

An object detection model AAPW-YOLO for UAV remote sensing images based on adaptive convolution and reconstructed feature fusion
- PMID: 40346071
- PMCID: PMC12064822
- DOI: 10.1038/s41598-025-00239-4
An object detection model AAPW-YOLO for UAV remote sensing images based on adaptive convolution and reconstructed feature fusion
Abstract
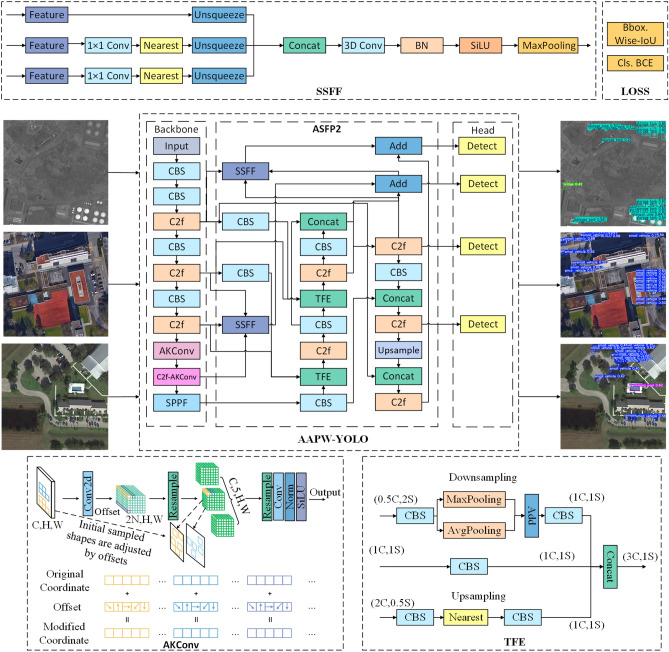
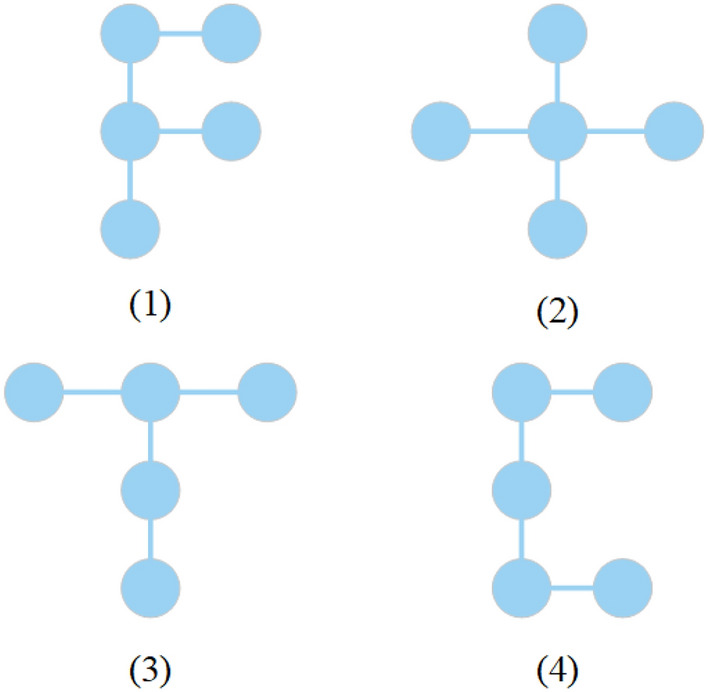
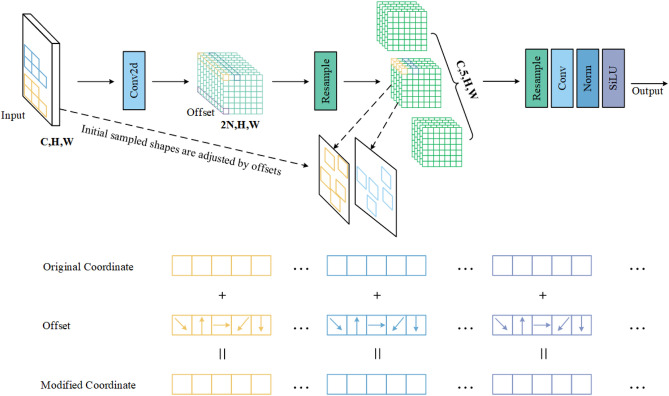
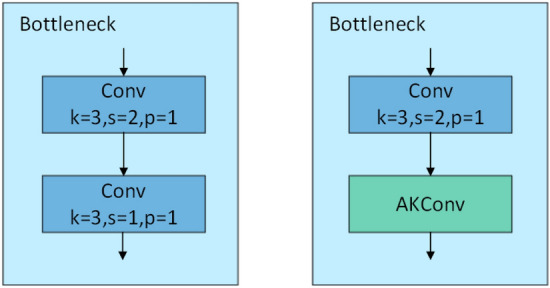
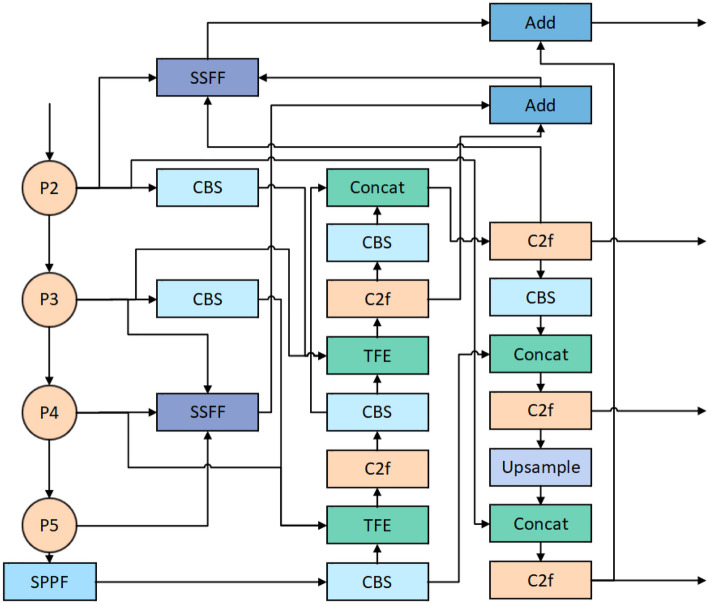
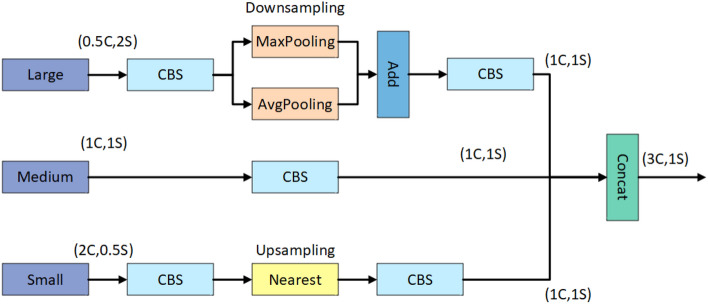
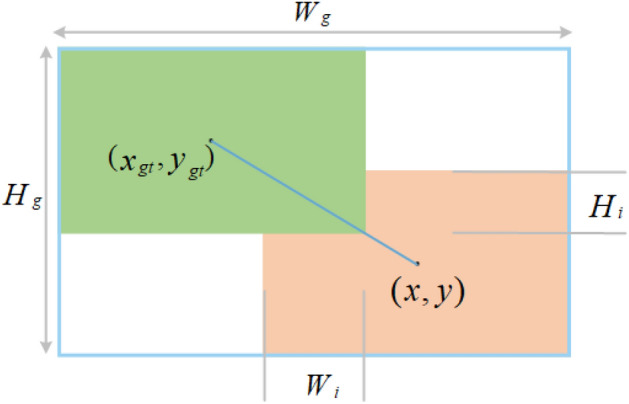
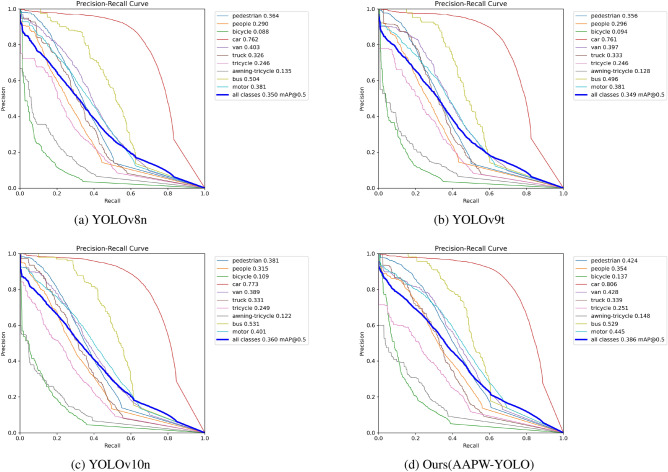
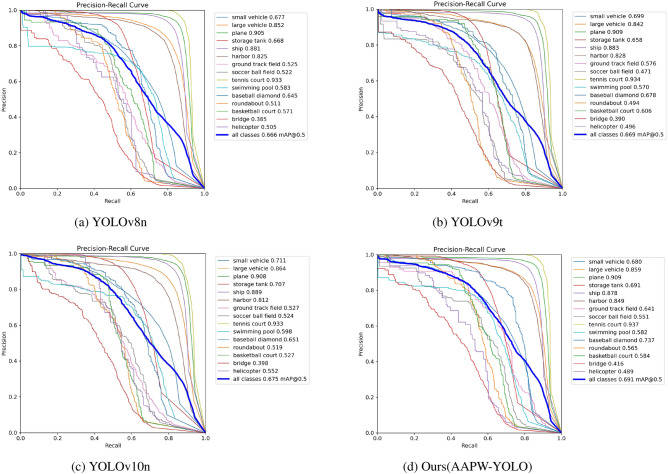
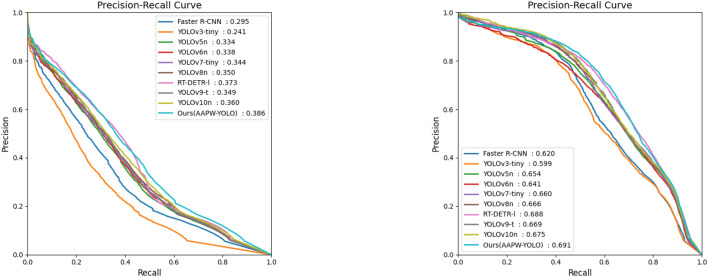
In small object detection scenarios such as UAV aerial imagery and remote sensing, the difficulties in feature extraction are primarily due to challenges such as small object size, multi-scale variations, and background interference. To overcome these challenges, this paper presents a model for detecting small objects, AAPW-YOLO, based on adaptive convolution and reconstructed feature fusion. In the AAPW-YOLO model, we improve