

The DRAGON benchmark for clinical NLP
- PMID: 40379835
- PMCID: PMC12084576
- DOI: 10.1038/s41746-025-01626-x
The DRAGON benchmark for clinical NLP
Abstract
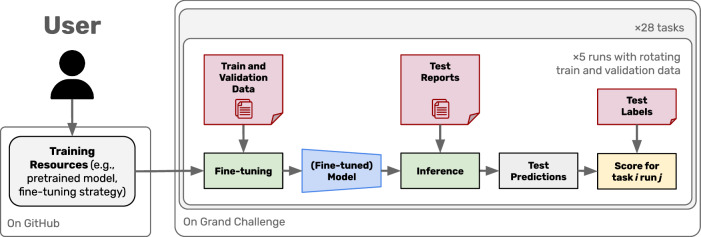
Artificial Intelligence can mitigate the global shortage of medical diagnostic personnel but requires large-scale annotated datasets to train clinical algorithms. Natural Language Processing (NLP), including Large Language Models (LLMs), shows great potential for annotating clinical data to facilitate algorithm development but remains underexplored due to a lack of public benchmarks. This study introduces the DRAGON challenge, a benchmark for clinical NLP with 28 tasks and 28,824 annotated medical reports from five Dutch care centers. It facilitates automated, large-scale, cost-effective data annotation. Foundational LLMs were pretrained using four million clinical reports from a sixth Dutch care center. Evaluations showed the superiority of domain-specific pretraining (DRAGON 2025 test score of 0.770) and mixed-domain pretraining (0.756), compared to general-domain pretraining (0.734, p < 0.005). While strong performance was achieved on 18/28 tasks, performance was subpar on 10/28 tasks, uncovering where innovations are needed. Benchmark, code, and foundational LLMs are publicly available.
© 2025. The Author(s).
Conflict of interest statement
Competing interests: A.S. has received lecture honorarium from Guerbet. F.C. has been Chair of the Scientific and Medical Advisory Board of TRIBVN Healthcare, received advisory board fees from TRIBVN Healthcare, and is shareholder in Aiosyn BV.
Figures



References
-
- Lång, K. et al. Artificial intelligence-supported screen reading versus standard double reading in the Mammography Screening with Artificial Intelligence trial (MASAI): a clinical safety analysis of a randomised, controlled, non-inferiority, single-blinded, screening accuracy study. Lancet Oncol.24, 936–944 (2023). - DOI - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources
