

Efficient Detection and Characterization of Targets of Natural Selection Using Transfer Learning
- PMID: 40341942
- PMCID: PMC12062966
- DOI: 10.1093/molbev/msaf094
Efficient Detection and Characterization of Targets of Natural Selection Using Transfer Learning
Abstract
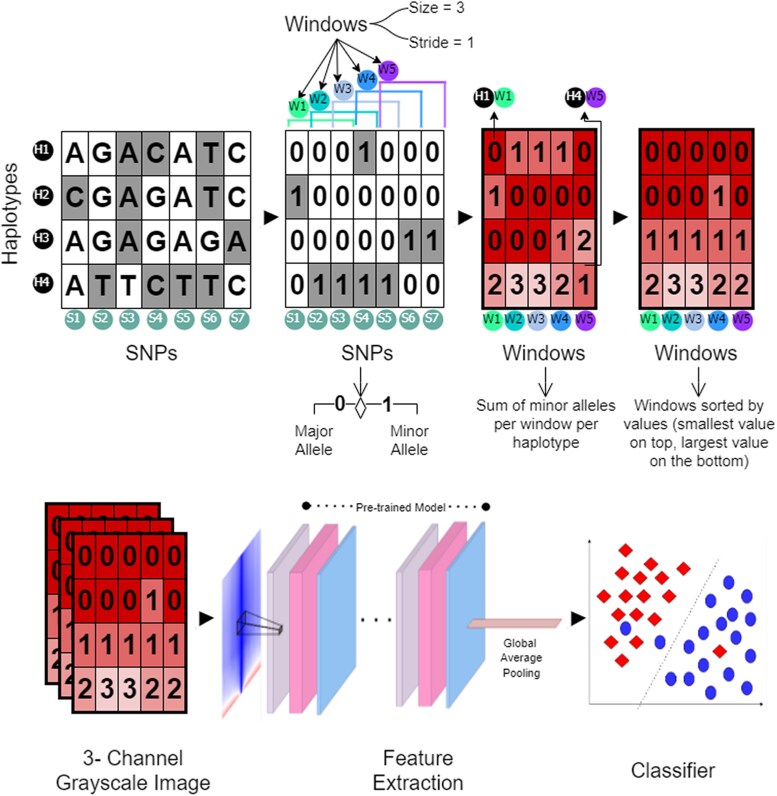
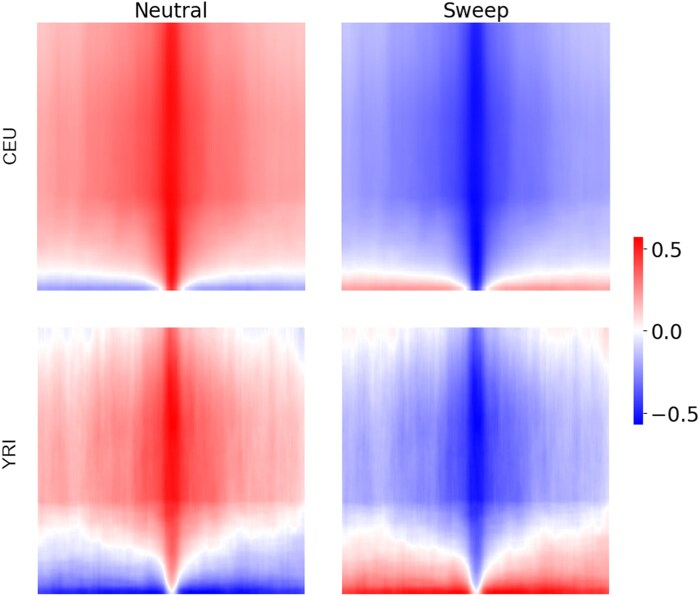
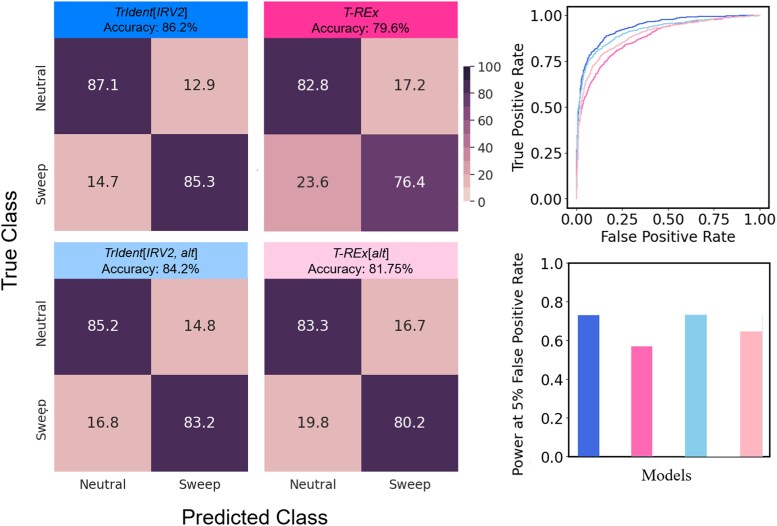
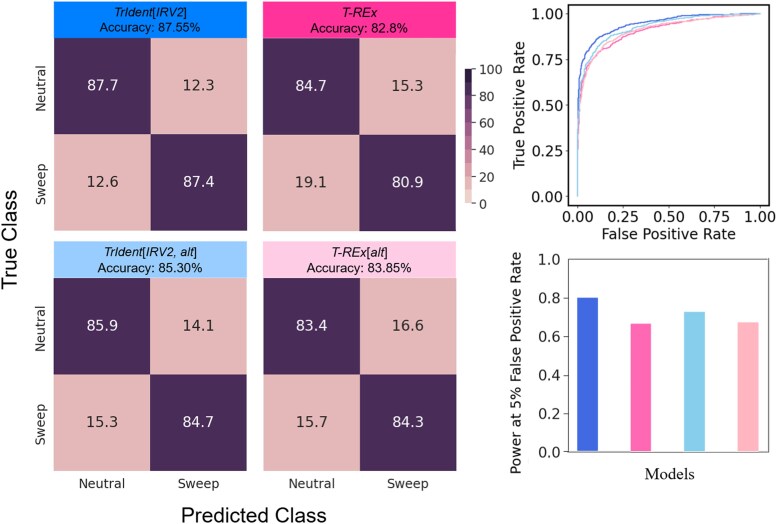
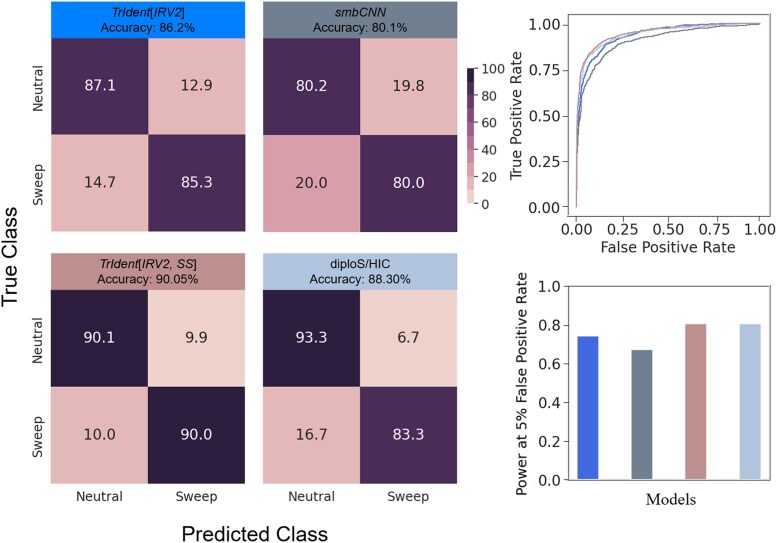
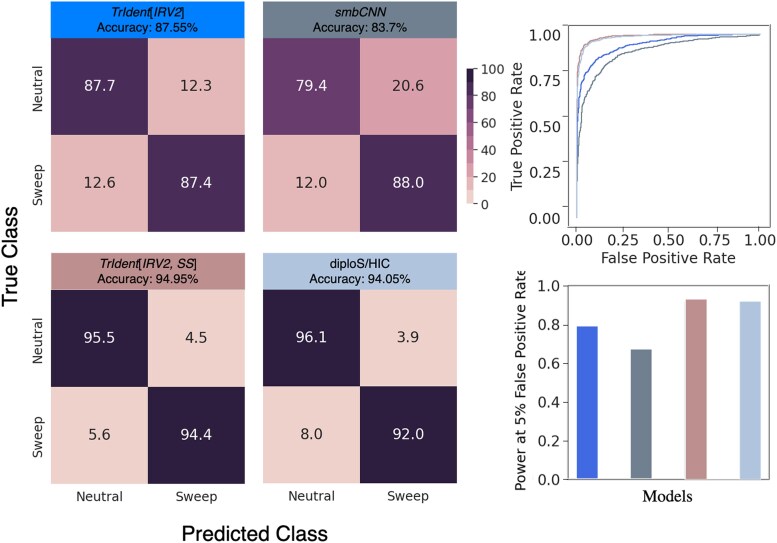
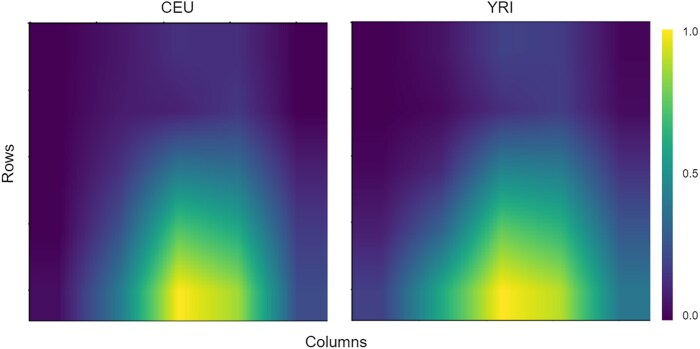
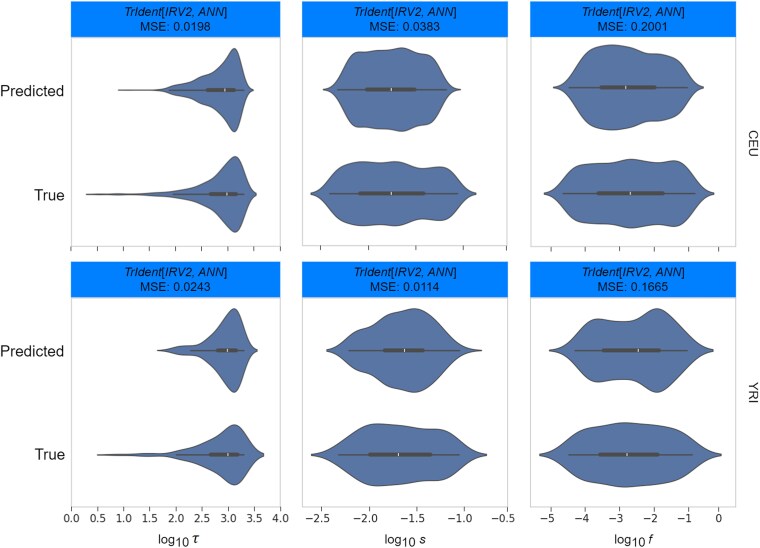
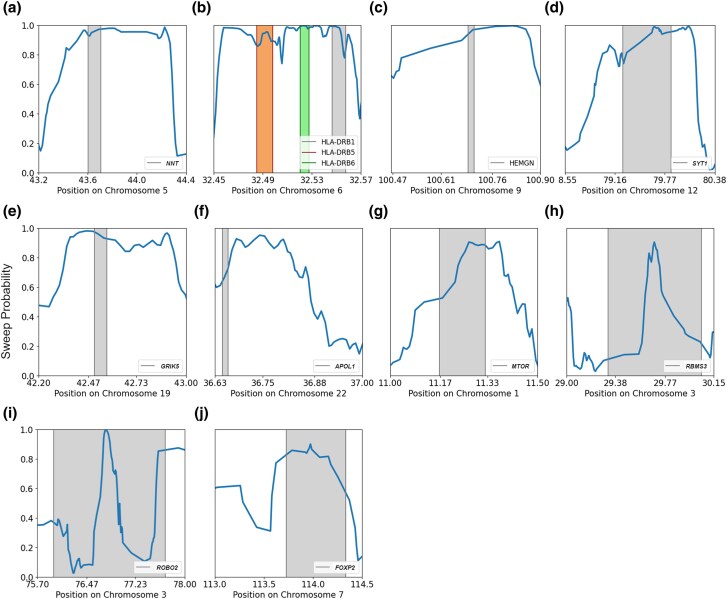
Natural selection leaves detectable patterns of altered spatial diversity within genomes, and identifying affected regions is crucial for understanding species evolution. Recently, machine learning approaches applied to raw population genomic data have been developed to uncover these adaptive signatures. Convolutional neural networks (CNNs) are particularly effective for this task, as they handle large data arrays while maintaining element correlations. However, shallow CNNs may miss complex patterns due to their limited capacity, while deep CNNs can capture these patterns but require extensive data and computational power. Transfer learning addresses these challenges by utilizing a deep CNN pretrained on a large dataset as a feature extraction tool for downstream classification and evolutionary parameter prediction. This approach reduces extensive training data generation requirements and computational needs while maintaining high performance. In this study, we developed TrIdent, a tool that uses transfer learning to enhance detection of adaptive genomic regions from image representations of multilocus variation. We evaluated TrIdent across various genetic, demographic, and adaptive settings, in addition to unphased data and other confounding factors. TrIdent demonstrated improved detection of adaptive regions compared to recent methods using similar data representations. We further explored model interpretability through class activation maps and adapted TrIdent to infer selection parameters for identified adaptive candidates. Using whole-genome haplotype data from European and African populations, TrIdent effectively recapitulated known sweep candidates and identified novel cancer, and other disease-associated genes as potential sweeps.
