

fNIRS experimental study on the impact of AI-synthesized familiar voices on brain neural responses
- PMID: 40374900
- PMCID: PMC12081930
- DOI: 10.1038/s41598-025-92702-5
fNIRS experimental study on the impact of AI-synthesized familiar voices on brain neural responses
Abstract
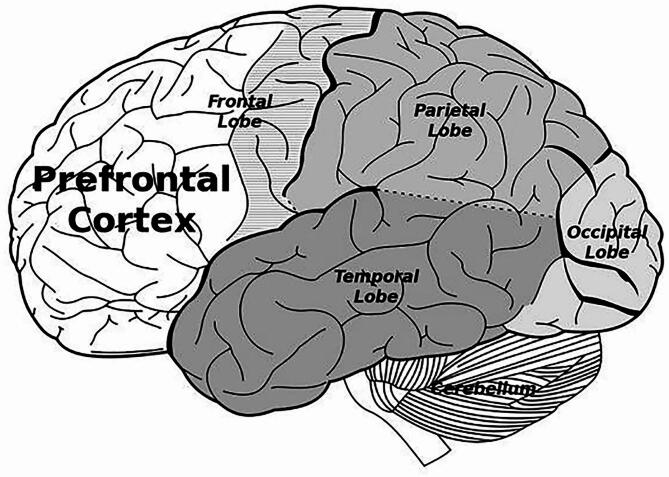
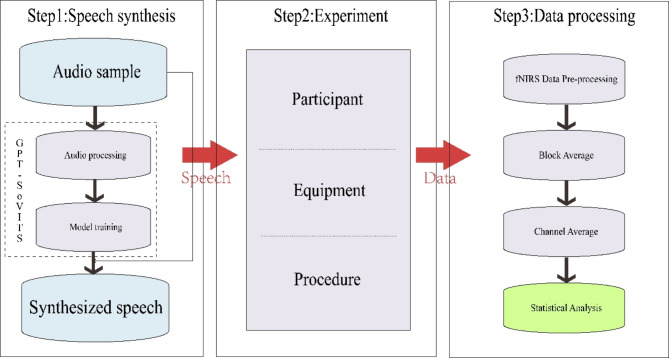
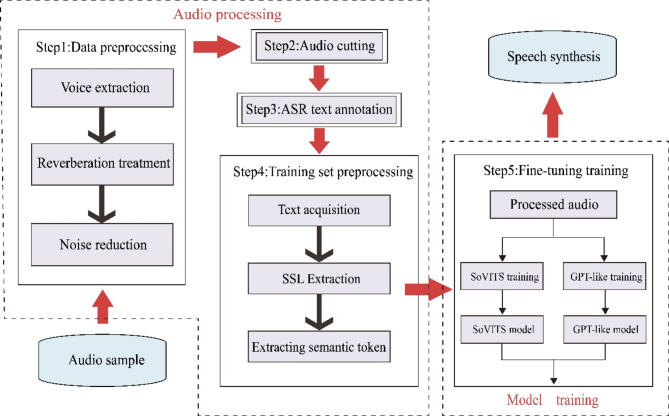
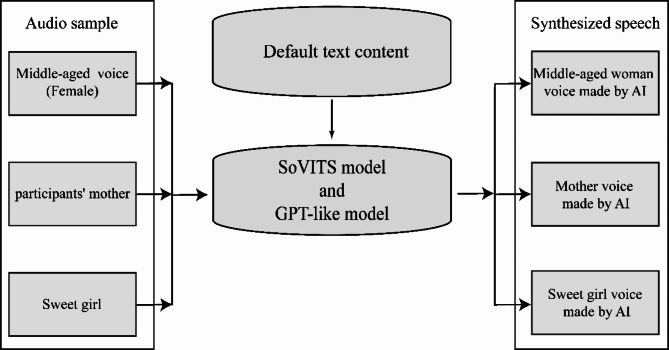
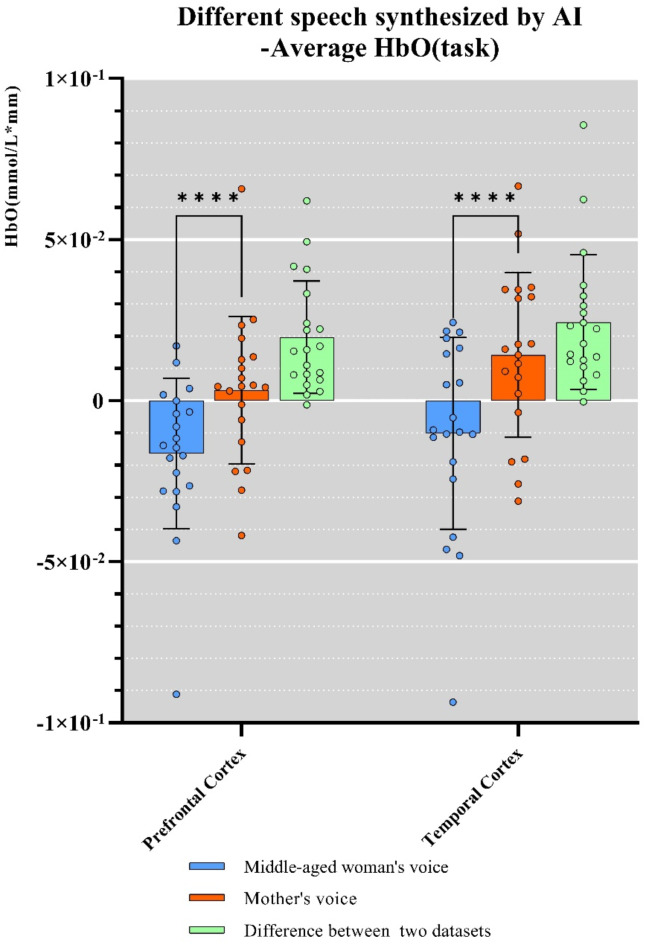
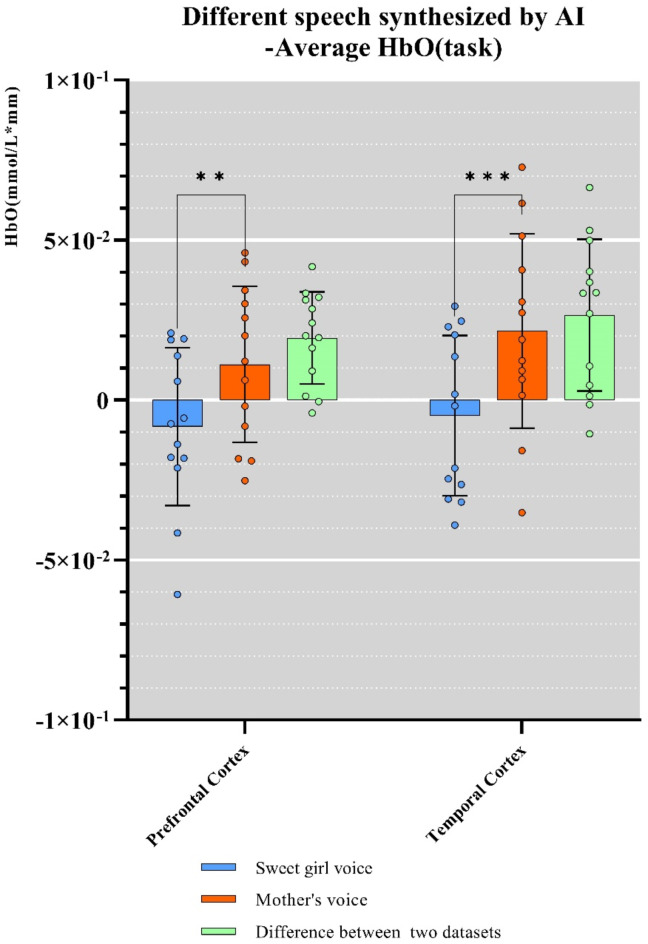
With the advancement of artificial intelligence (AI) speech synthesis technology, its application in personalized voice services and its potential role in emotional comfort have become research focal points. This study aims to explore the impact of AI-synthesized familiar and unfamiliar voices on neural responses in the brain. We utilized the GPT-SoVITS project to synthesize three types of voices: a female voice, a sweet female voice, and a maternal voice, all reading the same text. Using functional near-infrared spectroscopy (fNIRS), we monitored the changes in blood oxygen levels in the prefrontal cortex and temporal cortex of participants during listening, assessing brain activation. The experimental results showed that the AI-synthesized maternal voice significantly activated the participants' prefrontal and temporal cortices. Combined with participants' feedback, the activation of these areas may reflect multidimensional features of voice familiarity processing, including emotion, memory, and cognitive function. This finding reveals the potential applications of AI voice technology in enhancing mental health and user experience.