the standard convolution and the CSP Bottleneck with 2 Convolutions (C2f) structure in the You Only Look Once v8 (YOLOv8) backbone network by using Alterable Kernel Convolution (AKConv), which improves the network's proficiency in capturing features across various scales while considerably lowering the model's parameter count. Additionally, we introduce the Attentional Scale Sequence Fusion P2 (ASFP2) structure, which enhances the feature fusion mechanism of the Attentional Scale Sequence Fusion You Only Look Once (ASF-YOLO) and incorporates a P2 detection layer. This optimizes the feature fusion mechanism in the YOLOv8 neck, enhancing the network's ability to capture both fine details and global contextual information, while additionally decreasing the model parameters. Finally, we adopt a gradient-enhancing strategy with the Wise Intersection over Union (Wise-IoU) loss function to balance the gradient contributions from anchor boxes of different qualities during training, thereby improving regression accuracy. Experimental results show that: The proposed detection model reduces the parameter count by 30% and improves mAP@0.5 by 3.6% on the VisDrone2019 dataset; On the DOTA v1.0 dataset, the parameter count is reduced by 30%, with a 2.5% improvement in mAP@0.5. The proposed model achieves high recognition accuracy while having fewer parameters, enhancing the robustness and generalization ability of the network.
Keywords: AKConv; Feature fusion mechanism; Small object detection; Wise-IoU; YOLOv8.
© 2025. The Author(s).
Conflict of interest statement
Declarations. Competing interests: The authors declare no competing interests.
Figures





References
-
- Sandler, M., Howard, A., Zhu, M., Zhmoginov, A. & Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 4510–4520 (2018).
-
- Ma, N., Zhang, X., Zheng, H.-T. & Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV). 116–131 (2018).
-
- Han, K. et al. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1580–1589 (2020).
-
- Tan, M. & Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In International Conference on Machine Learning. 6105–6114 (PMLR, 2019).
-
- Liu, C. et al. Yolc: You only look clusters for tiny object detection in aerial images. In IEEE Transactions on Intelligent Transportation Systems (2024).
Grants and funding
LinkOut - more resources
Full Text Sources
