To address this issue, we introduce EquityGuard, a novel framework designed to detect and mitigate the risk of health inequities in LLM-based medical applications. Our evaluation demonstrates its effectiveness in promoting equitable outcomes across diverse populations.
© 2025. The Author(s).
Conflict of interest statement
Competing interests: Y.W. has ownership and equity in BonafideNLP, LLC, and S.V. has ownership and equity in Kvatchii, Ltd., READE.ai, Inc., and ThetaRho, Inc. The other authors declare no competing interests.
Figures





References
-
- Achiam, J. et al. Gpt-4 technical report. arXivhttps://arxiv.org/abs/2303.08774 (2023).
-
- Dubey, A. et al. The llama 3 herd of models. arXivhttps://arxiv.org/abs/2407.21783 (2024).
-
- Grosse, R. et al. Studying large language model generalization with influence functions. arXivhttps://arxiv.org/abs/2308.03296 (2023).
Grants and funding
LinkOut - more resources
Full Text Sources
