

Identification of a specific set of genes predicting obesity before phenotype appearance
- PMID: 40330877
- PMCID: PMC12053654
- DOI: 10.1016/j.isci.2025.112377
Identification of a specific set of genes predicting obesity before phenotype appearance
Abstract
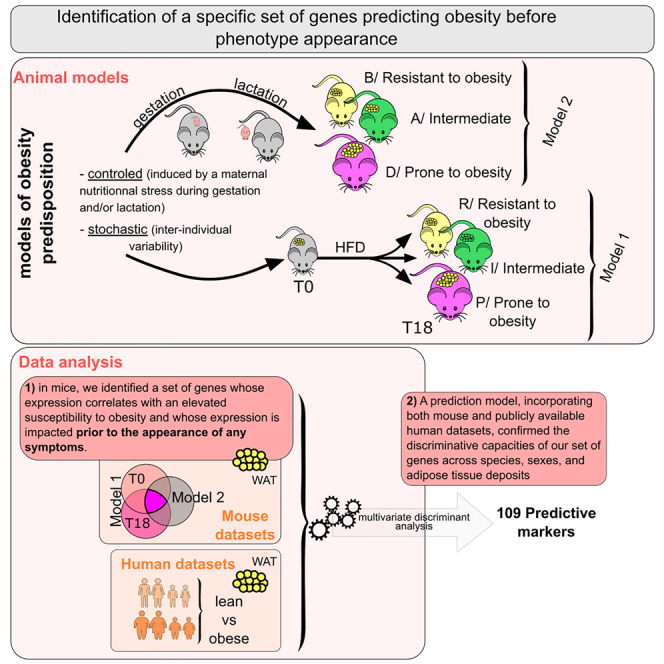
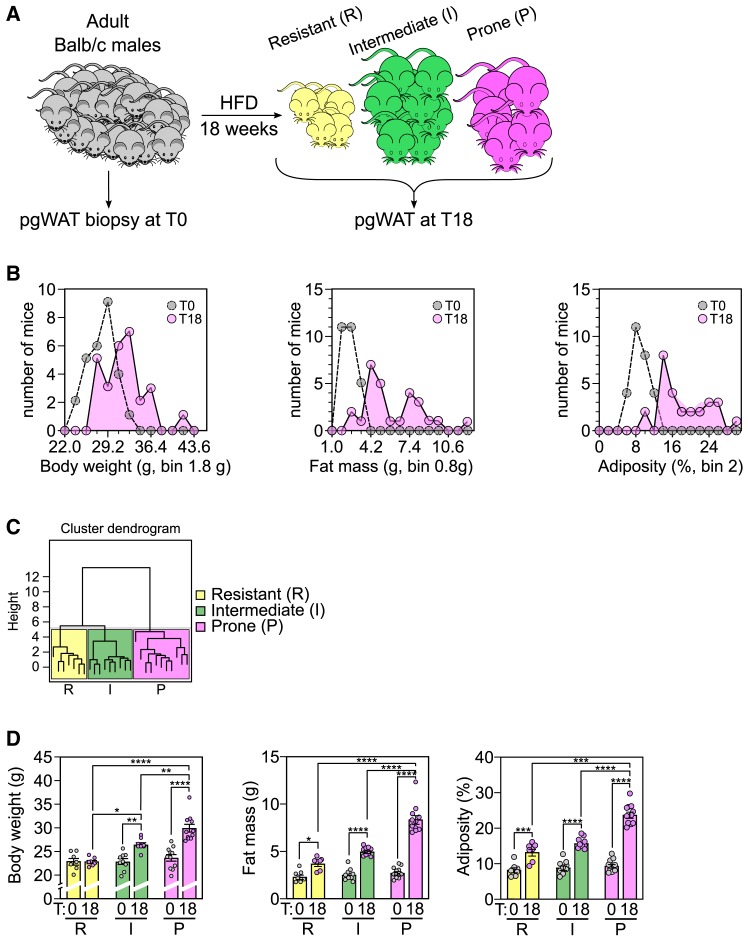
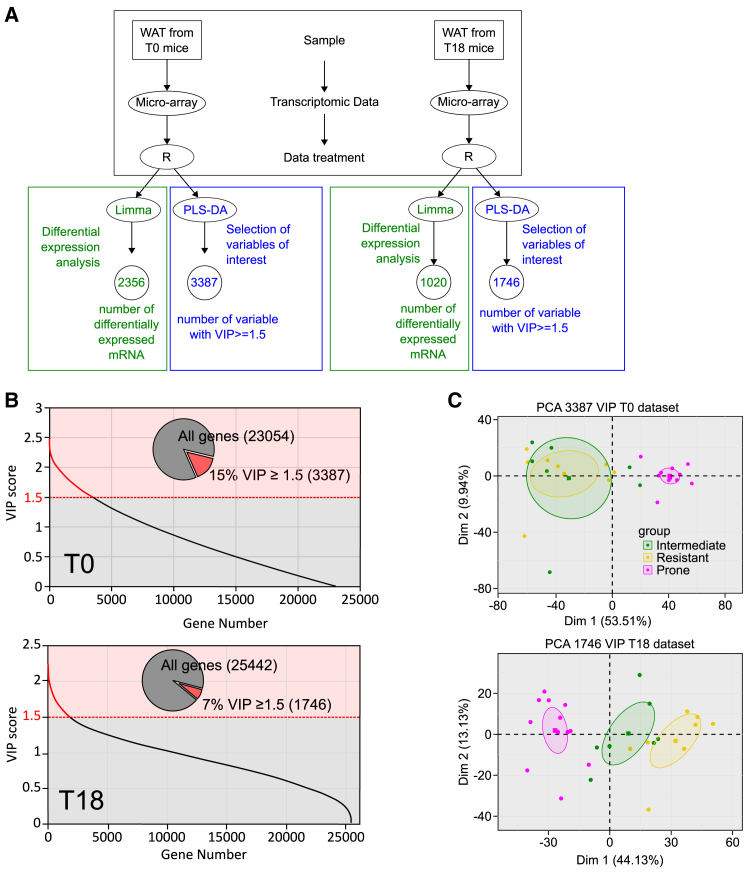
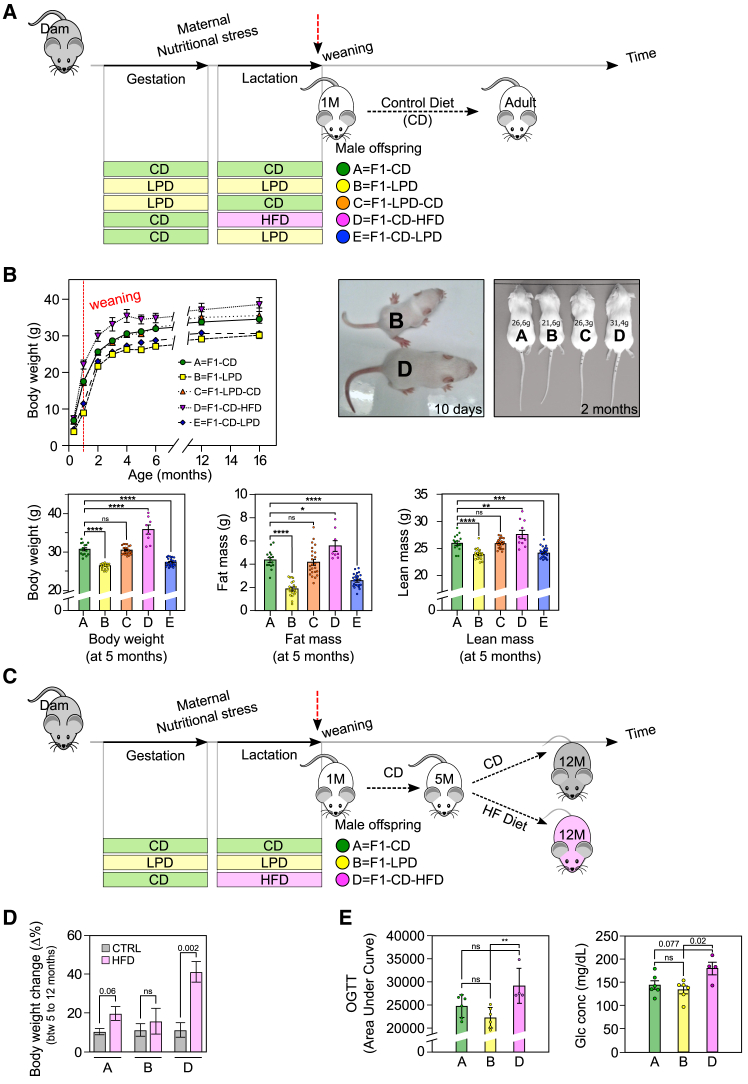
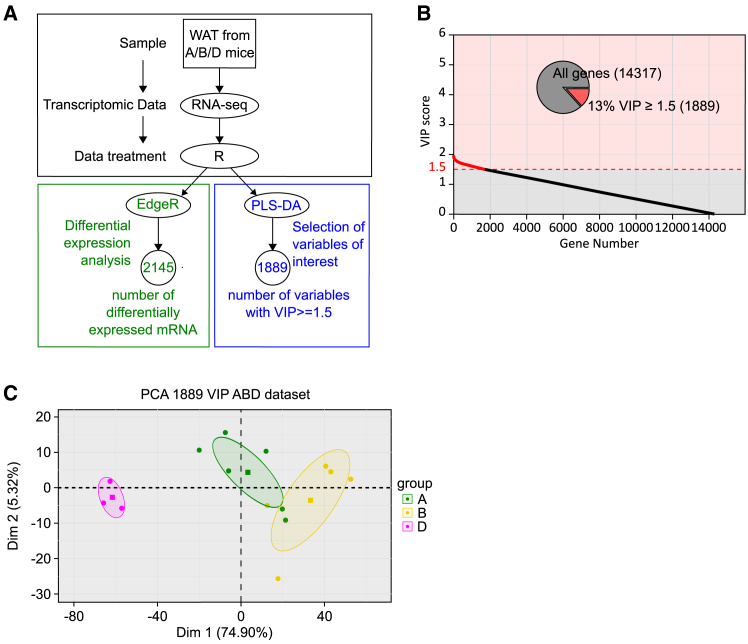
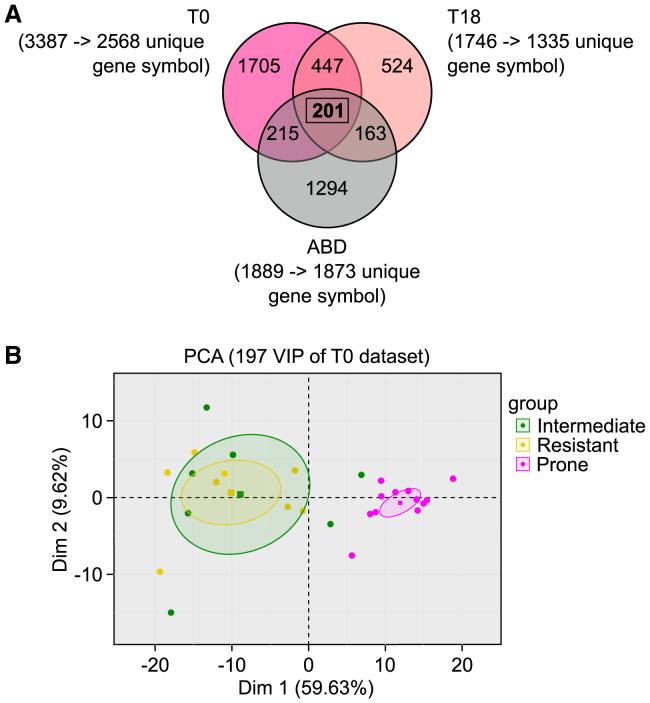
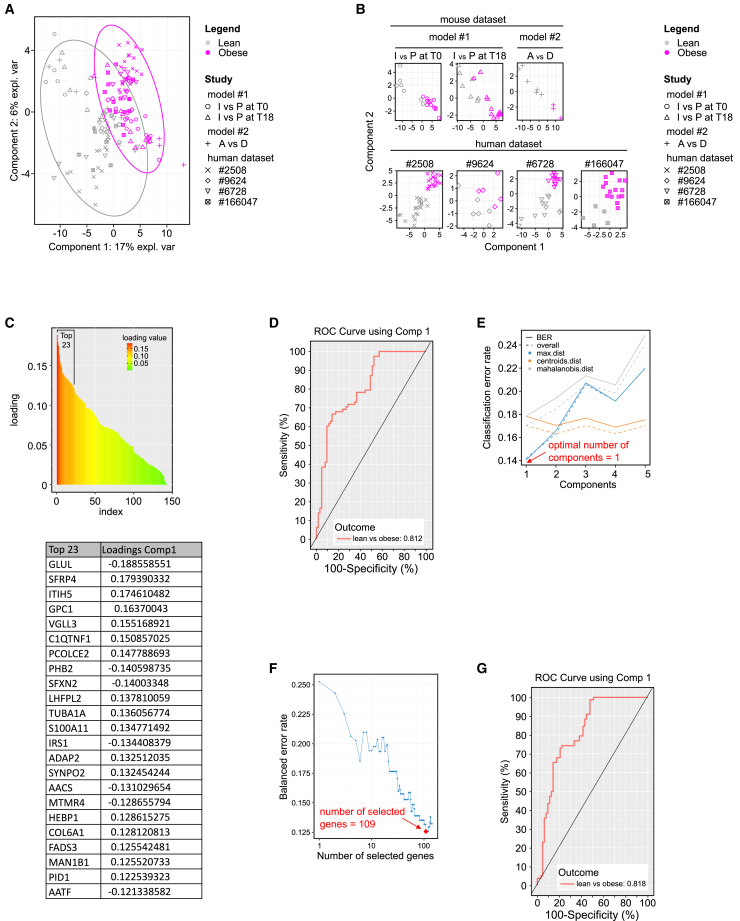
Obesity poses significant health and socioeconomic challenges, necessitating early detection of predisposition for effective personalized prevention. To identify candidate predictive markers, our study used two mouse models: one exhibiting interindividual variability in obesity predisposition and another inducing metabolic phenotypes through maternal nutritional stresses. In both cases, predisposition was assessed by challenging mice with a high-fat diet. Using multivariate analyses of transcriptomic data from white adipose tissue, we identified a set of genes whose expression correlates with an elevated susceptibility to obesity. Importantly, the expression of these genes was impacted prior to the appearance of any symptoms. A prediction model, incorporating both mouse and publicly available human datasets, confirmed the discriminative capacities of our set of genes across species, sexes, and adipose tissue deposits. These genes are promising candidates to serve as diagnostic tools for identifying individuals at risk of obesity.
Keywords: Genetics; Physiology; Transcriptomics.
© 2025 The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
References
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