Keywords: Artificial intelligence; Human-computer interaction; Social impact of synthetic speech; Voice synthesis; fNIRS.
© 2025. The Author(s).
Conflict of interest statement
Declarations. Competing interests: The authors declare no competing interests.
Figures

Similar articles
-
Neural basis of language familiarity effects on voice recognition: An fNIRS study.Cortex. 2024 Jul;176:1-10. doi: 10.1016/j.cortex.2024.04.007. Epub 2024 Apr 30. Cortex. 2024. PMID: 38723449
-
fNIRS reveals enhanced brain activation to female (versus male) infant directed speech (relative to adult directed speech) in Young Human Infants.Infant Behav Dev. 2018 Aug;52:89-96. doi: 10.1016/j.infbeh.2018.05.009. Epub 2018 Jun 14. Infant Behav Dev. 2018. PMID: 29909251 Free PMC article.
-
Is the voice an auditory face? An ALE meta-analysis comparing vocal and facial emotion processing.Soc Cogn Affect Neurosci. 2018 Jan 1;13(1):1-13. doi: 10.1093/scan/nsx142. Soc Cogn Affect Neurosci. 2018. PMID: 29186621 Free PMC article.
-
Possible effect of natural light on emotion recognition and the prefrontal cortex: A scoping review of near-infrared (NIR) spectroscopy.Adv Clin Exp Med. 2023 Dec;32(12):1441-1451. doi: 10.17219/acem/162537. Adv Clin Exp Med. 2023. PMID: 37093092
-
A Review of Challenges in Speech-Based Conversational AI for Elderly Care.Stud Health Technol Inform. 2025 May 15;327:858-862. doi: 10.3233/SHTI250481. Stud Health Technol Inform. 2025. PMID: 40380589 Review.
References
-
- Wang, Y. et al. Tacotron: Towards End-to-End speech synthesis. (2017). https://ui.adsabs.harvard.edu/abs/2017arXiv170310135W
-
- Ren, Y. et al. FastSpeech: Fast, robust and controllable text to speech. (2019). https://ui.adsabs.harvard.edu/abs/2019arXiv190509263R
-
- Huang, S. F., Lin, C. J., Liu, D. R., Chen, Y. C. & Lee, H. y. Meta-TTS: Meta-learning for few-shot speaker adaptive text-to-speech. IEEE/ACM Trans. Audio Speech Lang. Process.30, 1558–1571. 10.1109/TASLP.2022.3167258 (2022).
-
- Dan, Q., Xukui, Y. & Honggang, Y. et al, Overview of recent progress in low-resource few-shot continuous speech recognition. J. Zhengzhou Univ. (Engineering Science)44, 1–9. 10.13705/j.issn.1671-6833.2023.04.014 (2023).
MeSH terms
LinkOut - more resources
Full Text Sources
