

DUX4 activates common and context-specific intergenic transcripts and isoforms
- PMID: 40333962
- PMCID: PMC12057663
- DOI: 10.1126/sciadv.adt5356
DUX4 activates common and context-specific intergenic transcripts and isoforms
Abstract
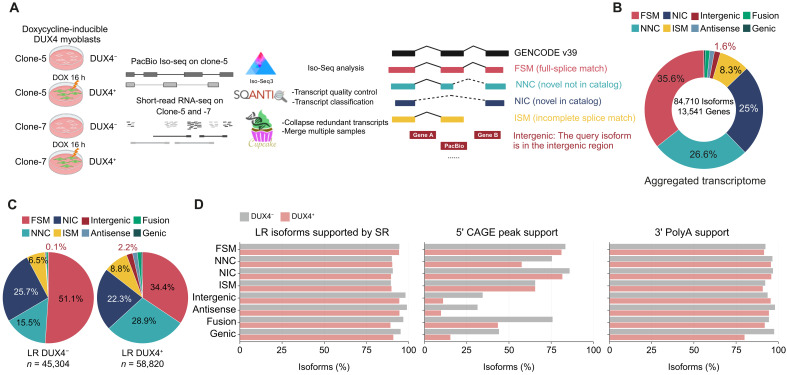
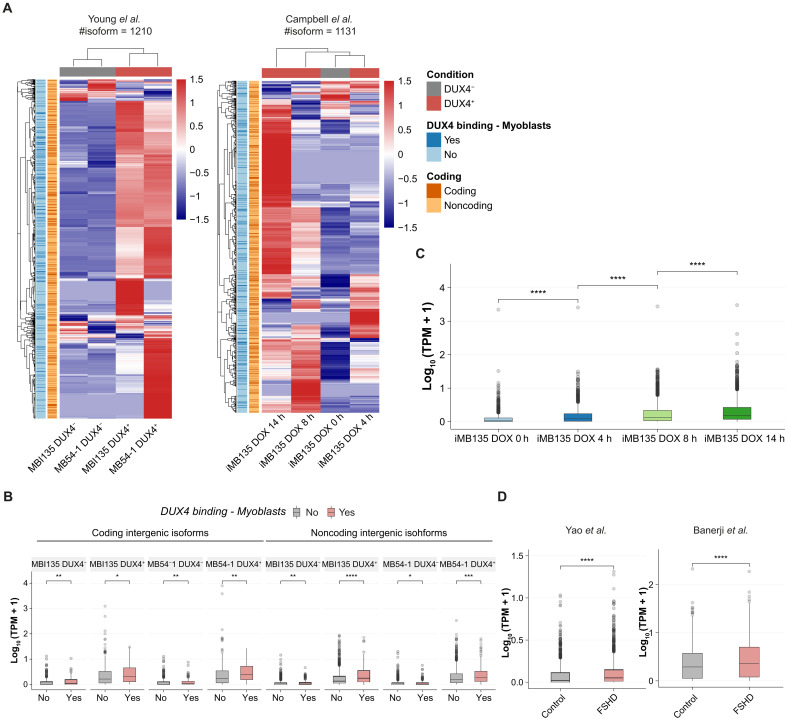
DUX4 regulates the expression of genic and nongenic elements and modulates chromatin accessibility during zygotic genome activation in cleavage stage embryos. Its misexpression in skeletal muscle causes facioscapulohumeral dystrophy (FSHD). By leveraging full-length RNA isoform sequencing with short-read RNA sequencing of DUX4-inducible myoblasts, we elucidate an isoform-resolved transcriptome featuring numerous unannotated isoforms from known loci and novel intergenic loci. While DUX4 activates similar programs in early embryos and FSHD muscle, the isoform usage of known DUX4 targets is notably distinct between the two contexts. DUX4 also activates hundreds of previously unannotated intergenic loci dominated by repetitive elements. The transcriptional and epigenetic profiles of these loci in myogenic and embryonic contexts indicate that the usage of DUX4-binding sites at these intergenic loci is influenced by the cellular environment. These findings demonstrate that DUX4 induces context-specific transcriptomic programs, enriching our understanding of DUX4-induced muscle pathology.
Figures







References
-
- Hendrickson P. G., Doráis J. A., Grow E. J., Whiddon J. L., Lim J.-W., Wike C. L., Weaver B. D., Pflueger C., Emery B. R., Wilcox A. L., Nix D. A., Peterson C. M., Tapscott S. J., Carrell D. T., Cairns B. R., Conserved roles of mouse DUX and human DUX4 in activating cleavage-stage genes and MERVL/HERVL retrotransposons. Nat. Genet. 49, 925–934 (2017). - PMC - PubMed
-
- Geng L. N., Yao Z., Snider L., Fong A. P., Cech J. N., Young J. M., van der Maarel S. M., Ruzzo W. L., Gentleman R. C., Tawil R., Tapscott S. J., DUX4 activates germline genes, retroelements, and immune mediators: Implications for facioscapulohumeral dystrophy. Dev. Cell 22, 38–51 (2012). - PMC - PubMed
-
- Lemmers R. J., van der Vliet P. J., Klooster R., Sacconi S., Camano P., Dauwerse J. G., Snider L., Straasheijm K. R., van Ommen G. J., Padberg G. W., Miller D. G., Tapscott S. J., Tawil R., Frants R. R., van der Maarel S. M., A unifying genetic model for facioscapulohumeral muscular dystrophy. Science 329, 1650–1653 (2010). - PMC - PubMed
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