Keywords: convolutional neural networks; logistic regression; natural selection; population genomics; transfer learning.
© The Author(s) 2025. Published by Oxford University Press on behalf of Society for Molecular Biology and Evolution.
Figures

Update of
-
Efficient detection and characterization of targets of natural selection using transfer learning.bioRxiv [Preprint]. 2025 Mar 6:2025.03.05.641710. doi: 10.1101/2025.03.05.641710. bioRxiv. 2025. Update in: Mol Biol Evol. 2025 Apr 30;42(5):msaf094. doi: 10.1093/molbev/msaf094. PMID: 40093065 Free PMC article. Updated. Preprint.
Similar articles
-
Efficient detection and characterization of targets of natural selection using transfer learning.bioRxiv [Preprint]. 2025 Mar 6:2025.03.05.641710. doi: 10.1101/2025.03.05.641710. bioRxiv. 2025. Update in: Mol Biol Evol. 2025 Apr 30;42(5):msaf094. doi: 10.1093/molbev/msaf094. PMID: 40093065 Free PMC article. Updated. Preprint.
-
Uncovering Footprints of Natural Selection Through Spectral Analysis of Genomic Summary Statistics.Mol Biol Evol. 2023 Jul 5;40(7):msad157. doi: 10.1093/molbev/msad157. Mol Biol Evol. 2023. PMID: 37433019 Free PMC article.
-
On convolutional neural networks for selection inference: Revealing the effect of preprocessing on model learning and the capacity to discover novel patterns.PLoS Comput Biol. 2023 Nov 27;19(11):e1010979. doi: 10.1371/journal.pcbi.1010979. eCollection 2023 Nov. PLoS Comput Biol. 2023. PMID: 38011281 Free PMC article.
-
Breast Cancer Detection Using Convolutional Neural Networks: A Deep Learning-Based Approach.Cureus. 2025 May 3;17(5):e83421. doi: 10.7759/cureus.83421. eCollection 2025 May. Cureus. 2025. PMID: 40322605 Free PMC article. Review.
-
Machine-Learning Prospects for Detecting Selection Signatures Using Population Genomics Data.J Comput Biol. 2022 Sep;29(9):943-960. doi: 10.1089/cmb.2021.0447. Epub 2022 May 30. J Comput Biol. 2022. PMID: 35639362 Review.
Cited by
-
On the use of generative models for evolutionary inference of malaria vectors from genomic data.bioRxiv [Preprint]. 2025 Jun 27:2025.06.26.661760. doi: 10.1101/2025.06.26.661760. bioRxiv. 2025. PMID: 40667127 Free PMC article. Preprint.
-
Genomic Anomaly Detection with Functional Data Analysis.Genes (Basel). 2025 Jun 15;16(6):710. doi: 10.3390/genes16060710. Genes (Basel). 2025. PMID: 40565602 Free PMC article.
References
-
- Abadi M, Agarwal A, Barham P, Brevdo E, Chen Z, Citro C, Corrado G, Davis A, Dean J, Devin M, et al. 2015. TensorFlow: large-scale machine learning on heterogeneous systems. Software available from tensorflow.org. https://www.tensorflow.org/.
-
- Alberts B, Johnson A, Lewis J, Raff M, Roberts K, Walter P. The cytoskeleton and cell behavior. In: Molecular biology of the cell. 4th ed. New York (NY): Garland Science; 2002.
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
